O que é mesmo um pipeline de conteúdo agêntico
Não é um prompt mais esperto. É uma linha de montagem de agentes especializados, cada um com uma tarefa, que passam o trabalho ao seguinte.
A maioria conhece a escrita com IA como uma caixa única: escreves um pedido e ela devolve um artigo. Isso é um só prompt a fazer uma tarefa. Um pipeline de conteúdo agêntico é outra coisa. É uma cadeia de agentes de IA especializados que levam um conteúdo por fases distintas, primeiro pesquisa, depois redação, depois verificação, depois tradução, depois publicação, com uma camada de orquestração por cima a coordenar as entregas e a apanhar as exceções.[6] Pensa nele menos como um preenchimento automático esperto e mais como uma pequena equipa editorial automatizada onde cada membro tem uma responsabilidade e passa o trabalho quando termina a sua parte.
A palavra-chave é agêntico. Um modelo de linguagem normal espera instruções e responde uma vez. Um agente recebe um objetivo, planeia os passos, usa ferramentas como a pesquisa web ou uma API de publicação, verifica o próprio progresso e decide o que fazer a seguir sem que lho peçam a cada turno.[12] Liga vários desses, dá a cada um um encargo concreto e tens um pipeline que recebe um brief de tema de um lado e produz um post acabado, verificado e traduzido do outro. Para uma pequena empresa que publica com regularidade, essa diferença separa uma ferramenta que tens de vigiar de um sistema que funciona sozinho.
A definição numa frase
Já não é uma ideia marginal. A Gartner prevê que 40% das apps empresariais incluam agentes de IA específicos até 2026, face a menos de 5% em 2025, e que pelo menos 15% das decisões de trabalho diárias sejam tomadas de forma autónoma até 2028, face a praticamente zero em 2024.[3][4] A produção de conteúdo, repetitiva, de vários passos e fácil de dividir em fases, é um dos lugares mais naturais para esta mudança aterrar primeiro.
A IA agêntica chega depressa, mas a execução é o difícil
As previsões de adoção são acentuadas, mas grande parte dos projetos ainda não chega a publicar[3][4]
Fontes: comunicados da Gartner (jun. e ago. 2025). A última barra é o contraponto: a Gartner prevê que mais de 40% dos projetos de IA agêntica sejam cancelados antes do final de 2027, normalmente por custo, valor pouco claro ou controlos fracos, não porque a ideia não funcione.
Porque um só prompt se desfaz no trabalho real
Uma só chamada chega para um parágrafo solto. Pede-lhe conteúdo fiável, repetível e pronto a publicar a volume e aparecem as fissuras.
Para perceber porque alguém se daria ao trabalho de encadear agentes, é preciso ver onde o prompt único parte. É genuinamente útil para um rascunho rápido ou uma chuva de ideias. O problema começa quando precisas que a saída seja precisa, consistente e pronta a publicar, semana após semana, sem que alguém a reescreva de cada vez. Quatro modos de falha aparecem vezes sem conta.
Inventa fontes e estatísticas
Um único modelo a quem se pede para escrever com autoridade adivinha quando não sabe, porque a maioria dos benchmarks premeia uma resposta segura em vez de admitir incerteza. O resultado são números e citações plausíveis que não existem.
Nada verifica nunca o trabalho
Um único prompt produz texto e para. Não há um segundo passo que compare cada afirmação com a web ao vivo, por isso os erros chegam diretos aos teus leitores sem rede de segurança.
Perde o fio em textos longos
Se tudo se segura numa só janela de contexto, a qualidade desvia-se: a introdução promete uma coisa, a conclusão defende outra e o brief é esquecido a meio.
Um trabalhador a fazer cinco tarefas
Pesquisar, escrever, verificar, traduzir e formatar são competências distintas. Forçar um único passo a fazê-las todas ao mesmo tempo faz com que nenhuma receba atenção plena, que é justamente por isso que agentes especializados rendem mais do que uma só chamada.
A primeira falha é a famosa: a alucinação. Um modelo a quem se pede para soar com autoridade produz texto seguro e plausível mesmo sem base real para uma afirmação. A própria investigação da OpenAI é clara sobre o porquê: as avaliações padrão premeiam o modelo por adivinhar em vez de dizer "não sei", por isso adivinhar é justamente o que ele aprende a fazer.[2] Os benchmarks independentes confirmam-no. Na tarefa de resumir fielmente um documento fonte, os melhores modelos ficam hoje perto ou abaixo de um por cento de afirmações não suportadas, mas muitos estão bem acima, e isto é para o caso fácil, em que a fonte está à frente do modelo.[5][10] A escrita aberta, sem fonte fixada, é ainda mais difícil.
Seguro e errado é a combinação perigosa
As outras três falhas são mais silenciosas mas igualmente caras. Um só prompt não tem passo de verificação, escreve e para, por isso nada compara as suas afirmações com a web ao vivo. Desvia-se em textos longos, porque segurar o brief, o argumento e cada facto numa só janela de contexto fica mais difícil quanto mais longa for a saída. E pede a um trabalhador que faça cinco tarefas ao mesmo tempo, pesquisar, escrever, verificar, traduzir e formatar, sem que nenhuma receba atenção plena. Dividir essas tarefas entre agentes não é sobre-engenharia. É a mesma razão por que uma redação tem repórteres, editores e verificadores em vez de uma só pessoa a fazer tudo.
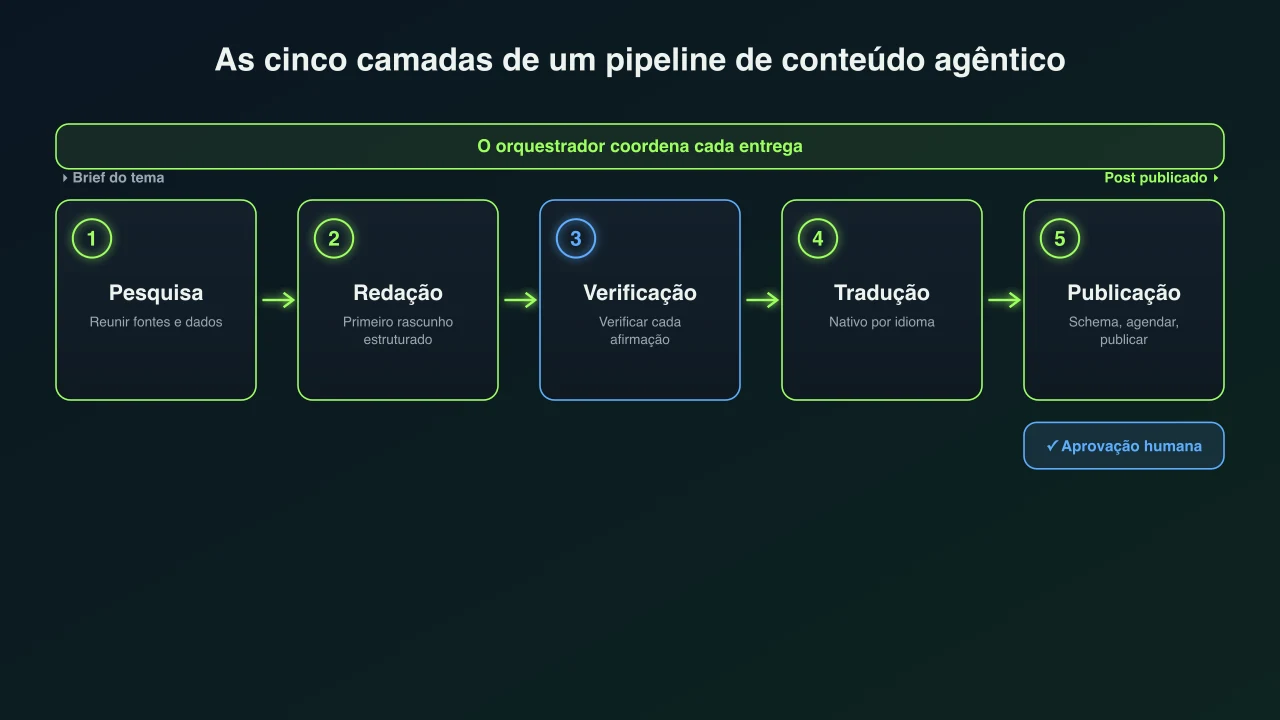
As camadas de orquestração: da pesquisa ao post publicado
Cinco fases, cada uma com a sua tarefa, ferramentas e controlo. O orquestrador é o maestro que mantém a ordem.
Um pipeline define-se pelas suas fases e pela camada que as coordena. Ao coordenador chama-se normalmente orquestrador: recebe o objetivo, divide-o em subtarefas, entrega cada uma ao agente certo e decide o que acontece quando algo volta errado.[6][12] Abaixo do orquestrador estão os agentes trabalhadores que fazem as tarefas de conteúdo e os agentes revisores que avaliam a sua saída face a critérios antes de avançar. Eis o que cada fase faz num pipeline de conteúdo típico.
| Fase | O que faz | Ferramentas que usa | Quem a revê |
|---|---|---|---|
| 1. Pesquisa | Reúne fontes, dados, estatísticas e citações sobre o tema a partir da web ao vivo e condensa-os em notas estruturadas. | Pesquisa web e recuperação, guardando uma lista de fontes para verificar depois. | Uma fase de verificação à parte, mais uma conferência humana de tudo o que surpreenda. |
| 2. Redação | Transforma o brief e as notas de pesquisa num primeiro rascunho estruturado com argumento, títulos e exemplos claros. | O modelo de redação, guiado por um brief e um guia de estilo de marca. | Um agente editor verifica estrutura e tom antes de o rascunho avançar. |
| 3. Verificação | Confere cada estatística, afirmação, ferramenta citada e link contra as fontes, e reescreve ou remove o que não se sustenta. | Pesquisa web de novo, a lista de fontes original e verificações de links ativos. | Uma pessoa aprova as afirmações legais, médicas, financeiras ou de segurança. |
| 4. Tradução e localização | Reescreve a peça para cada mercado para que se leia de forma nativa, não palavra a palavra, incluindo rótulos de gráficos e títulos. | Um modelo de tradução mais um glossário de termos que devem ficar fixos. | Um falante nativo revê onde o risco ou a voz de marca são altos. |
| 5. Publicação | Formata o post, adiciona dados estruturados e imagens, e agenda-o ou publica-o no site com uma cadência definida. | Uma API de CMS e um validador de schema, mais geração de imagens. | Um portão de aprovação humana opcional: aprovar cada post, ou deixar correr. |
A ordem importa tanto como os passos. A pesquisa tem de terminar antes da redação, ou o redator não tem nada real com que trabalhar. A verificação vem depois da redação mas antes da publicação, para apanhar os erros enquanto ainda são baratos de corrigir. A tradução chega tarde, uma vez fixado o texto fonte, para não retraduzir uma peça que ainda muda. O orquestrador impõe essa sequência e, igualmente importante, gere as exceções: se o verificador rejeita uma afirmação, o trabalho volta à pesquisa ou à redação em vez de seguir em frente.[6]
- Agente: um modelo com um objetivo que pode planear passos, usar ferramentas e agir por conta própria, em vez de responder uma só pergunta uma vez.
- Orquestrador: o agente líder que divide um objetivo em subtarefas, as delega e sintetiza os resultados. Às vezes chamado agente líder ou planeador.
- Subagente: um trabalhador especializado a quem se dá uma tarefa concreta, como pesquisa ou verificação, muitas vezes com a sua própria janela de contexto.
- Uso de ferramentas: um agente a chamar algo fora do modelo, pesquisa web, um validador de schema, um gerador de imagens ou uma API de publicação, para fazer trabalho real.
- Pessoa no circuito: alguém colocado num controlo definido, quase sempre um portão de aprovação antes de publicar.
Subagentes especializados e as ferramentas que manejam
A força de um pipeline vem da divisão do trabalho mais a capacidade de sair do modelo e tocar o mundo real.
Duas ideias fazem de um pipeline mais do que a soma dos seus prompts. A primeira é a especialização. Em vez de uma só chamada generalista, o orquestrador delega em subagentes que fazem uma coisa: um agente de pesquisa que só reúne e estrutura fontes, um agente de redação guiado por um guia de estilo de marca, um agente de verificação que só confere, um agente de tradução por idioma. Cada um pode usar um modelo, definições e instruções afinados à sua tarefa e, como cada um tem a sua janela de contexto, o trabalho corre em paralelo e ninguém fica sem espaço.[1][12]
A segunda ideia é o uso de ferramentas. Um pipeline só serve se puder agir sobre o mundo, não apenas descrevê-lo. Isso significa agentes a chamar ferramentas reais: pesquisa web e recuperação para reunir factos atuais, um validador de schema para que os dados estruturados fiquem certos, um gerador de imagens para a imagem principal e os diagramas, e uma API de CMS para publicar de verdade.[11] A tendência em 2026 é para interfaces padrão que dão aos agentes acesso de leitura e escrita a todo o pipeline, de modo que um agente não só lê as tuas analíticas, como redige, agenda e publica em resposta.[11] As ferramentas são o que transforma um chatbot que fala de publicar num sistema que publica.
O teste da divisão do trabalho
Onde ficam as pessoas
Sem intervenção humana é um título, não toda a verdade. O inteligente não é tirar pessoas, é pô-las onde mais acrescentam.
A frase "sem intervenção humana" é apelativa e, para trabalho de baixo risco e alto volume, é alcançável. Mas a versão honesta não é que as pessoas desapareçam. É que as pessoas se movem para os poucos lugares onde o seu juízo é insubstituível e se afastam do meio mecânico. Acerta nessa colocação e mantém-se a velocidade sem apostar a tua reputação numa máquina.
Onde uma pessoa fica no circuito
Três tarefas em particular deviam continuar humanas. Voz de marca e juízo final: um modelo pode imitar um tom, mas decidir se uma peça acabada soa mesmo a ti, e se é boa, é uma decisão humana. Afirmações de alto risco: tudo o que seja legal, médico, financeiro ou de segurança merece o aval de uma pessoa, porque o custo de um erro seguro aí mede-se em processos ou danos, não numa simples correção. E a estratégia: decidir o que vale a pena dizer, que temas servem os teus leitores e o teu negócio, é a parte que nunca devia ser totalmente delegada.
Há também uma razão de qualidade de pesquisa para manter uma pessoa honesta. As políticas de spam da Google apontam o abuso de conteúdo em escala, conteúdo produzido em massa sobretudo para manipular rankings em vez de ajudar as pessoas, quer o tenha feito um humano ou uma máquina.[9] Um pipeline que despeja artigos finos e não verificados é justamente o padrão que essa política visa. Um pipeline com pesquisa, verificação e supervisão editorial reais produz o tipo de conteúdo útil que a política quer premiar. Os pontos de controlo humanos não são só gestão de risco. São o que mantém a saída do lado certo da linha.
As contas do rendimento: o que ganhas de facto
O benefício é real, mas não é grátis. Eis o que dividir o trabalho compra de forma mensurável, e o que custa.
O argumento a favor de um pipeline não é conversa. A Anthropic publicou números do seu próprio sistema de pesquisa multiagente, e são marcantes: uma configuração com um agente líder a coordenar subagentes superou um único agente em 90,2% numa avaliação interna de pesquisa, e reduziu até 90% o tempo para concluir pesquisas complexas de várias partes face ao trabalho sequencial.[1] A razão é justamente a divisão do trabalho descrita acima: os subagentes exploram ângulos diferentes em paralelo, cada um com o seu contexto, e depois o agente líder sintetiza os resultados.
Porque dividir um modelo em vários papéis compensa
A avaliação interna de pesquisa da Anthropic, mais uma verdade dura sobre para onde vai o tempo do conteúdo[1][7]
Fontes: Anthropic Engineering (sistema de pesquisa multiagente) para os números de qualidade e tempo; uma análise de operações de conteúdo de 2026 para a parte da redação. A lição: acelerar só a redação quase não ajuda, porque a redação nunca foi o estrangulamento.
Essa última barra é a que escapa aos donos de pequenas empresas. É tentador pensar que o ganho da IA é escrever mais depressa. Mas numa operação de conteúdo real, a redação é uma pequena fatia do relógio, cerca de um décimo segundo uma análise de operações de conteúdo; o grosso é pesquisa, trabalho de SEO, revisão editorial e verificação.[7] Uma ferramenta que só acelera o rascunho corta uma lasca do total. Um pipeline que também automatiza pesquisa, verificação e publicação é o que muda de facto o teu rendimento, porque ataca as partes que te travavam mesmo.
O lado do custo da equação
Um exemplo prático: como se faz um post como este
O exemplo mais honesto de um pipeline de conteúdo agêntico é um que se possa apontar. Esta é a forma de um real.
Tudo o que vem acima vê-se mais fácil num sistema concreto, por isso considera um pipeline produtizado pensado para equipas pequenas e não um que terias de construir tu mesmo. A News Factory é em si mesma um pipeline de conteúdo agêntico, o que a torna o exemplo honesto deste post: os seus agentes de IA descobrem histórias em tendência no teu nicho, pesquisam e redigem artigos completos na voz da tua marca e, nos planos Pro e acima, publicam de forma autónoma segundo um calendário que defines. E o importante, mantém o ponto de controlo humano que este artigo defende, tu escolhes aprovar cada post antes de ir para o ar ou deixar os agentes correr totalmente autónomos, e o plano Business acrescenta um modelo de voz de marca e editorial treinado no teu tom. Pode traduzir e publicar em até cinco idiomas-alvo e enviar os posts diretamente para um CMS como o WordPress.
Repara no que isto encaixa. Os agentes de descoberta e pesquisa são as fases um e três. A redação na voz da tua marca é a fase dois com um guia de estilo em anexo. A tradução em vários idiomas é a fase quatro. A publicação automática agendada para o teu CMS é a fase cinco, com o portão de aprovação como ponto de controlo humano. É o mesmo pipeline de cinco fases que este post descreve, empacotado para que um operador solo ou uma pequena equipa de marketing tenha o rendimento de uma linha de montagem editorial sem construir nem vigiar a orquestração. Essa é a promessa prática do conteúdo agêntico: não é magia, mas uma linha bem gerida que podes mesmo operar com uma só pessoa.
Recua um passo e o tema simplifica-se. Um pipeline de conteúdo agêntico é apenas uma linha de montagem editorial feita de agentes de IA: pesquisar, redigir, verificar, traduzir, publicar, com um orquestrador a manter a ordem e uma pessoa a vigiar marca, factos e lei. Bate um só prompt não porque o modelo de base seja mais esperto, mas porque o trabalho é dividido, conferido e sequenciado como qualquer operação de publicação séria já o divide. Usa um onde publiques com frequência suficiente para justificar o custo, mantém uma pessoa nos controlos que carregam o risco real, e obténs o volume e a consistência que antes exigiam uma equipa inteira.
Leituras relacionadas
- Como humanizar conteúdo de IA em 2026: a camada editorial que mantém a saída do pipeline a soar a uma pessoa.
- Como posicionar com conteúdo gerado por IA sem penalização: a linha do abuso de conteúdo em escala em linguagem clara.
- O calendário de conteúdo para um negócio individual: a cadência de publicação para a qual um pipeline é construído.
- Conteúdo traduzido e SEO: porque a fase de localização tem de ser uma reescrita, não uma troca de palavras.
Referências e fontes
Artigo também disponível em: