Qué es de verdad un pipeline de contenido agéntico
No es un prompt más listo. Es una línea de montaje de agentes especializados, cada uno con una tarea, que pasan el trabajo al siguiente.
La mayoría conoce la escritura con IA como una sola caja: escribes una petición y te devuelve un artículo. Eso es un solo prompt haciendo una tarea. Un pipeline de contenido agéntico es otra cosa. Es una cadena de agentes de IA especializados que llevan una pieza por fases distintas, primero investigación, luego redacción, luego verificación, luego traducción, luego publicación, con una capa de orquestación encima que coordina las entregas y gestiona las excepciones.[6] Piénsalo menos como un autocompletado listo y más como un pequeño equipo editorial automatizado donde cada miembro tiene una responsabilidad y pasa el trabajo cuando termina su parte.
La palabra clave es agéntico. Un modelo de lenguaje normal espera instrucciones y responde una vez. Un agente recibe un objetivo, planifica los pasos, usa herramientas como la búsqueda web o una API de publicación, revisa su propio progreso y decide qué hacer a continuación sin que se lo pidan en cada turno.[12] Une varios de esos, dale a cada uno un encargo concreto y tienes un pipeline que toma un brief de tema por un extremo y produce un post acabado, verificado y traducido por el otro. Para una pequeña empresa que publica con regularidad, esa diferencia es la que separa una herramienta que tienes que vigilar de un sistema que funciona solo.
La definición en una frase
Ya no es una idea marginal. Gartner prevé que el 40% de las apps empresariales incluyan agentes de IA específicos para 2026, desde menos del 5% en 2025, y que al menos el 15% de las decisiones laborales diarias se tomen de forma autónoma para 2028, desde prácticamente cero en 2024.[3][4] La producción de contenido, repetitiva, de varios pasos y fácil de dividir en fases, es uno de los lugares más naturales para que este cambio aterrice primero.
La IA agéntica llega rápido, pero la ejecución es lo difícil
Las previsiones de adopción son pronunciadas, pero una gran parte de los proyectos aún no llega a publicar[3][4]
Fuentes: notas de prensa de Gartner (jun. y ago. 2025). La última barra es el contrapunto: Gartner prevé que más del 40% de los proyectos de IA agéntica se cancelen antes de finales de 2027, normalmente por coste, valor poco claro o controles débiles, no porque la idea no funcione.
Por qué un solo prompt se rompe en el trabajo real
Una sola llamada va bien para un párrafo suelto. Pídele contenido fiable, repetible y listo para publicar a volumen y aparecen las grietas.
Para entender por qué alguien se molestaría en encadenar agentes, hay que ver dónde se rompe el prompt único. Es genuinamente útil para un borrador rápido o una lluvia de ideas. El problema empieza cuando necesitas que la salida sea precisa, consistente y lista para publicar, semana tras semana, sin que alguien la reescriba cada vez. Cuatro modos de fallo aparecen una y otra vez.
Inventa fuentes y estadísticas
Un solo modelo al que se le pide escribir con autoridad adivinará cuando no sabe, porque la mayoría de los benchmarks premian una respuesta segura antes que admitir incertidumbre. El resultado son cifras y citas plausibles que no existen.
Nada revisa nunca el trabajo
Un solo prompt produce texto y se detiene. No hay un segundo paso que compare cada afirmación con la web en vivo, así que los errores llegan directos a tus lectores sin red de seguridad.
Pierde el hilo en textos largos
Si todo se sostiene en una sola ventana de contexto, la calidad se desvía: la introducción promete una cosa, la conclusión defiende otra y el brief se olvida a media página.
Un trabajador haciendo cinco tareas
Investigar, escribir, verificar, traducir y formatear son habilidades distintas. Forzar un único paso a hacerlas todas a la vez hace que ninguna reciba atención plena, que es justo por lo que los agentes especializados rinden más que una sola llamada.
El primer fallo es el famoso: la alucinación. Un modelo al que se le pide sonar con autoridad producirá texto seguro y plausible incluso sin base real para una afirmación. La propia investigación de OpenAI es clara sobre por qué: las evaluaciones estándar premian al modelo por adivinar antes que por decir "no lo sé", así que adivinar es justo lo que aprende a hacer.[2] Los benchmarks independientes lo confirman. En la tarea de resumir fielmente un documento fuente, los mejores modelos hoy se quedan cerca o por debajo del uno por ciento de afirmaciones no respaldadas, pero muchos están claramente por encima, y eso es para el caso fácil en el que la fuente está delante del modelo.[5][10] La escritura abierta, sin fuente fijada, es aún más difícil.
Seguro y equivocado es la combinación peligrosa
Los otros tres fallos son más silenciosos pero igual de costosos. Un solo prompt no tiene paso de verificación, escribe y se detiene, así que nada compara sus afirmaciones con la web en vivo. Se desvía en textos largos, porque sostener el brief, el argumento y cada dato en una sola ventana de contexto es más difícil cuanto más larga es la salida. Y le pide a un trabajador que haga cinco tareas a la vez, investigar, escribir, verificar, traducir y formatear, sin que ninguna reciba atención plena. Dividir esas tareas entre agentes no es sobreingeniería. Es la misma razón por la que una redacción tiene reporteros, editores y verificadores en lugar de una sola persona haciéndolo todo.
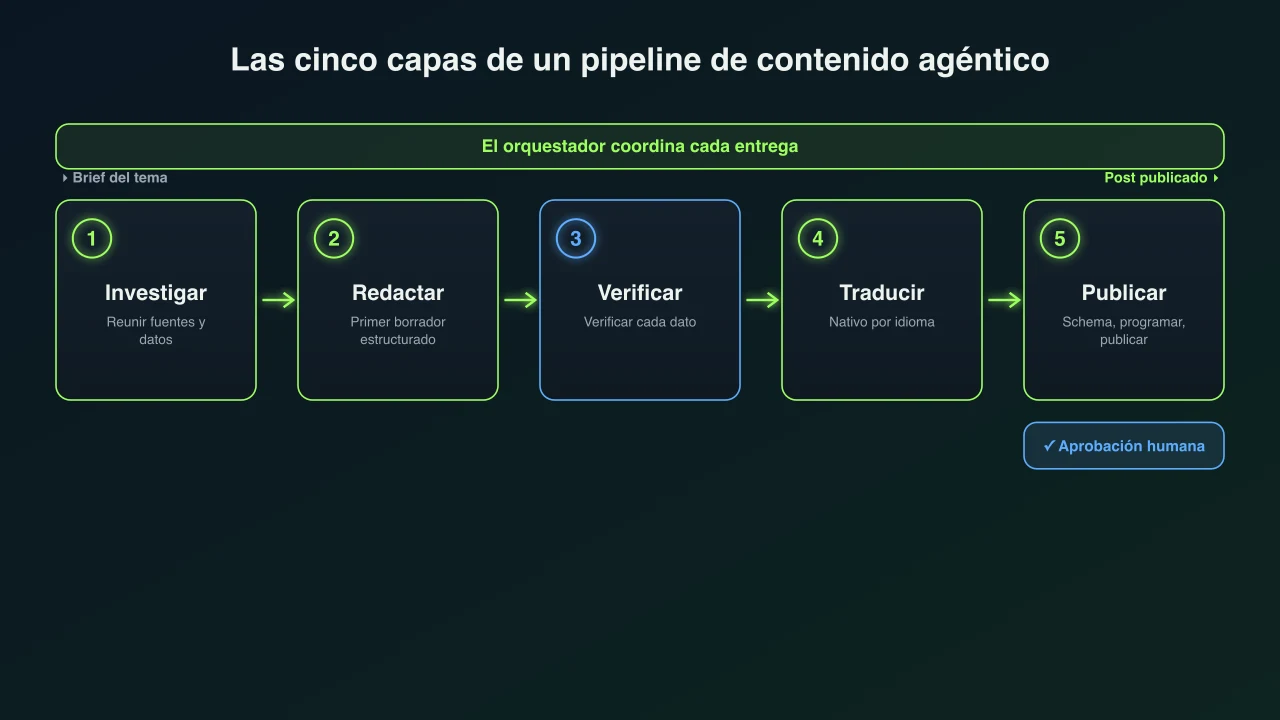
Las capas de orquestación: de la investigación al post publicado
Cinco fases, cada una con su tarea, sus herramientas y su control. El orquestador es el director que las mantiene en orden.
Un pipeline se define por sus fases y por la capa que las coordina. Al coordinador se le suele llamar orquestador: recibe el objetivo, lo divide en subtareas, entrega cada una al agente adecuado y decide qué pasa cuando algo vuelve mal.[6][12] Por debajo están los agentes trabajadores que hacen las tareas de contenido y los agentes revisores que evalúan su salida frente a criterios antes de que avance. Esto es lo que hace cada fase en un pipeline de contenido típico.
| Fase | Qué hace | Herramientas que usa | Quién la revisa |
|---|---|---|---|
| 1. Investigación | Reúne fuentes, datos, estadísticas y citas del tema desde la web en vivo y los condensa en notas estructuradas. | Búsqueda web y recuperación, guardando una lista de fuentes para verificarlas después. | Una fase de verificación aparte, más una revisión humana de cualquier dato sorprendente. |
| 2. Redacción | Convierte el brief y las notas de investigación en un primer borrador estructurado con argumento, titulares y ejemplos claros. | El modelo de redacción, guiado por un brief y una guía de estilo de marca. | Un agente editor revisa estructura y tono antes de que el borrador avance. |
| 3. Verificación | Comprueba cada estadística, afirmación, herramienta citada y enlace contra las fuentes, y reescribe o elimina lo que no se sostiene. | Búsqueda web de nuevo, la lista de fuentes original y comprobaciones de enlaces vivos. | Una persona aprueba las afirmaciones legales, médicas, financieras o de seguridad. |
| 4. Traducción y localización | Reescribe la pieza para cada mercado para que se lea de forma nativa, no palabra por palabra, incluidas etiquetas de gráficos y titulares. | Un modelo de traducción más un glosario de términos que deben quedar fijos. | Un hablante nativo revisa donde el riesgo o la voz de marca son altos. |
| 5. Publicación | Da formato al post, añade datos estructurados e imágenes, y lo programa o publica en el sitio con una cadencia definida. | Una API de CMS y un validador de schema, más generación de imágenes. | Una puerta de aprobación humana opcional: aprueba cada post o deja que se publique solo. |
El orden importa tanto como los pasos. La investigación tiene que terminar antes de la redacción, o el redactor no tiene nada real con lo que trabajar. La verificación va después de la redacción pero antes de la publicación, para atrapar los errores mientras aún son baratos de arreglar. La traducción llega tarde, una vez que el texto fuente es final, para no retraducir una pieza que aún cambia. El orquestador impone esa secuencia y, no menos importante, gestiona las excepciones: si el verificador rechaza una afirmación, el trabajo vuelve a investigación o redacción en lugar de seguir adelante.[6]
- Agente: un modelo con un objetivo que puede planificar pasos, usar herramientas y actuar por su cuenta, en vez de responder una sola pregunta una vez.
- Orquestador: el agente líder que divide un objetivo en subtareas, las delega y sintetiza los resultados. A veces llamado agente líder o planificador.
- Subagente: un trabajador especializado al que se le da una tarea concreta, como investigación o verificación, a menudo con su propia ventana de contexto.
- Uso de herramientas: un agente llamando a algo fuera del modelo, búsqueda web, un validador de schema, un generador de imágenes o una API de publicación, para hacer trabajo real.
- Persona en el bucle: alguien situado en un control definido, casi siempre una puerta de aprobación antes de publicar.
Subagentes especializados y las herramientas que manejan
La fuerza de un pipeline viene de la división del trabajo más la capacidad de salir del modelo y tocar el mundo real.
Dos ideas hacen que un pipeline sea más que la suma de sus prompts. La primera es la especialización. En lugar de una sola llamada generalista, el orquestador delega en subagentes que hacen una cosa: un agente de investigación que solo reúne y estructura fuentes, un agente de redacción guiado por una guía de estilo de marca, un agente de verificación que solo comprueba, un agente de traducción por idioma. Cada uno puede usar un modelo, ajustes e instrucciones afinados a su tarea, y como cada uno tiene su propia ventana de contexto, el trabajo corre en paralelo y nadie se queda sin espacio.[1][12]
La segunda idea es el uso de herramientas. Un pipeline solo sirve si puede actuar sobre el mundo, no solo describirlo. Eso significa agentes llamando a herramientas reales: búsqueda web y recuperación para reunir hechos actuales, un validador de schema para que los datos estructurados sean correctos, un generador de imágenes para la imagen principal y los diagramas, y una API de CMS para publicar de verdad.[11] La tendencia en 2026 es hacia interfaces estándar que dan a los agentes acceso de lectura y escritura a todo el pipeline, de modo que un agente no solo lee tus analíticas, sino que redacta, programa y publica en respuesta.[11] Las herramientas son lo que convierte un chatbot que habla de publicar en un sistema que publica.
La prueba de la división del trabajo
Dónde siguen las personas
Sin intervención humana es un titular, no toda la verdad. Lo inteligente no es quitar personas, es ponerlas donde más aportan.
La frase "sin intervención humana" es atractiva, y para trabajo de bajo riesgo y alto volumen es alcanzable. Pero la versión honesta no es que las personas desaparezcan. Es que las personas se mueven a los pocos lugares donde su juicio es irremplazable y se apartan del medio mecánico. Acierta esa colocación y mantienes la velocidad sin apostar tu reputación a una máquina.
Dónde sigue una persona en el bucle
Tres tareas en particular deberían seguir siendo humanas. Voz de marca y juicio final: un modelo puede imitar un tono, pero decidir si una pieza acabada de verdad suena como tú, y si es buena, es una decisión humana. Afirmaciones de alto riesgo: todo lo legal, médico, financiero o de seguridad merece el visto bueno de una persona, porque el coste de un error seguro ahí se mide en demandas o daños, no en una simple corrección. Y la estrategia: decidir qué merece decirse, qué temas sirven a tus lectores y a tu negocio, es la parte que nunca debería delegarse del todo.
También hay una razón de calidad de búsqueda para mantener a una persona honesta. Las políticas de spam de Google señalan el abuso de contenido a escala, contenido producido en masa principalmente para manipular rankings en lugar de ayudar a las personas, sin importar si lo hizo un humano o una máquina.[9] Un pipeline que bombea artículos finos y sin verificar es justo el patrón que esa política persigue. Un pipeline con investigación, verificación y supervisión editorial reales produce el tipo de contenido útil que la política está diseñada para premiar. Los controles humanos no son solo gestión de riesgos. Son lo que mantiene la salida del lado correcto de la línea.
Las cuentas del rendimiento: qué ganas de verdad
El beneficio es real, pero no es gratis. Esto es lo que dividir el trabajo compra de forma medible, y lo que cuesta.
El argumento a favor de un pipeline no es palabrería. Anthropic publicó cifras de su propio sistema de investigación multiagente, y son llamativas: una configuración con un agente líder coordinando subagentes superó a un solo agente en un 90,2% en una evaluación interna de investigación, y recortó hasta un 90% el tiempo para completar investigaciones complejas de varias partes frente a hacerlo de forma secuencial.[1] La razón es justo la división del trabajo descrita arriba: los subagentes exploran ángulos distintos en paralelo, cada uno con su contexto, y luego el agente líder sintetiza los resultados.
Por qué dividir un modelo en muchos roles compensa
La evaluación interna de investigación de Anthropic, más una verdad dura sobre adónde va el tiempo del contenido[1][7]
Fuentes: Anthropic Engineering (sistema de investigación multiagente) para las cifras de calidad y tiempo; un análisis de operaciones de contenido de 2026 para la parte de redacción. La lección: acelerar solo la redacción apenas ayuda, porque la redacción nunca fue el cuello de botella.
Esa última barra es la que se le escapa a los dueños de pequeñas empresas. Es tentador pensar que el beneficio de la IA es escribir más rápido. Pero en una operación de contenido real, la redacción es una pequeña porción del reloj, alrededor de una décima parte según un análisis de operaciones de contenido; el grueso es investigación, trabajo de SEO, revisión editorial y verificación.[7] Una herramienta que solo acelera el borrador recorta una astilla del total. Un pipeline que también automatiza investigación, verificación y publicación es lo que cambia de verdad tu rendimiento, porque ataca las partes que de verdad te frenaban.
El lado del coste
Un ejemplo práctico: cómo se hace un post como este
El ejemplo más honesto de un pipeline de contenido agéntico es uno que puedas señalar. Esta es la forma de uno real.
Todo lo anterior se ve más fácil en un sistema concreto, así que considera un pipeline productizado pensado para equipos pequeños y no uno que tendrías que construir tú mismo. News Factory es en sí mismo un pipeline de contenido agéntico, lo que lo convierte en el ejemplo honesto de este post: sus agentes de IA descubren historias en tendencia de tu nicho, investigan y redactan artículos completos con la voz de tu marca y, en sus planes Pro y superiores, publican de forma autónoma según un calendario que tú defines. Y lo importante, mantiene el control humano que este artículo defiende, tú eliges aprobar cada post antes de que salga o dejar que los agentes corran del todo solos, y su plan Business añade un modelo de voz de marca y editorial entrenado con tu tono. Puede traducir y publicar hasta en cinco idiomas objetivo y enviar los posts directamente a un CMS como WordPress.
Fíjate en lo que esto encaja. Los agentes de descubrimiento e investigación son las fases uno y tres. La redacción con la voz de tu marca es la fase dos con una guía de estilo adjunta. La traducción a varios idiomas es la fase cuatro. La publicación automática programada a tu CMS es la fase cinco, con la puerta de aprobación antes de publicar como control humano. Es el mismo pipeline de cinco fases que describe este post, empaquetado para que un operador en solitario o un pequeño equipo de marketing tenga el rendimiento de una línea de montaje editorial sin construir ni vigilar la orquestación. Esa es la promesa práctica del contenido agéntico: no magia, sino una línea bien gestionada que de verdad puedes operar con una sola persona.
Da un paso atrás y el tema se simplifica. Un pipeline de contenido agéntico es solo una línea de montaje editorial hecha de agentes de IA: investigar, redactar, verificar, traducir, publicar, con un orquestador manteniendo el orden y una persona vigilando marca, datos y ley. Supera a un solo prompt no porque el modelo subyacente sea más listo, sino porque el trabajo se divide, se comprueba y se secuencia como ya lo divide cualquier operación de publicación seria. Usa uno donde publiques lo bastante a menudo como para justificar el coste, mantén a una persona en los controles que cargan con el riesgo real, y consigues el volumen y la consistencia que antes requerían todo un equipo.
Lecturas relacionadas
- Cómo humanizar el contenido de IA en 2026: la capa editorial que mantiene la salida del pipeline sonando como una persona.
- Cómo posicionar con contenido generado por IA sin penalización: la línea del abuso de contenido a escala en lenguaje claro.
- El calendario de contenidos para un negocio individual: la cadencia de publicación para la que se construye un pipeline.
- Contenido traducido y SEO: por qué la fase de localización tiene que ser una reescritura, no un cambio de palabras.
Referencias y fuentes
Artículo también disponible en: