Il mito, in una frase
La paura che ha tolto più sonno alle piccole imprese di quasi ogni altra preoccupazione SEO, e perché è mal riposta.
A un certo punto, una leggenda SEO si è radicata e non ha più mollato la presa: se Google trova contenuti duplicati sul tuo sito, ti penalizzerà. Gli imprenditori riscrivono le descrizioni dei prodotti nel panico, si rifiutano di ripubblicare i propri articoli e temono che due pagine che dicono cose simili affondino l’intero dominio. È uno dei miti più persistenti della ricerca, ed è falso.
Ecco la verità in una sola frase: non esiste una “penalizzazione per contenuti duplicati” come la immagina la maggior parte. Quando Google trova pagine duplicate o quasi duplicate, le raggruppa, sceglie una versione da mostrare (la “canonica”) e nasconde silenziosamente il resto. Il tuo posizionamento non cala. Il tuo sito non viene segnalato. Non viene tolto nulla. Il duplicato viene semplicemente filtrato, non punito.
L’unica idea che risolve tutta la paura
Il mito dei contenuti duplicati, in numeri
Le stime di Google stesso e la soglia che non è mai esistita[6]
Fonte: Matt Cutts (Google, 2013) stimava che il 25–30% del web sia contenuto duplicato; John Mueller ha confermato che “non esiste un numero” che attivi una penalizzazione.[6]
Cosa dice davvero Google
Né interpretazione, né opinione di un guru, le dichiarazioni pubbliche delle persone e dei documenti di Google stessi.
Questo non è un caso in cui gli esperti sono in disaccordo e devi scegliere una parte. Google dice la stessa cosa, in pubblico, da oltre un decennio.
Già nel 2013, Matt Cutts, allora a capo del team webspam di Google, registrò un video ufficiale che affrontava esattamente questa paura. La sua stima era sorprendente: circa il 25–30% di tutto il contenuto del web è duplicato. Le persone citano un paragrafo e linkano alla fonte. I siti pubblicano lo stesso testo di termini di servizio. Gli articoli vengono sindacati. Poiché gran parte di questa duplicazione è innocente, spiegò Cutts, penalizzarla “avrebbe un effetto negativo sulla qualità dei risultati di ricerca.”[6] Google semplicemente non funziona così.
John Mueller, il veterano Search Advocate di Google, ha ripetuto il punto molte volte: “Non abbiamo una penalizzazione per contenuti duplicati.” Ancora ad aprile 2026, Google ha confermato che avere più URL che puntano allo stesso contenuto non attiva una penalizzazione né una perdita di visibilità, il sistema sa gestirlo.[8]
E la documentazione ufficiale elimina ogni dubbio residuo. Le pagine di aiuto di Google affermano chiaramente che “un po’ di contenuto duplicato su un sito è normale e non è una violazione delle policy anti-spam di Google.”[1] Rileggi: non è una violazione. Gli stessi documenti che definiscono cosa è spam escludono esplicitamente la duplicazione ordinaria come accettabile.
Allora perché la paura persiste?
Come funziona la canonizzazione
Il meccanismo dietro ‘Google sceglie una versione’, e i tre segnali che controlli davvero.
La canonizzazione è semplicemente Google che sceglie l’unico URL “rappresentante” da un insieme di pagine duplicate o molto simili. A volte è chiamata deduplicazione, e il suo unico compito è permettere a Google di mostrare una versione pulita nei risultati invece di cinque quasi identiche. Non c’è nulla di punitivo, è un passaggio di riordino che capita a quasi tutti i siti del web.
Non sei impotente in questo processo. La documentazione di Google elenca i segnali che usa per decidere quale URL vince, e li ordina utilmente per forza. La buona notizia per i proprietari non tecnici: questi segnali si sommano, quindi combinarli aumenta la probabilità che la tua pagina preferita sia quella scelta.
I tre segnali di canonizzazione che controlli
Ordinati per forza, dai doc ‘Consolidare gli URL duplicati’ di Google[2]
Le barre indicano la forza relativa del segnale, non percentuali. Un reindirizzamento è la leva più forte; una sitemap la più debole. Nessuno è obbligatorio, Google dice che il tuo sito “probabilmente andrà benissimo” senza specificare alcuna preferenza.[2]

Due cose meritano di essere impresse a fuoco qui. Primo, rel=“canonical” è un suggerimento, non un comando. Google può scegliere una canonica diversa da quella che hai specificato in base ai propri segnali, ed è esattamente per questo che la Search Console a volte riporta “Duplicato, Google ha scelto una canonica diversa da quella dell’utente.” Quel messaggio non è una penalizzazione; è Google che ti dice che ha scavalcato il tuo suggerimento.[1] Secondo, in realtà non devi fare nulla di tutto questo. Se non specifichi nulla, Google sceglie la versione che giudica oggettivamente migliore da mostrare agli utenti.
- Puntare la canonica a una pagina reindirizzata o non duplicata. La destinazione deve essere un URL vivo e davvero equivalente.
- Inviare segnali contraddittori. La tua sitemap dice URL A, il tuo rel=canonical dice URL B, Google deve indovinare, e può indovinare male.
- Usare il robots.txt per “canonizzare.” Bloccare un URL può lasciarlo indicizzato senza il suo contenuto. Strumento sbagliato per il compito.
- Usare lo strumento di rimozione URL. Quello nasconde tutte le versioni, non solo il duplicato, una sparizione autoinflitta.
- Impostare la canonica via JavaScript che cambia il valore. Se il valore renderizzato differisce dall’HTML sorgente, i segnali diventano torbidi.
Fonti: doc di risoluzione dei problemi di canonizzazione di Google e la guida canonica di SEMrush.[3][12]
Raggruppare, scegliere, filtrare, non punire
Il processo in quattro fasi che Google ha descritto in modo identico nel 2013 e nel 2020, il cuore dello sfatamento del mito.
Se ricordi un solo modello di tutto questo articolo, che sia questo. Sia Matt Cutts (2013) sia Gary Illyes (2020) hanno descritto la gestione dei quasi-duplicati di Google allo stesso modo, e ha quattro fasi, nessuna delle quali è “penalizzare”.
Rilevare
Google riduce ogni pagina a un hash / checksum e li confronta. È una corrispondenza di impronta, non una percentuale di somiglianza.
Raggruppare
Tutte le pagine corrispondenti vengono raggruppate in un unico cluster di duplicati.
Scegliere un leader
Google sceglie una “pagina leader”, la canonica, per rappresentare l’intero cluster.
Filtrare
I duplicati non scelti vengono filtrati dai risultati per mantenerli puliti. Nascosti, non danneggiati.
La parola cruciale nella fase quattro è filtrati. La pagina duplicata esiste ancora; semplicemente non appare quando una versione migliore e canonica copre già la stessa query. Il tuo sito non viene trascinato giù, un URL viene soppresso a favore di un altro dello stesso cluster. È a mondi di distanza da una penalizzazione, che retrocederebbe attivamente il tuo dominio.
E nota cosa manca nella fase di rilevamento: una percentuale. C’è la credenza ostinata che si debbano tenere le pagine, diciamo, “uniche al 70%” o si rischia una segnalazione. Quando il consulente SEO Bill Hartzer ha chiesto direttamente a Mueller se esiste una percentuale che rappresenta il contenuto duplicato, la risposta è stata netta: “Non esiste un numero (e poi, come lo misureresti?).”[6] Google confronta i checksum, non i punteggi di somiglianza.
Nel 2026, Mueller ha esposto nove scenari che spiegano come Google decide che due pagine sono duplicate o ne sceglie una sull’altra. Se la Search Console dice “Google ha scelto una canonica diversa”, la causa è quasi sempre tecnica, architettura, rendering o parametri, non una penalizzazione:
- Contenuto esattamente duplicato su due URL.
- Duplicazione sostanziale nel contenuto principale, anche se alcune parti differiscono.
- Troppo poco contenuto unico rispetto a un template pesante (menu gigante, post minuscolo).
- Pattern di parametri URL che Google deduce come duplicati (es. ?tmp=1234).
- Una versione mobile usata per il confronto invece di quella desktop.
- Viene giudicata solo la versione visibile a Googlebot, non ciò che vedono gli utenti.
- Pagine di challenge dei bot o di errore servite a Googlebot vengono abbinate come duplicati.
- JavaScript che non si renderizza, lasciando un HTML di bootstrap identico.
- Ambiguità del sistema o semplice errore di classificazione, succede.
Come ha detto Mueller: “Non esiste uno strumento che ti dica perché qualcosa è stato considerato duplicato.” Fonte: SEJ, 2026.[7]
La sindacazione, lasciare che altri siti ripubblichino i tuoi articoli, è il punto in cui la conversazione sui contenuti duplicati diventa davvero pratica, e dove molti consigli sono ormai datati. Per anni, la raccomandazione standard era: che i tuoi partner di sindacazione aggiungessero un rel=canonical che punta al tuo originale, così da mantenere il credito. Nel 2023, Google ha invertito quel consiglio.
L’inversione della sindacazione nel 2023
Google ha cambiato la soluzione raccomandata per i contenuti ripubblicati[9][10]
“Aggiungi rel=canonical (o blocca) affinché l’originale riceva il credito.”
Canonical NON è raccomandato per la sindacazione, i partner dovrebbero applicare noindex alla copia ripubblicata.
La documentazione di Google ora afferma che l’elemento link canonico non è raccomandato per evitare la duplicazione da sindacazione, “perché le pagine sono spesso molto diverse.” La soluzione più efficace, dice, è che i partner blocchino l’indicizzazione della copia ripubblicata.[3] In pratica significa chiedere ai tuoi partner di sindacazione di applicare un tag noindex alla loro versione, così che il tuo originale sia quello che si posiziona. Per Google News in particolare, noindex è sempre stato il consiglio, mai canonical.[9]
Perché il cambiamento? Perché le canoniche non stavano facendo il lavoro in modo affidabile. A luglio 2023, i dati di NewzDash hanno mostrato che le copie sindacate di Yahoo News di articoli di editori frequentemente superavano gli editori originali in Google. La leva che gli editori controllano davvero è noindex sulla copia del partner, quindi è ciò che Google raccomanda ora.[9]
La regola pratica per le piccole imprese
C’è un punto più profondo nascosto in tutto questo. La paura che questo articolo smonta è in realtà la paura di riutilizzare il proprio materiale, tra pagine, tra siti, tra lingue. Una volta accettato che Google raggruppa e canonizza invece di penalizzare i quasi-duplicati, il vero collo di bottiglia smette di essere “verrò penalizzato?” e diventa il lavoro vero: rielaborare intelligentemente il materiale sorgente in qualcosa che si legga come davvero originale invece che copiato e incollato. Quella distinzione, tra ripubblicare lo stesso blocco di testo e riscriverlo in un articolo distinto e con voce coerente, è esattamente la linea tra ciò che Google filtra e ciò che premia.
Dove vivono le penalizzazioni reali
Il contenuto duplicato è ordine. Lo scraping, lo spam e l’inganno sono dove vengono distribuite le azioni manuali.
Quindi, se la duplicazione ordinaria va bene, cosa fa penalizzare un sito? Questa è la distinzione che conta di più, perché la stessa parola, “duplicato”, sta su entrambi i lati di una linea molto netta. Da un lato: duplicazione normale, accidentale, strutturale. Dall’altro: copia deliberata progettata per manipolare il posizionamento. L’intenzione e il valore sono ciò che fa scattare l’interruttore.
✓ Nessuna penalizzazione, Google deduplica soltanto
Google sceglie HTTPS e consolida i segnali. Nessuna penalizzazione.
Trattate come duplicati di una sola pagina, deduplicate automaticamente.
Normali varianti di funzionalità del sito. Viene mostrata una versione.
Riconosciuti come lo stesso contenuto; viene scelta una canonica.
Attese nell’e-commerce. Filtrate, mai penalizzate.
Sovrapposizione innocente, Cutts: circa un terzo del web lo fa.
“Contenuto completamente diverso”, non è affatto un duplicato.
✕ Penalizzazione reale, violazioni della policy anti-spam
Ripubblicare il lavoro altrui con poco valore aggiunto. Viola la policy anti-spam.
Produrre pagine in massa soprattutto per manipolare il posizionamento.
Ospitare pagine di terzi su un dominio affidabile per sfruttarne i segnali di ranking.
Pagine fatte per i motori, non per le persone; mostrare a Google contenuti diversi.
Modelli di affiliazione copia-incollati senza valore originale.
Comportamento ingannevole che innesca azioni manuali.
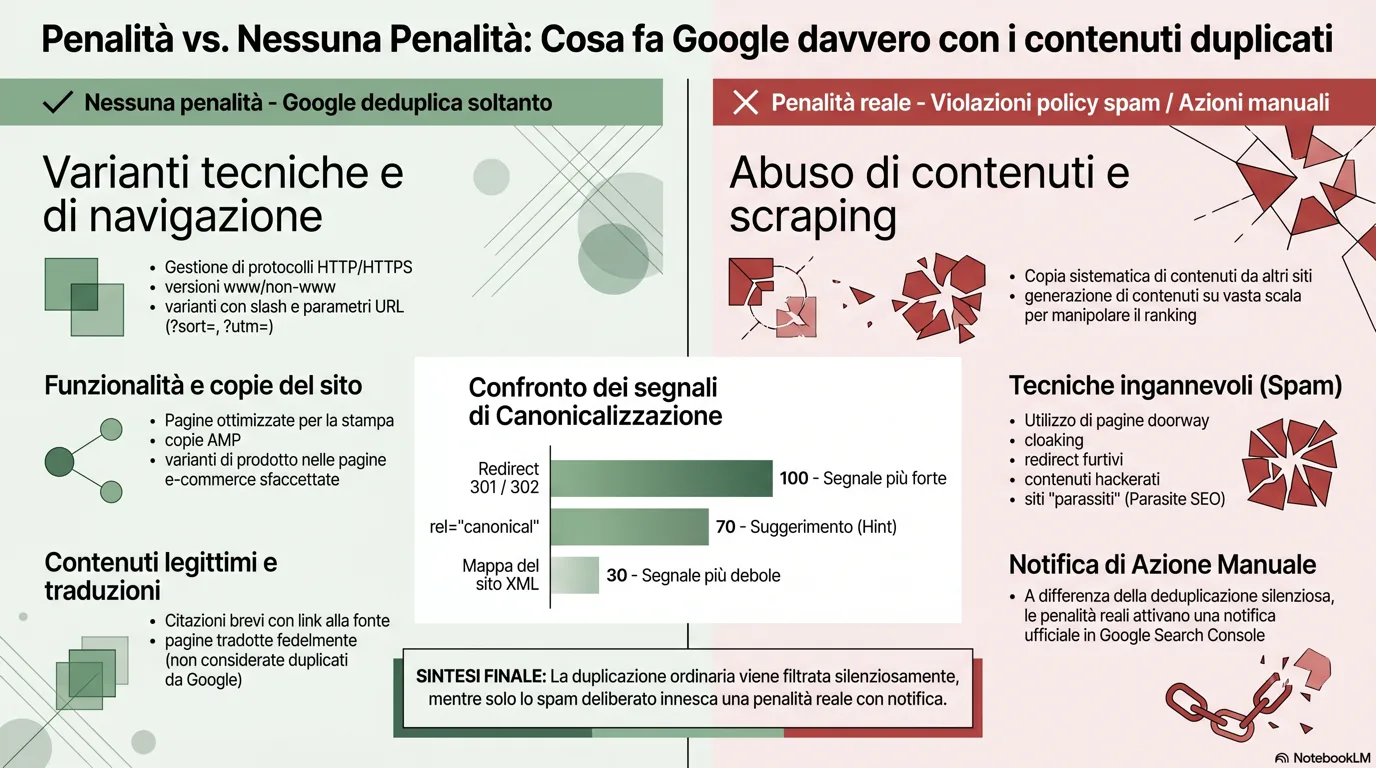
Le policy anti-spam di Google vietano esplicitamente lo scraping, l’abuso di contenuti su larga scala, l’abuso della reputazione del sito, il cloaking, le pagine doorway e lo spam di affiliazione povera, e questi possono farti posizionare più in basso o farti rimuovere del tutto.[4] Le penalizzazioni vengono consegnate come azioni manuali: un revisore umano (o un sistema automatizzato) segnala la violazione, il tuo sito può posizionarsi più in basso o sparire dai risultati, e vieni notificato nella Search Console con la possibilità di presentare una richiesta di riconsiderazione. Quella notifica è l’indizio. Una penalizzazione reale arriva con un messaggio; la deduplicazione ordinaria è silenziosa.
Un esempio concreto e datato rende la linea vivida. La policy sull’abuso della reputazione del sito di Google, a volte chiamata “parasite SEO”, è stata lanciata con l’aggiornamento core di marzo 2024, e le prime azioni manuali sono arrivate all’inizio di maggio 2024, colpendo domini di grandi marchi che ospitavano sezioni di coupon e sconti di terze parti costruite puramente per sfruttare l’autorità dell’host. Google ha ulteriormente inasprito il linguaggio della policy il 19 novembre 2024, chiarendo che usare contenuti di terzi per sfruttare i segnali di ranking di un sito è una violazione “indipendentemente dal fatto che vi sia un coinvolgimento di prima parte.”[5] Ecco come appare una penalizzazione reale adiacente al duplicato: deliberata, manipolativa ed esplicitamente contro le regole, niente a che vedere con l’avere una versione http e una https della tua homepage.
Tipi comuni di duplicati, cosa fa davvero Google
La maggior parte di ciò che preoccupa i proprietari sta saldamente nella colonna ‘sicuro’
| Tipo di duplicato | Esempio | Cosa fa Google | Verdetto |
|---|---|---|---|
| Varianti di protocollo / host | http:// vs https://, www vs non-www | Google consolida in una canonica (preferisce HTTPS). Aggiungi un reindirizzamento per essere esplicito. | Sicuro |
| Parametri URL | ?utm_source=, ?sort=price, ?sessionid= | Rilevati come lo stesso contenuto; viene scelto un URL. Imposta una canonica auto-referenziata. | Sicuro |
| Variazioni e-commerce | Lo stesso prodotto in rosso / blu / XL | Quasi-duplicati raggruppati; la canonica punta a un URL prodotto principale. | Sicuro |
| Pagine con molto boilerplate | Nav/footer enorme, corpo unico minuscolo | Può essere giudicata ‘troppo poco contenuto unico’, aggiungi sostanza, non riordinare soltanto. | Da osservare |
| Sindacato / ripubblicato | Un partner ripubblica il tuo articolo alla lettera | Chiedi al partner di applicare noindex alla copia (linea guida 2023) affinché il tuo originale si posizioni. | Da osservare |
| Copiato senza permesso | Qualcuno copia il tuo contenuto per manipolare il ranking | Questa è la zona della policy anti-spam, lo scraper rischia un’azione manuale, non tu. | Da osservare |
Contenuti tradotti e ricerca con IA
Due ansie moderne, pagine multilingue e AI Overviews, affrontate direttamente.
Due domande emergono costantemente da proprietari che ampliano la propria portata, ed entrambe meritano una risposta chiara.
Una pagina tradotta è contenuto duplicato? No, nemmeno lontanamente. La documentazione di Google è esplicita: le versioni in lingue diverse di una pagina sono considerate duplicati solo se il contenuto principale resta nella stessa lingua (per esempio, se traduci solo l’intestazione e il piè di pagina ma lasci il corpo in inglese). Un corpo genuinamente tradotto non è un duplicato. Mueller lo ha detto in modo ancora più netto: “Tutto ciò che è tradotto è contenuto completamente diverso.” Dal punto di vista di Google, la duplicazione esiste solo quando le pagine corrispondono fisicamente, parole comprese.[11] Una versione italiana del tuo articolo inglese è una pagina separata e di valore. La configurazione corretta è hreflang per pagina tra le versioni linguistiche, e confermare che ciascuna sia indicizzata nella Search Console.
Perché questo conta di più nell’era della ricerca con IA
Questo riformula l’intero tema per il web moderno. La vecchia paura era difensiva, “la duplicazione mi danneggerà?” La nuova domanda, più utile, è offensiva: “sono la versione più chiara, originale e meglio consolidata di questo contenuto?” In un mondo di ricerca mediata dall’IA, è questo che vale la pena ottimizzare.
Il tuo piano d’azione
Smetti di preoccuparti per una penalizzazione fantasma. Fai invece queste cinque cose.
Il contenuto duplicato ordinario, varianti, parametri, opzioni e-commerce, boilerplate riutilizzato, è normale e non è una violazione di spam. Reindirizza la tua energia verso le due cose che contano davvero qui sotto.
Usa reindirizzamenti 301 per le varianti di protocollo/host, canoniche auto-referenziate sulle pagine con parametri, e link interni coerenti. Non inviare segnali contraddittori tra la tua sitemap e le tue canoniche.
Se i partner ripubblicano il tuo lavoro, chiedi loro di applicare noindex alla loro copia (linea guida post-2023). Se ripubblichi il contenuto di altri, metti noindex al tuo a meno che tu non abbia aggiunto valore originale reale.
È qui che vivono le penalizzazioni reali per azione manuale. Non produrre in massa pagine povere, non ospitare contenuti parassiti di terzi per segnali di ranking, e non ripubblicare il lavoro altrui senza aggiungere valore.
Le pagine tradotte sono contenuti distinti. Usa hreflang, verifica l’indicizzazione, e punta sulla portata multilingue, espande la tua impronta con zero rischio di contenuti duplicati.
Il vero collo di bottiglia, e dove aiuta un motore di contenuti
La penalizzazione per contenuti duplicati è una storia di fantasmi. Ha spaventato i proprietari di piccole imprese per anni, ha lasciato del buon contenuto non pubblicato e ha trasformato la manutenzione tecnica di routine in una fonte di terrore. La realtà è molto più clemente: Google raggruppa, sceglie un leader e filtra il resto, silenziosamente, automaticamente, senza malizia. Conserva la tua preoccupazione per le cose che comportano davvero una penalizzazione, scraping, spam e inganno, e spendi l’energia recuperata per rendere il tuo contenuto la migliore versione, la più originale, di se stesso.