Ce qu'est vraiment un pipeline de contenu agentique
Ce n'est pas un prompt plus malin. C'est une chaîne de montage d'agents spécialisés, chacun avec une tâche, qui passent le travail au suivant.
La plupart des gens découvrent l'écriture par IA comme une boîte unique : vous tapez une demande, elle renvoie un article. C'est un seul prompt qui fait une tâche. Un pipeline de contenu agentique est tout autre chose. C'est une chaîne d'agents IA spécialisés qui font passer un contenu par des étapes distinctes, d'abord la recherche, puis la rédaction, puis la vérification, puis la traduction, puis la publication, avec une couche d'orchestration au-dessus qui coordonne les transferts et gère les exceptions.[6] Voyez-le moins comme une autocomplétion maligne et davantage comme une petite équipe éditoriale automatisée où chaque membre a une responsabilité et passe le travail une fois sa partie terminée.
Le mot clé est agentique. Un modèle de langage ordinaire attend des instructions et répond une fois. Un agent reçoit un objectif, planifie les étapes, utilise des outils comme la recherche web ou une API de publication, vérifie sa propre progression et décide de la suite sans qu'on le sollicite à chaque tour.[12] Reliez-en plusieurs, donnez à chacun un périmètre précis, et vous obtenez un pipeline qui prend un brief de sujet d'un côté et produit un article fini, vérifié et traduit de l'autre. Pour une petite entreprise qui publie régulièrement, cette différence sépare un outil à surveiller d'un système qui tourne tout seul.
La définition en une phrase
Ce n'est plus une idée marginale. Gartner prévoit que 40% des apps d'entreprise incluront des agents IA spécialisés d'ici 2026, contre moins de 5% en 2025, et qu'au moins 15% des décisions de travail quotidiennes seront prises de façon autonome d'ici 2028, contre quasiment zéro en 2024.[3][4] La production de contenu, répétitive, en plusieurs étapes et facile à découper, est l'un des terrains les plus naturels pour ce basculement.
L'IA agentique arrive vite, mais l'exécution est le plus dur
Les prévisions d'adoption sont fortes, mais une grande part des projets n'atteint pas la publication[3][4]
Sources : communiqués de Gartner (juin et août 2025). La dernière barre est le contrepoint : Gartner prévoit l'abandon de plus de 40% des projets d'IA agentique avant fin 2027, le plus souvent pour cause de coût, de valeur floue ou de garde-fous faibles, pas parce que l'idée ne marche pas.
Pourquoi un seul prompt s'effondre sur le vrai travail
Un seul appel suffit pour un paragraphe isolé. Demandez-lui un contenu fiable, répétable et prêt à publier à volume et les fissures apparaissent.
Pour comprendre pourquoi enchaîner des agents, il faut voir où le prompt unique casse. Il est vraiment utile pour un brouillon rapide ou un remue-méninges. L'ennui commence quand vous avez besoin que la sortie soit exacte, cohérente et prête à publier, semaine après semaine, sans que quelqu'un la réécrive à chaque fois. Quatre modes de défaillance reviennent sans cesse.
Il invente des sources et des statistiques
Un seul modèle à qui l'on demande d'écrire avec autorité devinera quand il ne sait pas, car la plupart des benchmarks récompensent une réponse assurée plutôt que l'aveu d'incertitude. Le résultat : des chiffres et des citations plausibles qui n'existent pas.
Rien ne vérifie jamais le travail
Un seul prompt produit du texte et s'arrête. Il n'y a pas de deuxième étape qui compare chaque affirmation au web en direct, donc les erreurs filent droit vers vos lecteurs sans filet.
Il perd le fil sur les longs textes
Tout tenir dans une seule fenêtre de contexte fait dériver la qualité : l'introduction promet une chose, la conclusion en défend une autre, et le brief est oublié à mi-chemin.
Un seul ouvrier pour cinq métiers
Rechercher, écrire, vérifier, traduire et mettre en forme sont des compétences différentes. Forcer une seule passe à tout faire à la fois fait qu'aucune ne reçoit toute l'attention, et c'est précisément pourquoi des agents spécialisés surpassent un seul appel.
La première défaillance est la plus connue : l'hallucination. Un modèle à qui l'on demande de faire autorité produira un texte assuré et plausible même sans base réelle. La recherche d'OpenAI est claire sur le pourquoi : les évaluations standard récompensent le modèle qui devine plutôt que de dire "je ne sais pas", alors c'est exactement ce qu'il apprend à faire.[2] Les benchmarks indépendants le confirment. Pour résumer fidèlement un document source, les meilleurs modèles restent aujourd'hui autour ou sous un pour cent d'affirmations non étayées, mais beaucoup sont nettement au-dessus, et c'est le cas facile, où la source est sous les yeux du modèle.[5][10] L'écriture ouverte, sans source fixée, est plus dure encore.
Assuré et faux, la combinaison dangereuse
Les trois autres défaillances sont plus discrètes mais tout aussi coûteuses. Un seul prompt n'a aucune étape de vérification, il écrit et s'arrête, donc rien ne compare ses affirmations au web en direct. Il dérive sur les longs textes, car tenir le brief, l'argument et chaque fait dans une seule fenêtre de contexte devient plus dur à mesure que la sortie s'allonge. Et il demande à un seul ouvrier de faire cinq métiers à la fois, rechercher, écrire, vérifier, traduire et mettre en forme, sans qu'aucun reçoive toute l'attention. Répartir ces métiers entre agents n'est pas de la sur-ingénierie. C'est la même raison pour laquelle une rédaction a des reporters, des éditeurs et des vérificateurs plutôt qu'une seule personne pour tout.
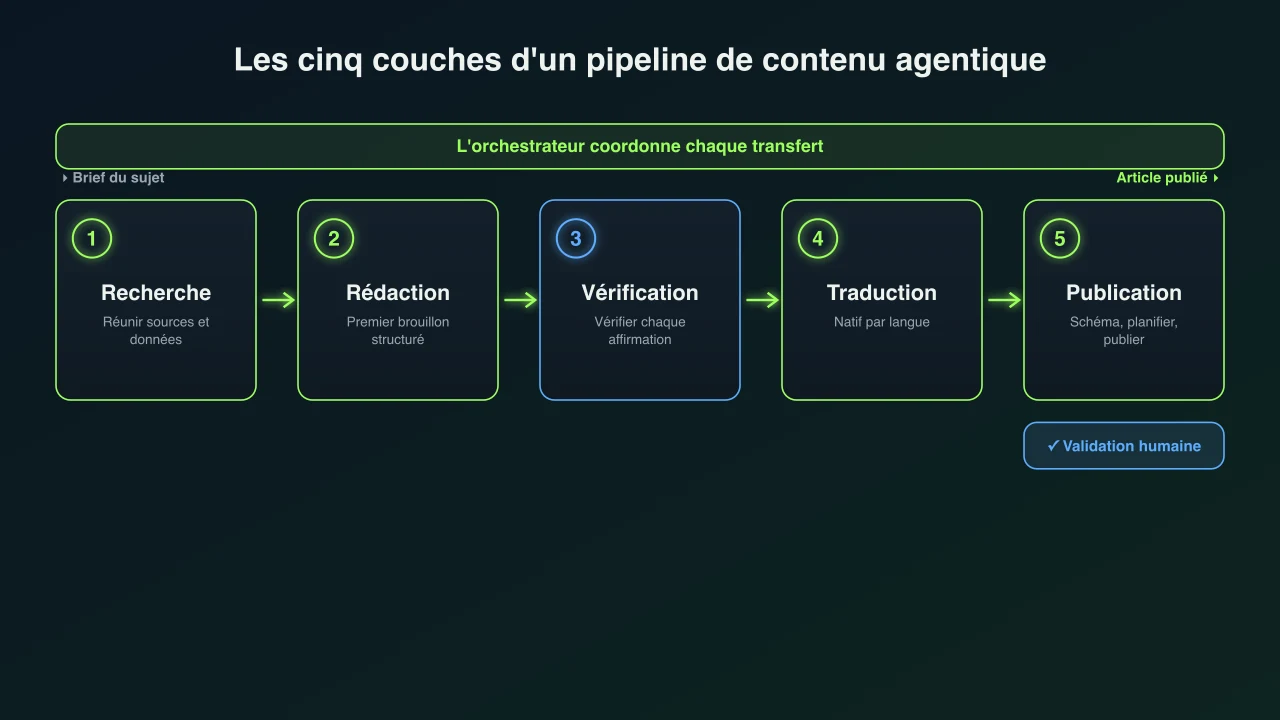
Les couches d'orchestration : de la recherche à l'article publié
Cinq étapes, chacune avec sa tâche, ses outils et son contrôle. L'orchestrateur est le chef d'orchestre qui maintient l'ordre.
Un pipeline se définit par ses étapes et par la couche qui les coordonne. Le coordinateur s'appelle souvent l'orchestrateur : il reçoit l'objectif, le découpe en sous-tâches, confie chacune au bon agent et décide quoi faire quand quelque chose revient faux.[6][12] Sous l'orchestrateur se trouvent les agents ouvriers qui font le travail de contenu et les agents relecteurs qui notent leur sortie selon des critères avant qu'elle n'avance. Voici ce que fait chaque étape dans un pipeline de contenu typique.
| Étape | Ce qu'elle fait | Outils utilisés | Qui la relit |
|---|---|---|---|
| 1. Recherche | Réunit sources, données, statistiques et citations sur le sujet depuis le web en direct, puis les condense en notes structurées. | Recherche web et récupération, avec une liste de sources gardée pour la vérification ultérieure. | Une étape de vérification séparée, plus un contrôle humain sur tout élément surprenant. |
| 2. Rédaction | Transforme le brief et les notes de recherche en un premier brouillon structuré avec un argument, des titres et des exemples clairs. | Le modèle de rédaction, guidé par un brief et une charte éditoriale de marque. | Un agent éditeur vérifie structure et ton avant que le brouillon n'avance. |
| 3. Vérification | Vérifie chaque statistique, affirmation, outil cité et lien par rapport aux sources, et réécrit ou supprime ce qui ne tient pas. | À nouveau la recherche web, la liste de sources d'origine et des contrôles de liens actifs. | Une personne valide les affirmations juridiques, médicales, financières ou de sécurité. |
| 4. Traduction et localisation | Réécrit la pièce pour chaque marché afin qu'elle se lise nativement, et non mot à mot, étiquettes de graphiques et titres compris. | Un modèle de traduction plus un glossaire de termes qui doivent rester fixes. | Un locuteur natif relit là où les enjeux ou la voix de marque sont élevés. |
| 5. Publication | Met en forme l'article, ajoute des données structurées et des images, puis le planifie ou le publie sur le site selon une cadence définie. | Une API de CMS et un validateur de schéma, plus la génération d'images. | Une validation humaine optionnelle : approuver chaque article, ou le laisser partir. |
L'ordre compte autant que les étapes. La recherche doit finir avant la rédaction, sinon le rédacteur n'a rien de réel pour travailler. La vérification vient après la rédaction mais avant la publication, pour attraper les erreurs tant qu'elles sont peu coûteuses à corriger. La traduction arrive tard, une fois le texte source figé, pour ne pas retraduire une pièce qui change encore. L'orchestrateur impose cette séquence et, tout aussi important, gère les exceptions : si le vérificateur rejette une affirmation, le travail revient à la recherche ou à la rédaction plutôt que de foncer.[6]
- Agent : un modèle doté d'un objectif, capable de planifier des étapes, d'utiliser des outils et d'agir de lui-même, plutôt que de répondre une seule fois.
- Orchestrateur : l'agent principal qui découpe un objectif en sous-tâches, les délègue et synthétise les résultats. Parfois appelé agent principal ou planificateur.
- Sous-agent : un ouvrier spécialisé à qui l'on confie une tâche précise, comme la recherche ou la vérification, souvent avec sa propre fenêtre de contexte.
- Usage d'outils : un agent qui appelle quelque chose hors du modèle, recherche web, validateur de schéma, générateur d'images ou API de publication, pour accomplir un vrai travail.
- Humain dans la boucle : une personne placée à un point de contrôle défini, le plus souvent une validation avant publication.
Sous-agents spécialisés et les outils qu'ils manient
La puissance d'un pipeline vient de la division du travail plus la capacité à sortir du modèle et toucher le monde réel.
Deux idées font qu'un pipeline vaut plus que la somme de ses prompts. La première est la spécialisation. Au lieu d'un seul appel généraliste, l'orchestrateur délègue à des sous-agents qui font une chose : un agent de recherche qui ne fait que réunir et structurer des sources, un agent de rédaction guidé par une charte de marque, un agent de vérification qui ne fait que contrôler, un agent de traduction par langue. Chacun peut utiliser un modèle, des réglages et des consignes ajustés à sa tâche, et comme chacun a sa fenêtre de contexte, le travail tourne en parallèle et personne ne manque de place.[1][12]
La seconde idée est l'usage d'outils. Un pipeline n'est utile que s'il peut agir sur le monde, pas seulement le décrire. Cela veut dire des agents qui appellent de vrais outils : recherche web et récupération pour réunir des faits actuels, un validateur de schéma pour rendre les données structurées correctes, un générateur d'images pour l'image principale et les schémas, et une API de CMS pour publier réellement.[11] La tendance en 2026 va vers des interfaces standard qui donnent aux agents un accès en lecture et écriture sur tout le pipeline, si bien qu'un agent ne se contente pas de lire vos analyses, il rédige, planifie et publie en réponse.[11] Les outils, c'est ce qui transforme un chatbot qui parle de publier en un système qui publie.
Le test de la division du travail
Où restent les humains
Sans intervention humaine est un titre, pas toute la vérité. L'astuce n'est pas de retirer les humains, mais de les placer là où ils apportent le plus.
La formule "sans intervention humaine" séduit, et pour du travail à faible risque et fort volume, elle est atteignable. Mais la version honnête n'est pas que les humains disparaissent. C'est qu'ils se déplacent vers les rares endroits où leur jugement est irremplaçable, et s'écartent du milieu mécanique. Réussissez ce placement et vous gardez la vitesse sans miser votre réputation sur une machine.
Où une personne reste dans la boucle
Trois tâches en particulier devraient rester humaines. Voix de marque et jugement final : un modèle peut imiter un ton, mais décider si une pièce finie sonne vraiment comme vous, et si elle est bonne, est une décision humaine. Affirmations à fort enjeu : tout ce qui est juridique, médical, financier ou de sécurité mérite le feu vert d'une personne, car le coût d'une erreur assurée s'y mesure en procès ou en préjudices, pas en simple correction. Et la stratégie : décider ce qui mérite d'être dit, quels sujets servent vos lecteurs et votre entreprise, est la part qui ne devrait jamais être entièrement déléguée.
Il y a aussi une raison de qualité de recherche de garder un humain honnête. Les politiques anti-spam de Google pointent l'abus de contenu à grande échelle, du contenu produit en masse surtout pour manipuler le classement plutôt qu'aider les gens, qu'il soit fait par un humain ou une machine.[9] Un pipeline qui débite des articles minces et non vérifiés est exactement le schéma visé. Un pipeline avec de vraies recherche, vérification et supervision éditoriale produit le genre de contenu utile que la politique veut récompenser. Les points de contrôle humains ne sont pas que de la gestion du risque. Ce sont eux qui maintiennent la sortie du bon côté de la ligne.
Le calcul du rendement : ce que vous gagnez vraiment
Le bénéfice est réel mais pas gratuit. Voici ce que diviser le travail rapporte de mesurable, et ce que cela coûte.
L'argument pour un pipeline n'est pas du vent. Anthropic a publié les chiffres de son propre système de recherche multi-agents, et ils sont frappants : une configuration avec un agent principal coordonnant des sous-agents a dépassé un agent unique de 90,2% sur une évaluation interne de recherche, et a réduit jusqu'à 90% le temps pour mener des recherches complexes en plusieurs parties par rapport au traitement séquentiel.[1] La raison est exactement la division du travail décrite plus haut : les sous-agents explorent des angles différents en parallèle, chacun avec son contexte, puis l'agent principal synthétise les résultats.
Pourquoi diviser un modèle en plusieurs rôles paie
L'évaluation interne de recherche d'Anthropic, plus une dure vérité sur où part le temps du contenu[1][7]
Sources : Anthropic Engineering (système de recherche multi-agents) pour les chiffres de qualité et de temps ; une analyse d'opérations de contenu de 2026 pour la part de rédaction. À retenir : accélérer seulement l'écriture aide à peine, car l'écriture n'a jamais été le goulot d'étranglement.
Cette dernière barre est celle que les dirigeants de petites entreprises ratent. Il est tentant de croire que le gain de l'IA, c'est écrire plus vite. Mais dans une vraie opération de contenu, la rédaction est une petite tranche du temps, environ un dixième selon une analyse d'opérations de contenu ; le gros, c'est la recherche, le travail SEO, la relecture éditoriale et la vérification.[7] Un outil qui n'accélère que le brouillon ne rogne qu'une miette du total. Un pipeline qui automatise aussi recherche, vérification et publication est ce qui change vraiment votre rendement, car il attaque les parties qui vous ralentissaient réellement.
Le côté coût de l'équation
Un exemple concret : comment se fait un article comme celui-ci
L'exemple le plus honnête d'un pipeline de contenu agentique est un que l'on peut montrer. Voici la forme d'un vrai.
Tout ce qui précède se voit mieux dans un système concret, alors prenez un pipeline produit pensé pour les petites équipes plutôt qu'un que vous devriez construire vous-même. News Factory est lui-même un pipeline de contenu agentique, ce qui en fait l'exemple honnête de cet article : ses agents IA repèrent les sujets tendance de votre niche, recherchent et rédigent des articles complets dans la voix de votre marque et, sur ses offres Pro et au-dessus, publient de façon autonome selon un calendrier que vous définissez. Surtout, il conserve le point de contrôle humain que défend cet article, vous choisissez d'approuver chaque article avant sa mise en ligne ou de laisser les agents tourner en pleine autonomie, et son offre Business ajoute un modèle de voix de marque et éditoriale entraîné sur votre ton. Il peut traduire et publier dans jusqu'à cinq langues cibles et pousser les articles directement vers un CMS comme WordPress.
Remarquez ce que cela recoupe. Les agents de découverte et de recherche sont les étapes un et trois. La rédaction dans la voix de votre marque est l'étape deux avec une charte de style attachée. La traduction en plusieurs langues est l'étape quatre. La publication automatique planifiée vers votre CMS est l'étape cinq, avec la validation avant publication comme point de contrôle humain. C'est le même pipeline en cinq étapes que décrit cet article, empaqueté pour qu'un opérateur solo ou une petite équipe marketing obtienne le rendement d'une chaîne de montage éditoriale sans construire ni surveiller l'orchestration. Voilà la promesse pratique du contenu agentique : pas de magie, mais une chaîne bien gérée que vous pouvez vraiment tenir à une seule personne.
Prenez du recul et le sujet se simplifie. Un pipeline de contenu agentique n'est qu'une chaîne de montage éditoriale faite d'agents IA : rechercher, rédiger, vérifier, traduire, publier, avec un orchestrateur qui maintient l'ordre et un humain qui surveille marque, faits et droit. Il bat un seul prompt non parce que le modèle sous-jacent est plus malin, mais parce que le travail est divisé, contrôlé et séquencé comme le fait déjà toute opération de publication sérieuse. Utilisez-en un là où vous publiez assez souvent pour justifier le coût, gardez une personne aux points de contrôle qui portent le vrai risque, et vous obtenez le volume et la cohérence qui demandaient autrefois toute une équipe.
Lectures associées
- Comment humaniser le contenu IA en 2026 : la couche éditoriale qui garde la sortie du pipeline humaine.
- Comment se classer avec du contenu généré par IA sans pénalité : la ligne de l'abus de contenu à grande échelle en clair.
- Le calendrier de contenu pour un entrepreneur solo : la cadence de publication pour laquelle un pipeline est conçu.
- Contenu traduit et SEO : pourquoi l'étape de localisation doit être une réécriture, pas un échange de mots.
Références et sources
Article également disponible en :