Was eine agentische Content-Pipeline wirklich ist
Kein klügerer Prompt. Ein Fließband spezialisierter Agenten, jeder mit einer Aufgabe, die die Arbeit weiterreichen.
Die meisten begegnen KI-Schreiben als einer einzigen Box: Sie tippen eine Anfrage, sie tippt einen Artikel zurück. Das ist ein Prompt, der eine Aufgabe erledigt. Eine agentische Content-Pipeline ist etwas anderes. Sie ist eine Kette spezialisierter KI-Agenten, die einen Inhalt durch getrennte Phasen tragen, erst Recherche, dann Entwurf, dann Faktencheck, dann Übersetzung, dann Veröffentlichung, mit einer Orchestrierungsschicht obenauf, die die Übergaben koordiniert und Ausnahmen abfängt.[6] Denken Sie weniger an cleveres Autovervollständigen und mehr an ein kleines, automatisiertes Redaktionsteam, in dem jedes Mitglied eine Verantwortung hat und die Arbeit weitergibt, sobald sein Teil fertig ist.
Das entscheidende Wort ist agentisch. Ein gewöhnliches Sprachmodell wartet auf Anweisungen und antwortet einmal. Ein Agent bekommt ein Ziel, plant die Schritte, nutzt Tools wie Websuche oder eine Publishing-API, prüft seinen eigenen Fortschritt und entscheidet selbst über das Weitere, ohne bei jedem Schritt gefragt zu werden.[12] Verknüpfen Sie mehrere davon, geben Sie jedem einen engen Auftrag, und Sie haben eine Pipeline, die am einen Ende einen Themen-Brief entgegennimmt und am anderen einen fertigen, geprüften, übersetzten Beitrag liefert. Für ein kleines Unternehmen, das regelmäßig publiziert, ist das der Unterschied zwischen einem Tool, das man babysitten muss, und einem System, das läuft.
Die Definition in einem Satz
Das ist keine Randidee mehr. Gartner erwartet, dass 40% der Unternehmens-Apps bis 2026 aufgabenspezifische KI-Agenten enthalten, von unter 5% in 2025, und dass bis 2028 mindestens 15% der täglichen Arbeitsentscheidungen autonom getroffen werden, von praktisch null in 2024.[3][4] Die Content-Produktion, repetitiv, mehrstufig und leicht in Phasen zerlegbar, ist einer der natürlichsten Orte für diese Verschiebung.
Agentische KI kommt schnell, doch die Umsetzung ist das Schwere
Die Adoptionsprognosen sind steil, ein großer Teil der Projekte erreicht aber keine Veröffentlichung[3][4]
Quellen: Gartner-Pressemitteilungen (Juni und Aug. 2025). Der letzte Balken ist der Realitätscheck: Gartner erwartet, dass über 40% der agentischen KI-Projekte bis Ende 2027 eingestellt werden, meist wegen Kosten, unklarem Nutzen oder schwachen Leitplanken, nicht weil die Idee nicht funktioniert.
Warum ein einzelner Prompt an echter Arbeit scheitert
Ein Aufruf reicht für einen einzelnen Absatz. Verlangen Sie verlässliche, wiederholbare, publikationsreife Inhalte in Menge, und die Risse zeigen sich.
Um zu verstehen, warum man Agenten überhaupt verkettet, muss man sehen, wo der einzelne Prompt bricht. Für einen schnellen Entwurf oder ein Brainstorming ist er wirklich nützlich. Der Ärger beginnt, wenn die Ausgabe genau, konsistent und publikationsreif sein muss, Woche für Woche, ohne dass jemand sie jedes Mal umschreibt. Vier Fehlermodi tauchen immer wieder auf.
Es erfindet Quellen und Statistiken
Ein einzelnes Modell, das autoritativ schreiben soll, rät, wenn es etwas nicht weiß, weil die meisten Benchmarks eine selbstsichere Antwort über das Eingeständnis von Unsicherheit stellen. Das Ergebnis sind plausible Zahlen und Zitate, die nicht existieren.
Nichts prüft jemals die Arbeit
Ein einzelner Prompt erzeugt Text und hört auf. Es gibt keinen zweiten Schritt, der jede Aussage gegen das aktuelle Web abgleicht, sodass Fehler ohne Sicherheitsnetz direkt zu Ihren Lesern gelangen.
Es verliert bei langen Texten den Faden
Hält man alles in einem Kontextfenster, driftet die Qualität ab: die Einleitung verspricht das eine, das Fazit argumentiert das andere, und der Brief gerät auf halbem Weg in Vergessenheit.
Ein Arbeiter für fünf Jobs
Recherchieren, Schreiben, Prüfen, Übersetzen und Formatieren sind verschiedene Fähigkeiten. Zwingt man einen Durchgang dazu, alles auf einmal zu tun, bekommt nichts volle Aufmerksamkeit, genau deshalb übertreffen spezialisierte Agenten einen einzelnen Aufruf.
Der erste Fehler ist der berühmte: die Halluzination. Ein Modell, das autoritativ klingen soll, erzeugt selbstsicheren, plausiblen Text, auch ohne echte Grundlage für eine Aussage. OpenAIs eigene Forschung ist deutlich, warum: Standardevaluierungen belohnen das Modell fürs Raten statt fürs „Ich weiß es nicht", also lernt es genau das.[2] Unabhängige Benchmarks bestätigen es. Beim treuen Zusammenfassen eines Quelldokuments bleiben die besten Modelle heute um oder unter ein Prozent nicht belegter Aussagen, viele liegen aber deutlich darüber, und das ist der einfache Fall, in dem die Quelle direkt vor dem Modell liegt.[5][10] Offenes Schreiben ohne fixierte Quelle ist noch schwerer.
Selbstsicher und falsch ist die gefährliche Kombination
Die anderen drei Fehler sind leiser, aber genauso teuer. Ein einzelner Prompt hat keinen Prüfschritt, er schreibt und hört auf, also gleicht nichts seine Aussagen mit dem aktuellen Web ab. Er driftet bei langen Texten ab, weil Brief, Argument und jeder Fakt in einem Kontextfenster zu halten umso schwerer wird, je länger die Ausgabe läuft. Und er lässt einen Arbeiter fünf Jobs gleichzeitig machen, recherchieren, schreiben, prüfen, übersetzen und formatieren, ohne dass eines volle Aufmerksamkeit bekommt. Diese Jobs auf Agenten aufzuteilen ist keine Überkonstruktion. Es ist derselbe Grund, warum eine Redaktion Reporter, Redakteure und Faktenprüfer hat statt einer Person für alles.
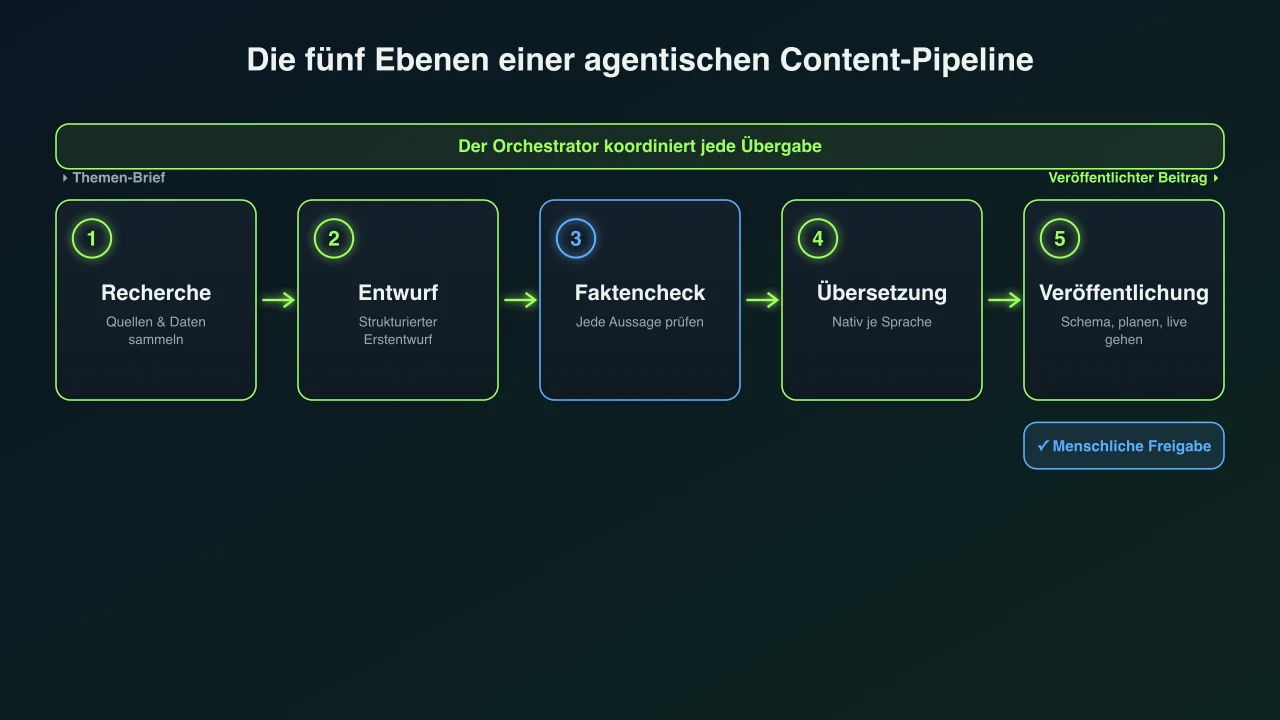
Die Orchestrierungsebenen: von der Recherche zum veröffentlichten Beitrag
Fünf Phasen, jede mit Aufgabe, Tools und Kontrollpunkt. Der Orchestrator ist der Dirigent, der die Ordnung hält.
Eine Pipeline wird durch ihre Phasen und die Schicht definiert, die sie koordiniert. Der Koordinator heißt meist Orchestrator: er nimmt das Ziel auf, zerlegt es in Teilaufgaben, übergibt jede dem richtigen Agenten und entscheidet, was passiert, wenn etwas falsch zurückkommt.[6][12] Unter dem Orchestrator sitzen die Worker-Agenten, die die eigentliche Content-Arbeit erledigen, und die Reviewer-Agenten, die deren Ausgabe an Kriterien messen, bevor sie weitergeht. So sieht jede Phase in einer typischen Content-Pipeline aus.
| Phase | Was sie tut | Genutzte Tools | Wer sie prüft |
|---|---|---|---|
| 1. Recherche | Sammelt Quellen, Daten, Statistiken und Zitate zum Thema aus dem aktuellen Web und verdichtet sie zu strukturierten Notizen. | Websuche und Abruf, wobei eine Quellenliste für die spätere Prüfung aufbewahrt wird. | Eine eigene Faktencheck-Stufe, plus eine menschliche Stichprobe bei allem Überraschenden. |
| 2. Entwurf | Verwandelt den Brief und die Recherchenotizen in einen strukturierten Erstentwurf mit klarer Argumentation, Überschriften und Beispielen. | Das Schreibmodell, gesteuert durch einen Brief und einen Marken-Styleguide. | Ein Editor-Agent prüft Struktur und Ton, bevor der Entwurf weitergeht. |
| 3. Faktencheck | Prüft jede Statistik, Aussage, jedes genannte Tool und jeden Link gegen die Quellen und schreibt um oder entfernt, was nicht hält. | Erneut Websuche, die ursprüngliche Quellenliste und Link-Erreichbarkeitsprüfungen. | Ein Mensch gibt rechtliche, medizinische, finanzielle oder Sicherheitsaussagen frei. |
| 4. Übersetzung und Lokalisierung | Schreibt den Beitrag für jeden Markt so um, dass er nativ klingt, nicht Wort für Wort, inklusive Diagrammbeschriftungen und Überschriften. | Ein Übersetzungsmodell plus ein Glossar von Begriffen, die fest bleiben müssen. | Ein Muttersprachler prüft dort, wo Risiko oder Markenstimme hoch sind. |
| 5. Veröffentlichung | Formatiert den Beitrag, fügt strukturierte Daten und Bilder hinzu und plant ihn ein oder stellt ihn nach festem Takt live. | Eine CMS-API und ein Schema-Validator, plus Bildgenerierung. | Ein optionales menschliches Freigabe-Tor: jeden Beitrag freigeben oder laufen lassen. |
Die Reihenfolge zählt so viel wie die Schritte. Die Recherche muss vor dem Entwurf fertig sein, sonst hat der Schreiber nichts Echtes zur Grundlage. Der Faktencheck kommt nach dem Entwurf, aber vor der Veröffentlichung, um Fehler zu fangen, solange sie billig zu beheben sind. Die Übersetzung kommt spät, sobald der Quelltext steht, damit man keinen Beitrag neu übersetzt, der sich noch ändert. Der Orchestrator erzwingt diese Reihenfolge und, ebenso wichtig, behandelt die Ausnahmen: lehnt der Faktenprüfer eine Aussage ab, geht die Arbeit zurück zu Recherche oder Entwurf, statt weiterzurasen.[6]
- Agent: ein Modell mit einem Ziel, das Schritte planen, Tools nutzen und selbst handeln kann, statt eine einzelne Frage einmal zu beantworten.
- Orchestrator: der Leitagent, der ein Ziel in Teilaufgaben zerlegt, sie delegiert und die Ergebnisse zusammenführt. Auch Leit- oder Planungsagent genannt.
- Subagent: ein spezialisierter Arbeiter mit einer engen Aufgabe wie Recherche oder Faktencheck, oft mit eigenem Kontextfenster.
- Tool-Nutzung: ein Agent, der etwas außerhalb des Modells aufruft, Websuche, Schema-Validator, Bildgenerator oder Publishing-API, um echte Arbeit zu leisten.
- Mensch in der Schleife: eine Person an einem definierten Kontrollpunkt, meist ein Freigabe-Tor vor der Veröffentlichung.
Spezialisierte Subagenten und die Tools, die sie führen
Die Stärke einer Pipeline kommt aus Arbeitsteilung plus der Fähigkeit, das Modell zu verlassen und die echte Welt zu berühren.
Zwei Ideen machen eine Pipeline mehr als die Summe ihrer Prompts. Die erste ist Spezialisierung. Statt eines einzelnen Generalisten-Aufrufs delegiert der Orchestrator an Subagenten, die je eine Sache tun: ein Rechercheagent, der nur Quellen sammelt und strukturiert, ein Schreibagent, gesteuert von einem Marken-Styleguide, ein Faktenagent, der nur prüft, ein Übersetzungsagent pro Sprache. Jeder kann Modell, Einstellungen und Anweisungen auf seine Aufgabe abstimmen, und weil jeder ein eigenes Kontextfenster hat, läuft die Arbeit parallel und niemandem geht der Platz aus.[1][12]
Die zweite Idee ist die Tool-Nutzung. Eine Pipeline nützt nur, wenn sie auf die Welt einwirken kann, nicht nur sie beschreiben. Das heißt Agenten, die echte Tools aufrufen: Websuche und Abruf für aktuelle Fakten, ein Schema-Validator für korrekte strukturierte Daten, ein Bildgenerator für Titelbild und Diagramme und eine CMS-API, um tatsächlich zu veröffentlichen.[11] Der Trend 2026 geht zu Standardschnittstellen, die Agenten Lese- und Schreibzugriff über die gesamte Pipeline geben, sodass ein Agent nicht nur Ihre Analysen liest, sondern darauf hin entwirft, plant und veröffentlicht.[11] Tools sind das, was einen Chatbot, der übers Publizieren redet, in ein System verwandelt, das publiziert.
Der Arbeitsteilungs-Test
Wo Menschen bleiben
Ohne menschliches Zutun ist eine Überschrift, nicht die ganze Wahrheit. Klug ist nicht, Menschen zu entfernen, sondern sie dort zu platzieren, wo sie am meisten beitragen.
Die Formel „ohne menschliches Zutun" klingt reizvoll, und für Arbeit mit geringem Risiko und hohem Volumen ist sie erreichbar. Doch die ehrliche Version ist nicht, dass Menschen verschwinden. Es ist, dass sie an die wenigen Stellen rücken, wo ihr Urteil unersetzlich ist, und sich aus der mechanischen Mitte zurückziehen. Treffen Sie diese Platzierung richtig, behalten Sie das Tempo, ohne Ihren Ruf auf eine Maschine zu setzen.
Wo eine Person in der Schleife bleibt
Drei Aufgaben sollten besonders menschlich bleiben. Markenstimme und finales Urteil: ein Modell kann einen Ton imitieren, aber zu entscheiden, ob ein fertiges Stück wirklich nach Ihnen klingt und ob es gut ist, ist eine menschliche Entscheidung. Aussagen mit hohem Einsatz: alles Rechtliche, Medizinische, Finanzielle oder Sicherheitsrelevante verdient die Freigabe einer Person, denn die Kosten eines selbstsicheren Fehlers bemessen sich dort in Klagen oder Schaden, nicht in einer Korrektur. Und die Strategie: zu entscheiden, was es wert ist gesagt zu werden, welche Themen Ihren Lesern und Ihrem Geschäft dienen, ist der Teil, der nie ganz delegiert werden sollte.
Es gibt auch einen Suchqualitäts-Grund, einen Menschen ehrlich zu halten. Googles Spam-Richtlinien benennen den skalierten Content-Missbrauch, Inhalte, die in Masse vor allem zur Manipulation von Rankings erzeugt werden statt Menschen zu helfen, egal ob von Mensch oder Maschine gemacht.[9] Eine Pipeline, die dünne, ungeprüfte Artikel ausstößt, ist genau das Muster, das diese Richtlinie trifft. Eine Pipeline mit echter Recherche, Prüfung und redaktioneller Aufsicht produziert die Art nützlicher Inhalte, die die Richtlinie belohnen will. Die menschlichen Kontrollpunkte sind nicht nur Risikomanagement. Sie sind das, was die Ausgabe auf der richtigen Seite der Linie hält.
Die Durchsatz-Rechnung: was Sie wirklich gewinnen
Der Nutzen ist real, aber nicht gratis. Hier ist, was das Aufteilen der Arbeit messbar bringt und was es kostet.
Das Argument für eine Pipeline ist kein Gerede. Anthropic veröffentlichte Zahlen aus dem eigenen Multi-Agenten-Recherchesystem, und sie sind eindrücklich: ein Aufbau mit einem Leitagenten, der Subagenten koordiniert, übertraf einen einzelnen Agenten um 90,2% in einer internen Recherche-Eval und verkürzte die Zeit für komplexe, mehrteilige Recherche um bis zu 90% gegenüber dem sequenziellen Vorgehen.[1] Der Grund ist genau die oben beschriebene Arbeitsteilung: Subagenten erkunden verschiedene Blickwinkel parallel, jeder mit eigenem Kontext, dann führt der Leitagent die Ergebnisse zusammen.
Warum es sich auszahlt, ein Modell in viele Rollen zu teilen
Anthropics interne Recherche-Eval, plus eine harte Wahrheit darüber, wohin die Content-Zeit wirklich geht[1][7]
Quellen: Anthropic Engineering (Multi-Agenten-Recherchesystem) für die Qualitäts- und Zeitzahlen; eine Content-Operations-Analyse von 2026 für den Schreibanteil. Fazit: nur das Schreiben zu beschleunigen hilft kaum, denn das Schreiben war nie der Engpass.
Dieser letzte Balken ist der, den kleine Unternehmer übersehen. Es ist verlockend zu denken, der Gewinn der KI sei schnelleres Schreiben. Doch in einem echten Content-Betrieb ist das Schreiben ein kleiner Teil der Zeit, etwa ein Zehntel laut einer Content-Operations-Analyse; der Großteil ist Recherche, SEO-Arbeit, redaktionelle Prüfung und Faktencheck.[7] Ein Tool, das nur den Entwurf beschleunigt, schneidet nur einen Splitter vom Ganzen ab. Eine Pipeline, die auch Recherche, Prüfung und Veröffentlichung automatisiert, ist das, was Ihren Durchsatz wirklich verändert, weil sie die Teile angeht, die Sie tatsächlich bremsten.
Die Kostenseite der Rechnung
Ein praktisches Beispiel: wie ein Beitrag wie dieser entsteht
Das ehrlichste Beispiel einer agentischen Content-Pipeline ist eines, auf das man zeigen kann. So sieht ein echtes aus.
Alles Obige sieht man leichter in einem konkreten System, betrachten Sie also eine produktisierte Pipeline für kleine Teams statt einer, die Sie selbst bauen müssten. News Factory ist selbst eine agentische Content-Pipeline, was es zum ehrlichen Beispiel dieses Beitrags macht: seine KI-Agenten entdecken Trendthemen in Ihrer Nische, recherchieren und entwerfen vollständige Artikel in Ihrer Markenstimme und veröffentlichen, in den Pro-Tarifen und höher, autonom nach einem Zeitplan, den Sie festlegen. Entscheidend: es behält den menschlichen Kontrollpunkt, den dieser Artikel fordert, Sie wählen, jeden Beitrag vor dem Livegang freizugeben oder die Agenten voll autonom laufen zu lassen, und sein Business-Tarif ergänzt ein auf Ihren Ton trainiertes Marken- und Redaktionsstimmenmodell. Es kann in bis zu fünf Zielsprachen übersetzen und veröffentlichen und Beiträge direkt an ein CMS wie WordPress schieben.
Beachten Sie, worauf das passt. Die Entdeckungs- und Rechercheagenten sind Phase eins und drei. Das Schreiben in Ihrer Markenstimme ist Phase zwei mit angehängtem Styleguide. Die Übersetzung in mehrere Sprachen ist Phase vier. Das geplante Auto-Publizieren an Ihr CMS ist Phase fünf, mit dem Freigabe-Tor als menschlichem Kontrollpunkt. Es ist dieselbe fünfstufige Pipeline, die dieser Beitrag beschreibt, verpackt, damit ein Solo-Betreiber oder ein kleines Marketingteam den Durchsatz eines redaktionellen Fließbands erhält, ohne die Orchestrierung selbst zu bauen oder zu babysitten. Das ist das praktische Versprechen agentischen Contents: keine Magie, sondern eine gut geführte Linie, die Sie wirklich mit einer Person besetzen können.
Treten Sie zurück und das Thema wird einfacher. Eine agentische Content-Pipeline ist nur ein redaktionelles Fließband aus KI-Agenten: recherchieren, entwerfen, prüfen, übersetzen, veröffentlichen, mit einem Orchestrator, der Ordnung hält, und einem Menschen, der Marke, Fakten und Recht bewacht. Sie schlägt einen einzelnen Prompt nicht, weil das zugrunde liegende Modell klüger ist, sondern weil die Arbeit aufgeteilt, geprüft und sequenziert wird, wie es jeder ernsthafte Publishing-Betrieb ohnehin tut. Nutzen Sie eine, wo Sie oft genug publizieren, um die Kosten zu rechtfertigen, behalten Sie eine Person an den Kontrollpunkten mit echtem Risiko, und Sie erhalten das Volumen und die Konsistenz, die früher ein ganzes Team verlangten.
Weiterführende Artikel
- Wie man KI-Inhalte 2026 menschlicher macht: die redaktionelle Ebene, die die Pipeline-Ausgabe menschlich klingen lässt.
- Wie man mit KI-Inhalten ohne Strafe rankt: die Linie des skalierten Content-Missbrauchs in Klartext.
- Der Content-Kalender für Solo-Unternehmer: der Publishing-Takt, für den eine Pipeline gebaut ist.
- Übersetzte Inhalte und SEO: warum die Lokalisierungsphase eine Neufassung sein muss, kein Wortwechsel.
Quellen und Referenzen
Artikel auch verfügbar in: