Le mythe, en une phrase
La peur qui a coûté plus de nuits blanches aux petites entreprises que presque toute autre inquiétude SEO, et pourquoi elle est mal placée.
Quelque part en chemin, une légende du SEO s’est installée et n’a jamais lâché prise : si Google trouve du contenu dupliqué sur votre site, il vous pénalisera. Les dirigeants réécrivent des fiches produit dans la panique, refusent de republier leurs propres articles, et craignent que deux pages disant des choses similaires fassent couler tout le domaine. C’est l’un des mythes les plus tenaces de la recherche, et il est faux.
Voici la vérité en une seule phrase : il n’existe pas de “pénalité pour contenu dupliqué” telle que la plupart l’imaginent. Lorsque Google trouve des pages dupliquées ou quasi identiques, il les regroupe, choisit une version à afficher (la “canonique”) et masque discrètement les autres. Votre classement ne baisse pas. Votre site n’est pas signalé. Rien n’est retiré. Le doublon est simplement filtré, pas puni.
L’idée qui dissipe toute la peur
Le mythe du contenu dupliqué, en chiffres
Les estimations de Google lui-même et le seuil qui n’a jamais existé[6]
Source : Matt Cutts (Google, 2013) estimait que 25–30% du web est du contenu dupliqué ; John Mueller a confirmé qu’il n’y a “aucun nombre” déclenchant une pénalité.[6]
Ce que Google dit vraiment
Ni interprétation, ni avis d’un gourou, les déclarations publiques des employés et de la documentation de Google.
Ce n’est pas un cas où les experts ne sont pas d’accord et où vous devez choisir un camp. Google dit la même chose, publiquement, depuis plus d’une décennie.
En 2013 déjà, Matt Cutts, alors responsable de l’équipe webspam de Google, a enregistré une vidéo officielle traitant exactement de cette peur. Son estimation était frappante : environ 25–30% de tout le contenu du web est dupliqué. Les gens citent un paragraphe et lient à la source. Les sites publient le même texte de conditions générales. Les articles sont syndiqués. Comme une grande partie de cette duplication est innocente, a expliqué Cutts, la pénaliser “aurait un effet négatif sur la qualité des résultats de recherche.”[6] Google ne fonctionne tout simplement pas ainsi.
John Mueller, le Search Advocate de longue date de Google, a répété ce point de nombreuses fois : “Nous n’avons pas de pénalité pour contenu dupliqué.” Aussi récemment qu’en avril 2026, Google a confirmé qu’avoir plusieurs URLs pointant vers le même contenu ne déclenche ni pénalité ni perte de visibilité, le système sait gérer.[8]
Et la documentation officielle lève tout doute restant. Les pages d’aide de Google indiquent clairement qu’“un peu de contenu dupliqué sur un site est normal et ce n’est pas une violation des règles anti-spam de Google.”[1] Relisez : pas une violation. Les mêmes documents qui définissent ce qu’est le spam excluent explicitement la duplication ordinaire comme étant acceptable.
Alors pourquoi la peur persiste-t-elle ?
Comment fonctionne la canonicalisation
Le mécanisme derrière ‘Google choisit une version’, et les trois signaux que vous gérez réellement.
La canonicalisation, c’est simplement Google choisissant l’unique URL “représentante” d’un ensemble de pages dupliquées ou très similaires. On l’appelle parfois déduplication, et son seul rôle est de permettre à Google d’afficher une version propre dans les résultats plutôt que cinq quasi identiques. Il n’y a rien de punitif là-dedans, c’est une étape de rangement qui arrive à presque tous les sites du web.
Vous n’êtes pas impuissant dans ce processus. La documentation de Google liste les signaux qu’il utilise pour décider quelle URL l’emporte, et les classe utilement par force. Bonne nouvelle pour les propriétaires non techniques : ces signaux se cumulent, donc les combiner augmente la chance que votre page préférée soit celle choisie.
Les trois signaux de canonicalisation que vous gérez
Classés par force, d’après les docs ‘Consolider les URLs en double’ de Google[2]
Les barres représentent la force relative du signal, pas des pourcentages. Une redirection est le levier le plus fort ; un sitemap le plus faible. Aucun n’est obligatoire, Google dit que votre site “s’en sortira probablement très bien” sans préciser de préférence.[2]

Deux choses méritent d’être gravées dans la mémoire ici. Premièrement, rel=“canonical” est un indice, pas un ordre. Google peut choisir une canonique différente de celle que vous avez indiquée selon ses propres signaux, c’est exactement pourquoi la Search Console signale parfois “En double, Google a choisi une canonique différente de l’utilisateur.” Ce message n’est pas une pénalité ; c’est Google qui vous dit qu’il a passé outre votre indice.[1] Deuxièmement, vous n’avez en réalité pas besoin de faire tout cela. Si vous ne précisez rien, Google choisit la version qu’il juge objectivement la meilleure à montrer aux utilisateurs.
- Pointer la canonique vers une page redirigée ou non dupliquée. La cible doit être une URL vivante et réellement équivalente.
- Envoyer des signaux contradictoires. Votre sitemap dit URL A, votre rel=canonical dit URL B, Google doit deviner, et peut se tromper.
- Utiliser robots.txt pour “canonicaliser.” Bloquer une URL peut la laisser indexée sans son contenu. Mauvais outil pour la tâche.
- Utiliser l’outil de suppression d’URL. Cela masque toutes les versions, pas seulement le doublon, une disparition auto-infligée.
- Définir la canonique via du JavaScript qui change la valeur. Si la valeur rendue diffère du HTML source, les signaux deviennent troubles.
Sources : docs de dépannage de canonicalisation de Google et guide canonique de SEMrush.[3][12]
Regrouper, choisir, filtrer, pas punir
Le processus en quatre étapes que Google a décrit à l’identique en 2013 et 2020, le cœur du démontage du mythe.
Si vous ne retenez qu’un modèle de tout cet article, que ce soit celui-ci. Matt Cutts (2013) comme Gary Illyes (2020) ont décrit la gestion des quasi-doublons de Google de la même façon, et elle compte quatre étapes, dont aucune n’est “pénaliser”.
Détecter
Google réduit chaque page à un hash / checksum et les compare. C’est une correspondance d’empreinte, pas un pourcentage de similarité.
Regrouper
Toutes les pages correspondantes sont regroupées en une seule grappe de doublons.
Choisir un leader
Google choisit une “page leader”, la canonique, pour représenter toute la grappe.
Filtrer
Les doublons non choisis sont filtrés des résultats pour les garder propres. Masqués, pas lésés.
Le mot crucial de l’étape quatre est filtrés. La page dupliquée existe toujours ; elle n’apparaît simplement pas quand une meilleure version canonique couvre déjà la même requête. Votre site n’est pas tiré vers le bas, une URL est supprimée au profit d’une autre de la même grappe. C’est à des années-lumière d’une pénalité, qui rétrograderait activement votre domaine.
Et remarquez ce qui manque à l’étape de détection : un pourcentage. Il y a cette croyance tenace selon laquelle il faudrait garder les pages, disons, “70% uniques” sous peine d’un signalement. Quand le consultant SEO Bill Hartzer a demandé directement à Mueller s’il existe un pourcentage représentant le contenu dupliqué, la réponse fut sans détour : “Il n’y a aucun nombre (et comment le mesureriez-vous d’ailleurs ?).”[6] Google compare des checksums, pas des scores de similarité.
En 2026, Mueller a exposé neuf scénarios expliquant comment Google décide que deux pages sont des doublons ou en choisit une plutôt qu’une autre. Si la Search Console dit “Google a choisi une canonique différente”, la cause est presque toujours technique, architecture, rendu ou paramètres, pas une pénalité :
- Contenu exactement dupliqué sur deux URLs.
- Duplication substantielle du contenu principal, même si certaines parties diffèrent.
- Trop peu de contenu unique face à un gabarit lourd (menu géant, article minuscule).
- Schémas de paramètres d’URL que Google infère comme des doublons (ex. ?tmp=1234).
- Une version mobile utilisée pour la comparaison au lieu du bureau.
- Seule la version visible par Googlebot est jugée, pas ce que voient les utilisateurs.
- Pages de défi de bots ou d’erreur servies à Googlebot, appariées comme doublons.
- JavaScript qui ne se rend pas, laissant un HTML d’amorçage identique.
- Ambiguïté du système ou simple erreur de classification, cela arrive.
Comme l’a dit Mueller : “Il n’existe aucun outil qui vous dise pourquoi quelque chose a été considéré comme dupliqué.” Source : SEJ, 2026.[7]
La syndication, laisser d’autres sites republier vos articles, est l’endroit où la conversation sur le contenu dupliqué devient vraiment concrète, et où beaucoup de conseils sont désormais périmés. Pendant des années, la recommandation standard était : que vos partenaires de syndication ajoutent un rel=canonical pointant vers votre original, pour que vous gardiez le crédit. En 2023, Google a inversé ce conseil.
Le revirement de la syndication en 2023
Google a changé la solution recommandée pour le contenu republié[9][10]
“Ajoutez rel=canonical (ou bloquez) pour que l’original obtienne le crédit.”
Canonical N’EST PAS recommandé pour la syndication, les partenaires devraient appliquer noindex à la copie republiée.
La documentation de Google indique désormais que l’élément de lien canonique n’est pas recommandé pour éviter la duplication par syndication, “parce que les pages sont souvent très différentes.” La solution la plus efficace, dit-il, est que les partenaires bloquent l’indexation de la copie republiée.[3] En pratique, cela signifie demander à vos partenaires de syndication d’appliquer une balise noindex à leur version, afin que votre original soit celui qui se classe. Pour Google News en particulier, noindex a toujours été le conseil, jamais canonical.[9]
Pourquoi ce changement ? Parce que les canoniques ne faisaient pas le travail de manière fiable. En juillet 2023, les données de NewzDash ont montré que les copies syndiquées de Yahoo News d’articles d’éditeurs surclassaient fréquemment les éditeurs originaux dans Google. Le levier que les éditeurs contrôlent réellement est noindex sur la copie du partenaire, c’est donc ce que Google recommande maintenant.[9]
La règle pratique pour les petites entreprises
Il y a un point plus profond caché dans tout cela. La peur que cet article démonte est en réalité la peur de réutiliser votre propre matériel, entre pages, entre sites, entre langues. Une fois que vous acceptez que Google regroupe et canonicalise plutôt que de pénaliser les quasi-doublons, le vrai goulot d’étranglement cesse d’être “vais-je être pénalisé ?” et devient le vrai travail : retravailler intelligemment le matériel source en quelque chose qui se lit comme réellement original plutôt que copié-collé. Cette distinction, entre republier le même bloc de texte et le réécrire en un article distinct et à la voix cohérente, est exactement la frontière entre ce que Google filtre et ce qu’il récompense.
Où vivent les vraies pénalités
Le contenu dupliqué, c’est du ménage. Le scraping, le spam et la tromperie, c’est là que les actions manuelles sont distribuées.
Alors, si la duplication ordinaire est acceptable, qu’est-ce qui fait pénaliser un site ? C’est la distinction qui compte le plus, car le même mot, “dupliqué”, se trouve des deux côtés d’une ligne très nette. D’un côté : la duplication normale, accidentelle, structurelle. De l’autre : la copie délibérée conçue pour manipuler le classement. L’intention et la valeur sont ce qui bascule l’interrupteur.
✓ Pas de pénalité, Google déduplique simplement
Google choisit HTTPS et consolide les signaux. Pas de pénalité.
Traitées comme des doublons d’une seule page, dédupliquées automatiquement.
Variantes normales de fonctionnalité du site. Une version est affichée.
Reconnus comme le même contenu ; une canonique est choisie.
Attendues en e-commerce. Filtrées, jamais pénalisées.
Chevauchement innocent, Cutts : près d’un tiers du web le fait.
“Contenu complètement différent”, pas du tout du duplicata.
✕ Vraie pénalité, violations des règles anti-spam
Republier le travail d’autrui avec peu de valeur ajoutée. Violation de la politique anti-spam.
Produire des pages en masse surtout pour manipuler le classement.
Héberger des pages tierces sur un domaine de confiance pour exploiter ses signaux de classement.
Pages conçues pour les moteurs, pas les gens ; montrer à Google un contenu différent.
Modèles d’affiliation copiés-collés sans valeur originale.
Comportement trompeur déclenchant des actions manuelles.
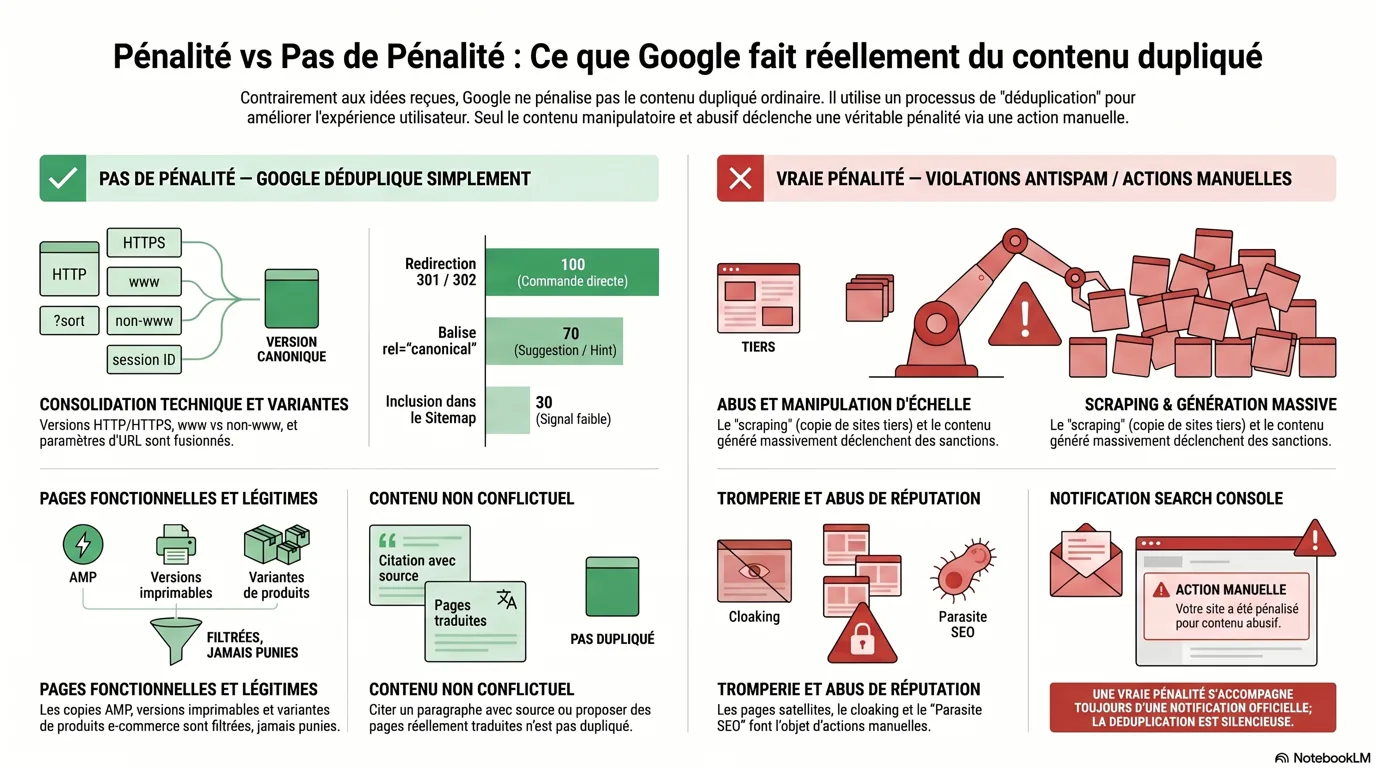
Les règles anti-spam de Google interdisent explicitement le scraping, l’abus de contenu à grande échelle, l’abus de réputation de site, le cloaking, les pages satellites et le spam d’affiliation pauvre, et ceux-là peuvent vous faire classer plus bas ou vous faire retirer entièrement.[4] Les pénalités sont délivrées sous forme d’actions manuelles : un évaluateur humain (ou un système automatisé) signale la violation, votre site peut se classer plus bas ou disparaître des résultats, et vous êtes notifié dans la Search Console avec la possibilité de déposer une demande de réexamen. Cette notification est l’indice. Une vraie pénalité vient avec un message ; la déduplication ordinaire est silencieuse.
Un exemple concret et daté rend la ligne vivante. La politique d’abus de réputation de site de Google, parfois appelée “parasite SEO”, a été lancée avec la mise à jour core de mars 2024, et les premières actions manuelles ont atterri début mai 2024, frappant des domaines de grandes marques qui hébergeaient des sections de coupons et de réductions de tiers construites uniquement pour exploiter l’autorité de l’hôte. Google a encore durci le langage de la politique le 19 novembre 2024, précisant qu’utiliser du contenu tiers pour exploiter les signaux de classement d’un site est une violation “indépendamment d’une éventuelle implication de première partie.”[5] Voilà à quoi ressemble une vraie pénalité adjacente au duplicata : délibérée, manipulatrice et explicitement contraire aux règles, rien à voir avec le fait d’avoir une version http et une version https de votre page d’accueil.
Types courants de doublons, ce que Google fait vraiment
La plupart de ce qui inquiète les propriétaires se trouve fermement dans la colonne ‘sûr’
| Type de doublon | Exemple | Ce que fait Google | Verdict |
|---|---|---|---|
| Variantes de protocole / hôte | http:// vs https://, www vs non-www | Google consolide vers une canonique (HTTPS préféré). Ajoutez une redirection pour être explicite. | Sûr |
| Paramètres d’URL | ?utm_source=, ?sort=price, ?sessionid= | Détectés comme le même contenu ; une URL est choisie. Posez une canonique auto-référente. | Sûr |
| Variations e-commerce | Le même produit en rouge / bleu / XL | Quasi-doublons regroupés ; la canonique pointe vers une URL produit principale. | Sûr |
| Pages très « boilerplate » | Nav/pied de page énorme, corps unique minuscule | Peut être jugée ‘trop peu de contenu unique’, ajoutez de la substance, ne réorganisez pas. | À surveiller |
| Syndiqué / republié | Un partenaire republie votre article mot pour mot | Demandez au partenaire d’appliquer noindex à la copie (guide 2023) pour que votre original se classe. | À surveiller |
| Scrapé sans permission | Quelqu’un copie votre contenu pour manipuler le classement | C’est la zone de la politique anti-spam, le scrapeur risque une action manuelle, pas vous. | À surveiller |
Contenu traduit et recherche IA
Deux angoisses modernes, pages multilingues et AI Overviews, résolues directement.
Deux questions reviennent constamment de la part de propriétaires qui élargissent leur portée, et toutes deux méritent une réponse claire.
Une page traduite est-elle du contenu dupliqué ? Non, loin de là. La documentation de Google est explicite : les versions en différentes langues d’une page ne sont considérées comme des doublons que si le contenu principal reste dans la même langue (par exemple, si vous ne traduisez que l’en-tête et le pied de page mais laissez le corps en anglais). Un corps réellement traduit n’est pas un doublon. Mueller l’a dit encore plus simplement : “Tout ce qui est traduit est un contenu complètement différent.” Du point de vue de Google, la duplication n’existe que lorsque les pages correspondent physiquement, mots compris.[11] Une version française de votre article anglais est une page distincte et précieuse. La bonne configuration est hreflang page par page entre les versions linguistiques, et confirmer que chacune est indexée dans la Search Console.
Pourquoi cela compte davantage à l’ère de la recherche IA
Cela recadre tout le sujet pour le web moderne. L’ancienne peur était défensive, “la duplication va-t-elle me nuire ?” La nouvelle question, plus utile, est offensive : “suis-je la version la plus claire, la plus originale et la mieux consolidée de ce contenu ?” Dans un monde de recherche médiée par l’IA, c’est cela qui vaut la peine d’être optimisé.
Votre plan d’action
Cessez de craindre une pénalité fantôme. Faites plutôt ces cinq choses.
Le contenu dupliqué ordinaire, variantes, paramètres, options e-commerce, boilerplate réutilisé, est normal et n’est pas une violation de spam. Réorientez votre énergie vers les deux choses qui comptent vraiment ci-dessous.
Utilisez des redirections 301 pour les variantes de protocole/hôte, des canoniques auto-référentes sur les pages à paramètres, et un maillage interne cohérent. N’envoyez pas de signaux contradictoires entre votre sitemap et vos canoniques.
Si des partenaires republient votre travail, demandez-leur d’appliquer noindex à leur copie (guide post-2023). Si vous republiez le contenu d’autrui, mettez le vôtre en noindex sauf si vous avez ajouté une réelle valeur originale.
C’est là que vivent les vraies pénalités par action manuelle. Ne produisez pas en masse des pages pauvres, n’hébergez pas de contenu parasite de tiers pour des signaux de classement, et ne republiez pas le travail d’autrui sans ajouter de valeur.
Les pages traduites sont du contenu distinct. Utilisez hreflang, vérifiez l’indexation, et misez sur la portée multilingue, elle élargit votre empreinte avec zéro risque de contenu dupliqué.
Le vrai goulot d’étranglement, et où un moteur de contenu aide
La pénalité pour contenu dupliqué est une histoire de fantômes. Elle a effrayé les dirigeants de petites entreprises pendant des années, gardé du bon contenu non publié, et transformé un entretien technique de routine en source d’angoisse. La réalité est bien plus clémente : Google regroupe, choisit un leader et filtre le reste, silencieusement, automatiquement, sans malice. Gardez votre inquiétude pour les choses qui entraînent réellement une pénalité, scraping, spam et tromperie, et consacrez l’énergie récupérée à faire de votre contenu la meilleure version, la plus originale, de lui-même.