Warum Ihre robots.txt plötzlich drei Jahre veraltet ist
2023 brauchten Sie eine Zeile für GPTBot. 2026 braucht eine moderne robots.txt Regeln für ein Dutzend KI-Bots — und der alte Rat „alle KI blockieren“ ist jetzt schädlich.
Wenn Sie eine kleine Seite betreiben, ist die Wahrscheinlichkeit hoch, dass Ihre robots.txt seit dem Hinzufügen einer einzigen GPTBot-Regel im Jahr 2023 nicht mehr angefasst wurde — oder dass Sie sie nie angefasst haben. Diese Lücke zählt heute mehr als früher. Bis Mitte 2025 zeigten Cloudflares Netzwerkdaten, dass das trainingsbezogene Crawling auf rund 80 % der gesamten KI-Bot-Aktivität gewachsen war, gegenüber 72 % ein Jahr zuvor.[3] KI-Crawler sind heute ein bedeutender Teil derer, die täglich an die Tür Ihres Servers klopfen, und die Regeln, die Sie ihnen geben, entscheiden über zwei sehr verschiedene Dinge: ob Ihr Inhalt das Modell eines anderen kostenlos trainiert, und ob Sie erscheinen, wenn ein Käufer ChatGPT oder Perplexity etwas fragt.
Was 2026 wirklich anders macht: Die großen KI-Anbieter haben ihren einzigen Crawler in mehrere aufgeteilt. OpenAI betreibt nicht mehr einen Bot — es betreibt GPTBot fürs Training, OAI-SearchBot für ChatGPT Search und ChatGPT-User für Abrufe auf Anfrage. Anthropic betreibt drei. Die praktische Folge: Der instinktive Griff zu Disallow: / für jeden KI-User-Agent erledigt nun zwei Aufgaben auf einmal. Er meldet Sie von Trainings-Korpora ab (oft gewollt) und löscht Sie aus KI-Suchantworten (fast nie gewollt). Die Analyse von Digital Applied zu Anthropics Rahmenwerk berichtet, dass rund 71 % der großen Nachrichtenverlage mindestens einen Retrieval- oder Such-Bot blockieren, häufig in der Absicht, nur das Training zu blockieren.[5] Genau diesen teuren Fehler soll dieser Leitfaden verhindern.
Der eine Satz, der das ganze Thema erklärt
Was llms.txt ist — und warum sie wahrscheinlich wenig bewirkt
Eine vernünftige Idee mit kaum Adoptionsnachweisen dahinter. Veröffentlichen Sie eine, wenn es günstig ist; bauen Sie keine Strategie darauf.
llms.txt ist eine von der Community vorgeschlagene Markdown-Datei, die Sie im Stammverzeichnis Ihrer Domain (/llms.txt) ablegen und die Ihre wichtigsten Seiten in sauberer, parsbarer Form auflistet, damit ein großes Sprachmodell Ihren besten Inhalt findet und versteht, ohne sich durch Navigation, Werbung und Skripte zu wühlen. Vorgeschlagen wurde sie von Jeremy Howard von Answer.AI im September 2024. Die übliche Analogie lautet „eine Sitemap für LLMs“, und die Absicht ist durchaus sinnvoll: den Modellen eine kuratierte, rauscharme Karte dessen geben, was auf Ihrer Seite zählt, optional mit einer ausführlicheren /llms-full.txt, die den eigentlichen Inhalt einbettet.
Das Problem ist die Kluft zwischen Idee und Beleg. Nach achtzehn Monaten Branchendiskussion sind die Daten ernüchternd:
- Die Adoption liegt bei etwa einer von zehn Seiten. Die SE-Ranking-Studie über 300.000 Domains fand eine Adoptionsrate von 10,13 %, und entscheidend: Die Adoption war über niedrige, mittlere und hohe Traffic-Stufen nahezu identisch (~9–10 % je) — es sind also nicht die ausgefeilten Seiten, die vorausstürmen.[1]
- Kein messbarer Zitat-Zuwachs. Dieselbe SE-Ranking-Analyse fand keinen statistisch signifikanten Unterschied in der Häufigkeit von KI-Zitaten zwischen Seiten mit und ohne llms.txt. Ein auf KI-Zitatdaten trainiertes Modell verbesserte sich sogar, als die llms.txt-Variable entfernt wurde.[1]
- Fast nichts liest sie. Limy.AI überwachte über 500 Millionen KI-Bot-Ereignisse in 90 Tagen und fand nur 408 Anfragen, die direkt auf llms.txt zielten.[14] Search Engine Land verfolgte 10 Seiten 90 Tage vor und nach Hinzufügen der Datei; nur zwei verzeichneten KI-Traffic-Zuwächse, und nicht wegen der Datei.[2]
- Keine offizielle Unterstützung. Stand Mitte 2026 hat weder OpenAI noch Anthropic, Google oder Perplexity offiziell bestätigt, dass seine Systeme llms.txt lesen oder befolgen. Sie bleibt eine Community-Spezifikation, kein etablierter Standard.
llms.txt: die Realität von Adoption vs. Wirkung
Eine von zehn Seiten hat sie; der messbare Nutzen bislang ist nahezu null[1][14]
Dies ist kein Argument dagegen, jemals eine llms.txt zu veröffentlichen — sie kostet fast nichts und ist zukunftskompatibel, falls Plattformen die Unterstützung später formalisieren. Es ist ein Argument dagegen, sie als Wachstumshebel zu behandeln. Investieren Sie die zehn Minuten, wenn Sie möchten; verschwenden Sie kein Strategiemeeting darauf.
Die ehrliche Einschätzung für eine kleine Seite
robots.txt. Das ist die, der die Crawler tatsächlich gehorchen, und die entscheidet, ob Sie in den Antworten Ihrer Kunden stehen (oder nicht).robots.txt vs. llms.txt: der ehrliche Vergleich
Dasselbe Stammverzeichnis, völlig andere Befugnisse. Das eine ist durchsetzbar; das andere eine höfliche Bitte, die niemand lesen muss.
| Dimension | robots.txt | llms.txt |
|---|---|---|
| Was es ist | Eine Zugriffskontrolldatei, die Crawlern sagt, was sie abrufen dürfen und was nicht | Eine Kuratierungsdatei in Markdown, die Ihre besten Seiten auflistet, damit ein LLM sie findet und parst |
| Alter & Status | Robots Exclusion Protocol — ein ~30 Jahre alter Webstandard, jetzt ein IETF-RFC | Ein Community-Vorschlag von Sept. 2024 (Jeremy Howard / Answer.AI). Kein offizieller Standard |
| Speicherort | /robots.txt im Stammverzeichnis Ihrer Domain | /llms.txt im Stammverzeichnis Ihrer Domain (optional eine ausführlichere /llms-full.txt) |
| Durchsetzung | Von allen großen KI-Crawlern beachtet (außer einigen wie Bytespider) | Nur beratend — kein Crawler ist verpflichtet, sie zu lesen oder zu befolgen |
| Wer es wirklich nutzt | OpenAI, Anthropic, Perplexity, Google und Common Crawl lesen sie alle | Keine große KI-Plattform hat offiziell bestätigt, llms.txt zu lesen (Mitte 2026) |
| Gemessene Wirkung | Steuert direkt, ob ein Bot einen Pfad crawlen darf | Die 300k-Domain-Studie von SE Ranking fand keinen signifikanten Zitat-Zuwachs |
| Was es nicht kann | Kann einen nicht-konformen Bot nicht stoppen und steuert die AI Overviews nicht (Googlebot-Index) | Kann nichts blockieren — es ist ein Vorschlag, kein Tor |
| Lohnt es sich 2026? | Ja — das ist Ihr echter Hebel. Halten Sie sie mit der Botliste von 2026 aktuell | Geringe Kosten, geringes Risiko, geringer Nutzen. Veröffentlichen Sie sie, wenn es günstig ist; erwarten Sie keinen Traffic davon |
Die Erkenntnis ist nicht „llms.txt ist nutzlos“ — sondern dass die beiden Dateien nicht austauschbar sind und diejenige, die heute wirklich Ergebnisse verändert, die langweilige, jahrzehntealte ist. Wenn Sie 2026 nur Zeit haben, eine Datei richtig zu machen, dann robots.txt, mit Regeln, die die aktuelle KI-Crawler-Landschaft widerspiegeln und nicht die Version von 2023.
Der KI-Crawler-Zoo von 2026: Wer Sie wirklich besucht
Jede KI-Engine betreibt ihren eigenen Crawler — und die meisten betreiben zwei oder drei, jeder mit einer anderen Aufgabe und einer anderen richtigen Antwort.
Bevor Sie eine sinnvolle Regel schreiben können, müssen Sie wissen, wofür jeder Bot da ist. Jeder KI-Crawler erledigt eine von drei Aufgaben: Er sammelt Seiten fürs Modelltraining, indexiert Seiten für KI-Suchantworten, oder ruft eine Seite in Echtzeit ab, weil ein Nutzer den Assistenten gerade jetzt danach gefragt hat. Das sind unterschiedliche kommerzielle Beziehungen, und 2026 legen die großen Anbieter sie endlich als unterschiedliche Bots offen, die Sie unabhängig steuern können.
Die Bots, die Sie am häufigsten sehen
| Bot | Eigentümer | Zweck | robots.txt? | Standardentscheidung 2026 |
|---|---|---|---|---|
GPTBot | OpenAI | Training — speist künftige GPT-Modelle | Ja | Blockieren, wenn Sie keine Modelle gratis trainieren wollen; erlauben für maximale künftige Reichweite |
OAI-SearchBot | OpenAI | Indexiert Seiten für ChatGPT Search | Ja | ERLAUBEN — Blockieren entfernt Sie aus den Antworten von ChatGPT Search |
ChatGPT-User | OpenAI | Abruf auf Anfrage, wenn ein Nutzer Ihre URL öffnet | Ja | ERLAUBEN — Blockieren bricht einen Abruf ab, den der Nutzer angefordert hat |
ClaudeBot | Anthropic | Training — speist Claudes Vortrainings-Korpus | Ja | Blockieren, um sich dem Training zu entziehen; der extraktivste Crawler nach dem Crawl-to-Referral-Verhältnis |
Claude-SearchBot | Anthropic | Indexiert Seiten für Claudes Websuche-Tool | Ja | ERLAUBEN — so zitiert Claude Sie (neu in 2026) |
PerplexityBot | Perplexity | Indexiert Seiten, damit Perplexity sie zitieren kann | Ja (mit Vorbehalt beim Stealth-Crawling) | ERLAUBEN — Perplexity ist die zitierfreundlichste Engine für kleine Seiten |
Google-Extended | Steuer-Token — regelt die Nutzung bereits gecrawlter Seiten zum Training von Gemini/Vertex | Ja (es ist ein Token, kein echter Bot — nie in Ihren Logs) | Optionales Abmelden vom Gemini-Training. Steuert NICHT die AI Overviews — nutzen Sie dafür das neue GSC-Opt-out | |
CCBot | Common Crawl | Öffentlicher Korpus, der viele Modell-Trainer speist | Ja | Blockieren, um aus dem offenen Korpus herauszubleiben; harmlos, wenn erlaubt |
Bytespider | ByteDance | Training — speist Doubao | Nein — dokumentierte Nichteinhaltung | Auf WAF-/IP-Ebene blockieren — robots.txt allein stoppt ihn nicht |
Zwei Zeilen verdienen einen zweiten Blick. Google-Extended ist gar kein echter Crawler — es ist ein Steuer-Token, das nie als HTTP-Anfrage in Ihren Server-Logs auftaucht. Es regelt nur, ob Google Seiten, die es bereits (mit dem normalen Googlebot) gecrawlt hat, zum Training von Gemini und Vertex AI verwenden darf. Und Bytespider (ByteDance) hat eine dokumentierte Vorgeschichte, robots.txt uneinheitlich zu ignorieren, weshalb das Blockieren eine Firewall- oder IP-Regel statt eines höflichen Disallow erfordert.
Die Unterscheidung, die die ganze Arbeit leistet
GPTBot ist nicht OAI-SearchBot. ClaudeBot ist nicht Claude-SearchBot. Behandeln Sie sie als einen Topf und Sie löschen sich aus dem am schnellsten wachsenden Verweis-Kanal des Jahres.
Die Ökonomie: Traffic-Verlust vs. Zitat-Verlust
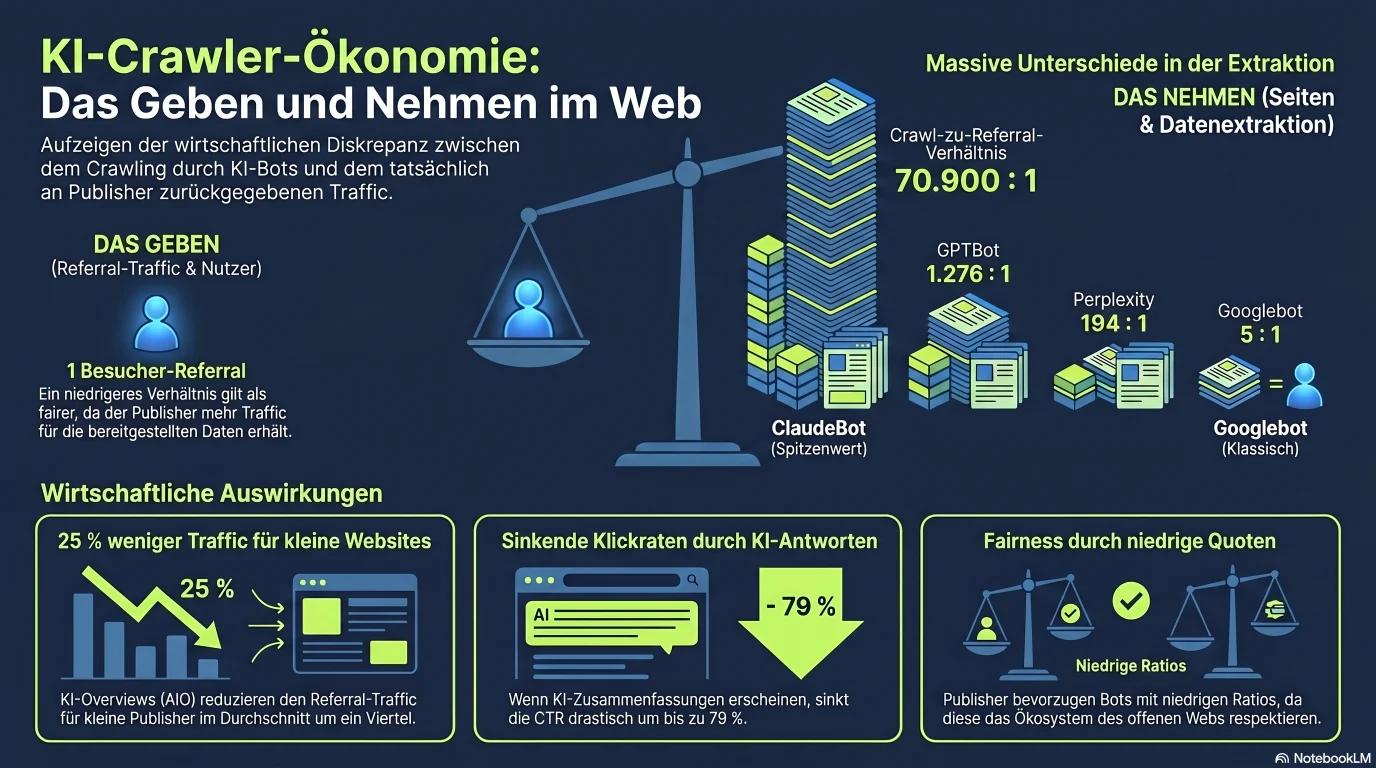
Die Entscheidung blockieren oder erlauben ist in Wahrheit ein Abwägen zwischen zwei Arten von Verlust. Cloudflares Crawl-to-Referral-Verhältnis ist die Zahl, die das einrahmt.
Das geschäftliche Argument für das Blockieren von Trainings-Crawlern läuft auf ein einziges Verhältnis hinaus: wie viele Ihrer Seiten ein Bot crawlt für jeden Besucher, den er zurückschickt. Cloudflare veröffentlicht dieses Crawl-to-Referral-Verhältnis über sein Netzwerk, und die Spannweite zwischen Anbietern ist außergewöhnlich. Der traditionelle Googlebot liegt bei etwa 5 gecrawlten Seiten pro Referral. Anthropics ClaudeBot crawlte auf seinem Höchststand im Juni 2025 rund 70.900 Seiten für jeden Besucher, den er zurückverwies — eine Asymmetrie, die den Trainingszugang als einseitige Wertextraktion neu rahmt.[5]
Crawl-to-Referral-Verhältnis — gecrawlte Seiten pro zurückgeschicktem Besucher
Niedriger ist fairer für Verlage. Trainings-Crawler nehmen weit mehr, als sie geben[3][5][9]
Die Balken liegen auf einer einzigen linearen Skala, deshalb wirkt alles unter ClaudeBot winzig — das ist der Punkt. ClaudeBots Höchststand (~70.900:1) und GPTBot (1.276:1) lassen Googlebot (~5:1) und DuckDuckGo (~1,5:1) verschwinden. Bis Juli 2025 hatte sich Anthropic auf ~38.000:1 verbessert und Perplexity lag bei 194:1, doch die Kluft bleibt enorm.
Doch es gibt einen Haken, der „blockieren Sie einfach die Trainings-Bots“ daran hindert, gratis zu sein, und es ist die wichtigste Nuance dieses ganzen Artikels. Das Blockieren hat Nebenwirkungen auf Zitate. AuthorityTechs Analyse von 2026 fand, dass Seiten, die Google-Extended blockieren, deutlich seltener von generativen Engines zitiert werden — sogar in AI Overviews, wo Google technisch über den normalen Index Zugriff auf den Inhalt behält.[11] Und die Daten von ppc.land zeigen, dass das Blockieren auch in die andere Richtung durchlässig ist: KI-Crawler zu blockieren stoppt Zitate nicht zuverlässig, weil Engines aus alternativen Pfaden, Zitaten Dritter und zwischengespeicherten Kopien schöpfen.[10] Sie können den Sichtbarkeitsvorteil verlieren, ohne die Privatsphäre, für die Sie blockiert haben, ganz zu gewinnen.
Auf der anderen Seite der Waage steht der Traffic-Schaden, der die Leute überhaupt erst zum Blockieren treibt. Googles AI Overviews haben den Verweis-Traffic messbar gesenkt: Digital Content Next berichtet Traffic-Rückgänge von 1–25 % für Mitglieder, im Schnitt rund 25 %, und die Klickraten fallen je nach Anfragetyp um 34,5 % bis 79 %, wenn ein AI Overview erscheint.[8] Von ppc.land befragte Verlage erwarten in den nächsten drei Jahren einen weiteren Traffic-Rückgang von 43 %.[10] Wenn die KI Ihren Traffic nimmt und Sie zugleich 70.000 zu 1 crawlt, ist der Drang, die Zugbrücke hochzuziehen, verständlich.
Was AI Overviews dem Traffic kleiner Seiten antun
Der Schaden, der Betreiber zum Blockieren treibt — und warum die Entscheidung dringlich wirkt[8][10]
Rund ein Viertel der Top-1000-Seiten blockiert inzwischen GPTBot. Aber beachten Sie, was das alleinige Blockieren von GPTBot nicht tut: Es entfernt Sie nicht aus den AI Overviews (anderer Index) und hindert ChatGPT Search nicht daran, Sie zu zitieren (das ist OAI-SearchBot). Der Traffic-Schaden und der Crawler, den Sie blockieren, hängen oft nicht einmal zusammen.
Der KI-Crawler-Anteil konsolidiert sich um zwei Akteure
GPTBot und ClaudeBot haben ihren Anteil am KI-Crawling mehr als verdoppelt; Bytespider brach ein[3]
Zwischen 2024 und Mitte 2025 stieg GPTBots Anteil am KI-Crawling von 4,7 % auf 11,7 % und ClaudeBot von 6 % auf ~10 %, während ByteDances Bytespider von 14,1 % auf 2,4 % fiel. Im Mai 2026 tauchte Anthropics dedizierter Claude-SearchBot mit 2,00 % Anteil auf — das erste Mal, dass der Such-Crawler eines großen Anbieters als eigenständiger, beachtlicher Akteur erschien.
Googles neues Opt-out — und warum Google-Extended es nicht ist
Die Steuerung, die Verlage seit zwei Jahren wollten, kam endlich im Juni 2026. Sie ist nicht dasselbe wie Google-Extended, und der Unterschied zählt.
Zwei Jahre lang war die meistgestellte Frage zu KI-Crawlern eine Variante von: „Wie erscheine ich in der normalen Google-Suche, aber nicht in den AI Overviews?“ Bis Juni 2026 lautete die ehrliche Antwort „gar nicht“. Google-Extended — das Token, zu dem die meisten griffen — steuert nur, ob Google Gemini und Vertex AI mit Ihren bereits gecrawlten Seiten trainiert. Es hat nie die AI Overviews oder den AI Mode gesteuert, die den Standard-Googlebot-Index nutzen. Google-Extended zu blockieren tat nichts, um Sie aus den KI-Zusammenfassungen herauszuhalten, die tatsächlich Ihre Klicks fraßen.[8]
Das änderte sich am 3. Juni 2026, als Google einen KI-Leistungsbericht in der Search Console zusammen mit einem Opt-out-Schalter einführte, mit dem Verlage Inhalte aus AI Overviews und AI Mode entfernen können, ohne das Standard-Such-Ranking zu verlieren.[6] Die Einstellung wird am 17. Juni 2026 wirksam, wenn Google beginnt, das Signal zu befolgen, und ihre Aktivierung beeinflusst Ihre Position in den normalen Google-Ergebnissen nicht.[7] Zwei Vorbehalte zum zweimaligen Lesen: Die eigenständige Gemini-App ist ausgeschlossen von diesem Opt-out (sie ist ein separates Produkt), und sich abzumelden bedeutet zu akzeptieren, dass auch die Zitate/Sichtbarkeit verschwinden, die Sie aus den AIO erhielten.
Was welcher Google-Hebel tut
- Google-Extended (robots.txt-Token) → Abmeldung vom Gemini-/Vertex-Training. Entfernt Sie nicht aus den AI Overviews.
- GSC-KI-Opt-out-Schalter (wirksam 17. Juni 2026) → entfernt Inhalte aus AI Overviews und AI Mode, behält das normale Ranking. Schließt die Gemini-App aus.
- Disallow Googlebot → nukleare Option; entfernt Sie ganz aus Google, einschließlich der normalen Suche, die echte Klicks liefert. Fast nie die richtige Wahl.
Die empfohlene Standardkonfiguration für 2026
Drei Profile, eine Entscheidung. Wählen Sie das, das zu Ihrem Ziel passt, und kopieren Sie die robots.txt unten.
Es gibt nicht die eine richtige Konfiguration — es gibt eine richtige Konfiguration für Ihr Ziel. Hier sind die drei Profile, die fast jede kleine Seite abdecken, von „ich will in jeder Antwort sein“ bis „halte mich ganz aus KI heraus“.
| Profil | Für wen | Trainings-Bots | Such-Bots | Warum |
|---|---|---|---|---|
| Maximale Sichtbarkeit | Die meisten kleinen Seiten, Blogs, lokale Unternehmen | Alle erlauben | Alle erlauben | Sie wollen in jeder Antwort sein. Die Bandbreitenkosten sind im kleinen Maßstab vernachlässigbar, und das Blockieren des Trainings hat messbare Nebenwirkungen auf Zitate. |
| Training blockieren, Zitate behalten | Verlage, Seiten mit Originalforschung, alle, die einseitige Extraktion ablehnen | GPTBot, ClaudeBot, Google-Extended, CCBot, Applebot-Extended, Bytespider (WAF) blockieren | OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User, Claude-User erlauben | Die Konsens-Voreinstellung von 2026 für Content-Unternehmen: die einseitige Extraktion stoppen, den Zitat-Kanal offen halten. |
| Vollständig raus aus KI-Antworten | Bezahlte, mitgliedergebundene oder rechtlich heikle Inhalte | Alle Trainings-Bots blockieren | Alle Such-/Antwort-Bots blockieren + das neue GSC-KI-Opt-out aktivieren (wirksam 17. Juni 2026) | Sie nehmen den Zitat-Verlust in Kauf, um Inhalte aus KI-Oberflächen herauszuhalten. Das normale Google-Ranking wird vom GSC-Schalter nicht beeinflusst. |
Für die meisten kleinen Seiten lautet die ehrliche Empfehlung Profil 1 — alles erlauben. Ihr Ziel ist Sichtbarkeit, die Bandbreitenkosten des KI-Crawlings sind im kleinen Maßstab vernachlässigbar, und das Blockieren von Trainings-Crawlern bringt Nebenwirkungen auf Zitate mit sich, die Sie nicht vollständig vorhersagen können. Das Profil „Training blockieren, Zitate behalten“ (Profil 2) ist die richtige Voreinstellung für Content-Unternehmen, Verlage und alle, die Originalforschung veröffentlichen und einseitige Extraktion wirklich ablehnen. Profil 3 ist nur für bezahlte, mitgliedergebundene oder rechtlich heikle Inhalte.
Dies ist die Konsens-Konfiguration von 2026 für eine Content-Seite, die das kostenlose Training stoppen und doch in der KI-Suche zitierbar bleiben will. Fügen Sie sie in /robots.txt ein und ergänzen Sie die Firewall-Regel für Bytespider separat (er ignoriert robots.txt).
# --- TRAININGS-Crawler blockieren ---
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# --- Such-/Antwort-Crawler ERLAUBEN (so werden Sie zitiert) ---
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
# --- Alles andere ---
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xmlHinweise: Ersetzen Sie example.com durch Ihre Domain. Bytespider braucht eine WAF- oder IP-Sperre auf Serverebene — ein Disallow stoppt ihn nicht zuverlässig. Und denken Sie daran: Google-Extended blockiert hier nur das Gemini-Training; um die AI Overviews zu verlassen, nutzen Sie das neue Search-Console-Opt-out (wirksam 17. Juni 2026), nicht diese Datei.
Crawler-Hygiene öffnet die Tür — Inhalt macht es wert, hindurchzugehen
Wie Sie sehen, welche Bots Sie wirklich besuchen
Bevor Sie etwas blockieren, sehen Sie sich Ihre Logs an. Vielleicht optimieren Sie für einen Crawler, der nie kommt — oder blockieren einen, der all Ihre Zitate antreibt.
Im Dunkeln geschriebene Regeln sind Rätselraten. Investieren Sie zwanzig Minuten, um zu sehen, wer Sie wirklich crawlt, bevor Sie eine einzige Zeile ändern, denn die Bot-Landschaft variiert je nach Nische enorm. Hier ist der praktische Monitoring-Stack, vom Günstigsten zum Übrigen:
- Server-/CDN-Zugriffslogs. Filtern Sie nach User-Agent für
GPTBot,OAI-SearchBot,ChatGPT-User,ClaudeBot,Claude-SearchBot,PerplexityBot,CCBotundBytespider. Das zeigt Ihnen Häufigkeit und welche Seiten jeder Bot anfasst. Hinweis:Google-Extendederscheint nie — es ist ein Token, keine Anfrage. - Cloudflare Radar AI Insights. Wenn Sie hinter Cloudflare sind, zeigt das kostenlose AI-Insights-Dashboard die KI-Crawler-Aktivität und die in diesem Artikel zitierten Crawl-to-Referral-Daten.
- Google Search Console. Der neue KI-Leistungsbericht (Juni 2026) ist der Ort, wo Sie die Impressionen von AI Overviews / AI Mode sehen — und wo der Opt-out-Schalter sitzt.
- Authentizität prüfen. Gefälschte User-Agents sind verbreitet. Gleichen Sie verdächtige Zugriffe mit den veröffentlichten IP-Bereichen ab — OpenAI listet sie unter
openai.com/gptbot.json,openai.com/searchbot.jsonundopenai.com/chatgpt-user.json.
Der 30-Minuten-Crawler-Hygiene-Check
- Ziehen Sie die Zugriffslogs des letzten Monats; listen Sie jeden KI-User-Agent, der Sie besucht hat, und wie oft.
- Öffnen Sie Ihre aktuelle
robots.txt. Erwähnt sie noch nur GPTBot? Aktualisieren Sie sie auf die Botliste von 2026 mit dem Profil, das zu Ihrem Ziel passt. - Stellen Sie sicher, dass Sie
OAI-SearchBot,Claude-SearchBotoderPerplexityBotnicht versehentlich blockieren — das ist der Fehler der 71 % der Verlage. - Fügen Sie eine WAF-Regel für Bytespider hinzu, falls Ihre Logs zeigen, dass er Ihre robots.txt ignoriert.
- Entscheiden Sie über die AI Overviews separat: lassen Sie sie, oder nutzen Sie das GSC-Opt-out ab dem 17. Juni 2026. Erwarten Sie nicht, dass Google-Extended diese Arbeit erledigt.
- Veröffentlichen Sie optional eine
llms.txt, falls Ihr Stack sie erzeugt — und vergessen Sie sie dann und schreiben Sie Inhalte.
→ Tun Sie es jetzt: Öffnen Sie https://ihre-domain.com/robots.txt in einem Browser. Erwähnt sie weder OAI-SearchBot noch Claude-SearchBot, ist sie veraltet — und Sie sind womöglich unsichtbar für genau die KI-Suchprodukte, die Ihre Kunden nutzen. Wählen Sie ein Profil aus der Tabelle oben, fügen Sie die passende Konfiguration ein, und Sie haben mehr Crawler-Hygiene betrieben als die überwältigende Mehrheit kleiner Seiten in 2026.
Verwandte Beiträge
- AEO vs. SEO 2026: warum Antwort-Engines die neue Suche sind — sobald die Such-Bots Sie lesen können, gewinnen Sie so wirklich das Zitat.
- AI Overviews & SGE: wie kleine Seiten weiterhin Klicks gewinnen — die Traffic-Schadensdaten hinter der Opt-out-Entscheidung.
- Schema-Markup für kleine Unternehmen — die strukturierten Daten, die den hereingelassenen Crawlern helfen, Ihre Seiten zu verstehen.
- Technisches SEO für Nicht-Entwickler — robots.txt, Sitemaps und der Rest der Klempnerei, in klarer Sprache.
Quellen & Belege
Artikel auch verfügbar auf: