El mito, en una frase
El miedo que ha quitado más sueño a las pequeñas empresas que casi cualquier otra preocupación de SEO, y por qué está equivocado.
En algún momento, una leyenda del SEO se afianzó y nunca soltó su agarre: si Google encuentra contenido duplicado en tu sitio, te penalizará. Los dueños de negocios reescriben descripciones de producto presa del pánico, se niegan a republicar sus propios artículos y temen que dos páginas diciendo cosas parecidas hundan todo el dominio. Es uno de los mitos más persistentes de la búsqueda, y es falso.
Aquí está la verdad en una sola frase: no existe una “penalización por contenido duplicado” como la imagina la mayoría. Cuando Google encuentra páginas duplicadas o casi duplicadas, las agrupa, elige una versión para mostrar (la “canónica”) y oculta discretamente el resto. Tu posicionamiento no baja. Tu sitio no queda marcado. No se quita nada. El duplicado simplemente se filtra, no se castiga.
La idea que arregla todo el miedo
El mito del contenido duplicado, en números
Las propias estimaciones de Google y el umbral que nunca existió[6]
Fuente: Matt Cutts (Google, 2013) estimó que el 25–30% de la web es contenido duplicado; John Mueller confirmó que “no hay número” que active una penalización.[6]
Lo que Google dice realmente
Ni interpretación ni opinión de un gurú, las declaraciones públicas de la propia gente y los documentos de Google.
Este no es un caso en el que los expertos discrepan y tú tienes que elegir un bando. Google ha dicho lo mismo, en público, durante más de una década.
Allá por 2013, Matt Cutts, entonces jefe del equipo de webspam de Google, grabó un vídeo oficial abordando exactamente este miedo. Su estimación era llamativa: aproximadamente el 25–30% de todo el contenido de la web es duplicado. La gente cita un párrafo y enlaza a la fuente. Los sitios publican el mismo texto de términos de servicio. Los artículos se sindican. Como tanta de esta duplicación es inocente, explicó Cutts, penalizarla “tendría un efecto negativo en la calidad de los resultados de búsqueda.”[6] Google simplemente no funciona así.
John Mueller, el veterano Search Advocate de Google, ha repetido el punto muchas veces: “No tenemos una penalización por contenido duplicado.” Tan recientemente como en abril de 2026, Google confirmó que tener múltiples URLs apuntando al mismo contenido no activa una penalización ni una pérdida de visibilidad, el sistema puede gestionarlo.[8]
Y la documentación oficial elimina cualquier duda restante. Las propias páginas de ayuda de Google afirman llanamente que “algo de contenido duplicado en un sitio es normal y no es una violación de las políticas de spam de Google.”[1] Léelo de nuevo: no es una violación. Los mismos documentos que definen qué es spam excluyen explícitamente la duplicación normal como algo correcto.
Entonces, ¿por qué persiste el miedo?
Cómo funciona la canonicalización
El mecanismo detrás de ‘Google elige una versión’, y las tres señales que sí controlas.
La canonicalización es simplemente Google eligiendo la única URL “representante” de un conjunto de páginas duplicadas o muy similares. A veces se llama deduplicación, y su único trabajo es permitir a Google mostrar una versión limpia en los resultados en lugar de cinco casi idénticas. No hay nada punitivo en ello, es un paso de orden que le ocurre a casi todos los sitios de la web.
No estás indefenso en este proceso. La documentación de Google enumera las señales que usa para decidir qué URL gana, y útilmente las ordena por fuerza. La buena noticia para los dueños no técnicos: estas señales se acumulan, así que combinarlas aumenta la probabilidad de que tu página preferida sea la elegida.
Las tres señales de canonicalización que controlas
Ordenadas por fuerza, de los docs ‘Consolidar URLs duplicadas’ de Google[2]
Las barras son fuerza relativa de la señal, no porcentajes. Una redirección es la palanca más fuerte; un sitemap la más débil. Ninguna es obligatoria, Google dice que tu sitio “probablemente irá bien” sin especificar ninguna preferencia.[2]

Dos cosas merecen grabarse a fuego aquí. Primera, rel=“canonical” es una pista, no una orden. Google puede elegir una canónica distinta de la que especificaste según sus propias señales, que es exactamente por lo que Search Console a veces informa “Duplicada, Google eligió una canónica distinta de la del usuario.” Ese mensaje no es una penalización; es Google diciéndote que anuló tu pista.[1] Segunda, en realidad no tienes que hacer nada de esto. Si no especificas nada, Google elige la versión que juzga objetivamente mejor para mostrar a los usuarios.
- Apuntar la canónica a una página redirigida o no duplicada. El destino debe ser una URL viva y genuinamente equivalente.
- Enviar señales contradictorias. Tu sitemap dice URL A, tu rel=canonical dice URL B, Google tiene que adivinar, y puede equivocarse.
- Usar robots.txt para “canonicalizar.” Bloquear una URL puede dejarla indexada sin su contenido. Herramienta equivocada para el trabajo.
- Usar la herramienta de eliminación de URLs. Eso oculta todas las versiones, no solo la duplicada, una desaparición autoinfligida.
- Establecer la canónica vía JavaScript que cambia el valor. Si el valor renderizado difiere del HTML de origen, las señales se enturbian.
Fuentes: docs de solución de problemas de canonicalización de Google y la guía canónica de SEMrush.[3][12]
Agrupar, elegir, filtrar, no castigar
El proceso de cuatro pasos que Google describió igual en 2013 y 2020, el corazón del desmontaje del mito.
Si recuerdas un modelo de todo este artículo, que sea este. Tanto Matt Cutts (2013) como Gary Illyes (2020) han descrito el manejo de casi-duplicados de Google de la misma forma, y tiene cuatro pasos, ninguno de los cuales es “penalizar”.
Detectar
Google reduce cada página a un hash / checksum y los compara. Es una coincidencia de huella, no un porcentaje de similitud.
Agrupar
Todas las páginas coincidentes se agrupan en un único clúster de duplicados.
Elegir líder
Google elige una “página líder”, la canónica, para representar todo el clúster.
Filtrar
Los duplicados no elegidos se filtran de los resultados para mantenerlos limpios. Ocultos, no perjudicados.
La palabra crucial en el paso cuatro es filtrados. La página duplicada sigue existiendo; simplemente no aparece cuando una versión mejor y canónica ya cubre la misma consulta. Tu sitio no se arrastra hacia abajo, una URL se suprime en favor de otra del mismo clúster. Eso está a un mundo de distancia de una penalización, que degradaría activamente tu dominio.
Y fíjate en lo que falta en el paso de detección: un porcentaje. Existe la creencia tozuda de que debes mantener las páginas, digamos, “70% únicas” o arriesgarte a un flag. Cuando el consultor SEO Bill Hartzer preguntó a Mueller directamente si hay un porcentaje que represente el contenido duplicado, la respuesta fue tajante: “No hay número (¿además, cómo lo medirías?).”[6] Google compara checksums, no puntuaciones de similitud.
En 2026, Mueller expuso nueve escenarios que explican cómo Google decide que dos páginas son duplicadas o elige una sobre otra. Si Search Console dice “Google eligió una canónica distinta”, la causa casi siempre es técnica, arquitectura, renderizado o parámetros, no una penalización:
- Contenido exactamente duplicado en dos URLs.
- Duplicación sustancial en el contenido principal, aunque algunas partes difieran.
- Demasiado poco contenido único frente a una plantilla pesada (menú gigante, post diminuto).
- Patrones de parámetros de URL que Google infiere como duplicados (p. ej. ?tmp=1234).
- Se usa una versión móvil para la comparación en lugar de la de escritorio.
- Solo se juzga la versión visible para Googlebot, no lo que ven los usuarios.
- Páginas de desafío de bots o de error servidas a Googlebot se emparejan como duplicados.
- JavaScript que no se renderiza, dejando un HTML inicial idéntico.
- Ambigüedad del sistema o simple clasificación errónea, ocurre.
Como dijo Mueller: “No hay herramienta que te diga por qué algo se consideró duplicado.” Fuente: SEJ, 2026.[7]
La sindicación, dejar que otros sitios republiquen tus artículos, es donde la conversación sobre contenido duplicado se vuelve genuinamente práctica, y donde mucho consejo está ahora desfasado. Durante años, la recomendación estándar era: que tus socios de sindicación añadan un rel=canonical apuntando a tu original, para que conserves el crédito. En 2023, Google revirtió ese consejo.
El giro de la sindicación en 2023
Google cambió el arreglo recomendado para el contenido republicado[9][10]
“Añade rel=canonical (o bloquea) para que el original reciba el crédito.”
Canonical NO se recomienda para sindicación, los socios deberían aplicar noindex a la copia republicada.
La documentación de Google ahora afirma que el elemento de enlace canónico no se recomienda para evitar la duplicación por sindicación, “porque las páginas suelen ser muy diferentes.” La solución más efectiva, dice, es que los socios bloqueen la indexación de la copia republicada.[3] En la práctica eso significa pedir a tus socios de sindicación que apliquen una etiqueta noindex a su versión, para que tu original sea el que posicione. Para Google News en concreto, noindex fue siempre el consejo, nunca canonical.[9]
¿Por qué el cambio? Porque las canónicas no estaban haciendo el trabajo de forma fiable. En julio de 2023, los datos de NewzDash mostraron que las copias sindicadas de Yahoo News de artículos de editores frecuentemente superaban en posición a los editores originales en Google. La palanca que los editores sí controlan es noindex en la copia del socio, así que eso es lo que Google recomienda ahora.[9]
La regla práctica para pequeñas empresas
Hay un punto más profundo escondido en todo esto. El miedo que este artículo desmonta es en realidad el miedo a reutilizar tu propio material, entre páginas, entre sitios, entre idiomas. Una vez que aceptas que Google agrupa y canonicaliza en lugar de penalizar los casi-duplicados, el verdadero cuello de botella deja de ser “¿me penalizarán?” y se convierte en el trabajo real: reelaborar inteligentemente el material de origen en algo que se lea como genuinamente original en lugar de copiado y pegado. Esa distinción, entre republicar el mismo bloque de texto y reescribirlo en un artículo distinto y con voz consistente, es exactamente la línea entre lo que Google filtra y lo que recompensa.
Dónde viven las penalizaciones reales
El contenido duplicado es tarea de orden. El scraping, el spam y el engaño son donde se reparten las acciones manuales.
Entonces, si la duplicación normal está bien, ¿qué sí hace que un sitio sea penalizado? Esta es la distinción que más importa, porque la misma palabra, “duplicado”, se sienta a ambos lados de una línea muy nítida. A un lado: duplicación normal, accidental y estructural. Al otro: copia deliberada diseñada para manipular el posicionamiento. La intención y el valor son lo que acciona el interruptor.
✓ Sin penalización, Google solo deduplica
Google elige HTTPS y consolida las señales. Sin penalización.
Tratadas como duplicados de una sola página, deduplicadas automáticamente.
Variantes normales de funcionalidad del sitio. Se muestra una versión.
Reconocidos como el mismo contenido; se elige una canónica.
Esperadas en ecommerce. Se filtran, nunca se penalizan.
Solapamiento inocente, Cutts: cerca de un tercio de la web lo hace.
“Contenido completamente diferente”, no es duplicado en absoluto.
✕ Penalización real, violaciones de la política de spam
Republicar el trabajo ajeno con poco valor añadido. Viola la política de spam.
Producir páginas en masa principalmente para manipular el posicionamiento.
Alojar páginas de terceros en un dominio de confianza para explotar sus señales de ranking.
Páginas hechas para motores, no para personas; mostrar a Google contenido distinto.
Plantillas de afiliados copiadas y pegadas sin valor original.
Comportamiento engañoso que provoca acciones manuales.
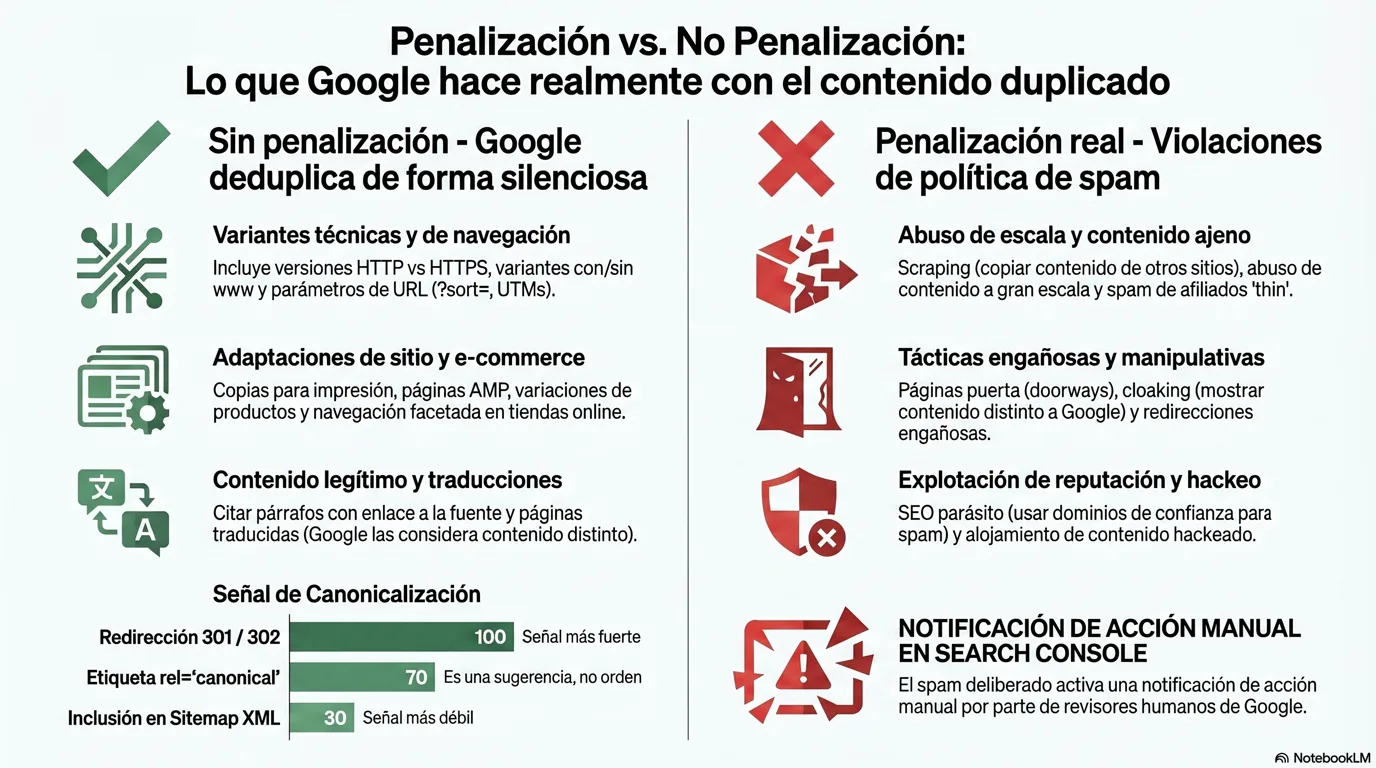
Las políticas de spam de Google prohíben explícitamente el scraping, el abuso de contenido a escala, el abuso de reputación del sitio, el cloaking, las páginas puerta y el spam de afiliación pobre, y estos sí pueden hacer que posiciones más bajo o que te eliminen por completo.[4] Las penalizaciones se entregan como acciones manuales: un revisor humano (o un sistema automatizado) marca la violación, tu sitio puede posicionar más bajo o desaparecer de los resultados, y se te notifica en Search Console con la posibilidad de presentar una solicitud de reconsideración. Esa notificación es la pista. Una penalización real viene con un mensaje; la deduplicación normal es silenciosa.
Un ejemplo concreto y fechado hace la línea vívida. La política de abuso de reputación del sitio de Google, a veces llamada “parasite SEO”, se lanzó con la actualización core de marzo de 2024, y las primeras acciones manuales llegaron a principios de mayo de 2024, golpeando dominios de grandes marcas que alojaban secciones de cupones y descuentos de terceros construidas puramente para explotar la autoridad del host. Google endureció aún más el lenguaje de la política el 19 de noviembre de 2024, dejando claro que usar contenido de terceros para explotar las señales de ranking de un sitio es una violación “independientemente de si hay participación de primera parte.”[5] Así es como se ve una penalización real adyacente al duplicado: deliberada, manipuladora y explícitamente contra las reglas, nada parecido a tener una versión http y una https de tu página de inicio.
Tipos comunes de duplicado, qué hace Google realmente
La mayoría de lo que preocupa a los dueños está firmemente en la columna ‘seguro’
| Tipo de duplicado | Ejemplo | Qué hace Google | Veredicto |
|---|---|---|---|
| Variantes de protocolo / host | http:// vs https://, www vs no-www | Google consolida en una canónica (prefiere HTTPS). Añade una redirección para ser explícito. | Seguro |
| Parámetros de URL | ?utm_source=, ?sort=price, ?sessionid= | Detectados como el mismo contenido; se elige una URL. Pon una canónica auto-referenciada. | Seguro |
| Variaciones de ecommerce | El mismo producto en rojo / azul / XL | Casi-duplicados agrupados; la canónica apunta a una URL principal de producto. | Seguro |
| Páginas con mucho boilerplate | Nav/footer enorme, cuerpo único diminuto | Puede juzgarse ‘poco contenido único’, añade sustancia, no solo reordenes. | Vigilar |
| Sindicado / republicado | Un socio republica tu artículo textualmente | Pide al socio que aplique noindex a la copia (guía de 2023) para que tu original posicione. | Vigilar |
| Scrapeado sin permiso | Alguien copia tu contenido para manipular el ranking | Esta es la zona de la política de spam, el scraper arriesga una acción manual, no tú. | Vigilar |
Contenido traducido y búsqueda con IA
Dos ansiedades modernas, páginas multilingües y AI Overviews, respondidas directamente.
Dos preguntas surgen constantemente de dueños que amplían su alcance, y ambas merecen una respuesta clara.
¿Es una página traducida contenido duplicado? No, ni de lejos. La documentación de Google es explícita: las versiones en distintos idiomas de una página solo se consideran duplicados si el contenido principal se mantiene en el mismo idioma (por ejemplo, si traduces solo el encabezado y el pie pero dejas el cuerpo en inglés). Un cuerpo genuinamente traducido no es duplicado. Mueller lo dijo aún más llanamente: “Todo lo que está traducido es contenido completamente diferente.” Desde el punto de vista de Google, la duplicación solo existe cuando las páginas coinciden físicamente, palabras y todo.[11] Una versión en español de tu artículo en inglés es una página separada y valiosa. La configuración correcta es hreflang por página entre las versiones de idioma, y confirmar que cada una está indexada en Search Console.
Por qué esto importa más en la era de la búsqueda con IA
Esto reenmarca todo el tema para la web moderna. El viejo miedo era defensivo, “¿me perjudicará la duplicación?” La nueva pregunta, más útil, es ofensiva: “¿soy la versión más clara, original y mejor consolidada de este contenido?” En un mundo de búsqueda mediada por IA, eso es lo que vale la pena optimizar.
Tu plan de acción
Deja de preocuparte por una penalización fantasma. Haz estas cinco cosas en su lugar.
El contenido duplicado normal, variantes, parámetros, opciones de ecommerce, boilerplate reutilizado, es normal y no es una violación de spam. Redirige tu energía a las dos cosas que sí importan abajo.
Usa redirecciones 301 para variantes de protocolo/host, canónicas auto-referenciadas en páginas con parámetros, y enlazado interno consistente. No envíes señales contradictorias entre tu sitemap y tus canónicas.
Si los socios republican tu trabajo, pídeles que apliquen noindex a su copia (guía post-2023). Si republicas contenido de otros, pon noindex al tuyo salvo que hayas añadido valor original real.
Aquí es donde viven las penalizaciones reales por acción manual. No produzcas en masa páginas pobres, no alojes contenido parásito de terceros por señales de ranking, y no republiques el trabajo ajeno sin añadir valor.
Las páginas traducidas son contenido distinto. Usa hreflang, verifica la indexación, y apuesta por el alcance multilingüe, expande tu huella con cero riesgo de contenido duplicado.
El verdadero cuello de botella, y dónde ayuda un motor de contenido
La penalización por contenido duplicado es una historia de fantasmas. Ha asustado a los dueños de pequeñas empresas durante años, ha dejado buen contenido sin publicar y ha convertido tareas técnicas rutinarias en una fuente de pavor. La realidad es mucho más amable: Google agrupa, elige un líder y filtra el resto, silenciosamente, automáticamente, sin malicia. Guarda tu preocupación para las cosas que sí llevan una penalización, scraping, spam y engaño, y gasta la energía que recuperas en hacer que tu contenido sea la mejor versión, la más original, de sí mismo.