Porque o seu robots.txt está de repente três anos desatualizado
Em 2023 bastava uma linha para o GPTBot. Em 2026 um robots.txt moderno precisa de regras para uma dúzia de bots de IA — e o velho conselho de «bloquear toda a IA» é agora contraproducente.
Se gere um site pequeno, há boas hipóteses de o seu robots.txt não ser tocado desde que adicionou uma única regra para o GPTBot em 2023 — ou de nunca o ter tocado. Essa lacuna importa mais do que antes. Em meados de 2025, os dados de rede da Cloudflare mostraram que o rastreio ligado ao treino tinha crescido para cerca de 80% de toda a atividade de bots de IA, face a 72% um ano antes.[3] Os rastreadores de IA são já uma fatia significativa de quem bate à porta do seu servidor todos os dias, e as regras que lhes der decidem duas coisas muito diferentes: se o seu conteúdo treina de graça o modelo de outra pessoa, e se aparece quando um comprador faz uma pergunta ao ChatGPT ou à Perplexity.
O que torna 2026 genuinamente diferente é que os grandes fornecedores de IA dividiram o seu rastreador único em vários. A OpenAI já não opera um só bot — opera o GPTBot para treino, o OAI-SearchBot para o ChatGPT Search e o ChatGPT-User para buscas sob demanda. A Anthropic opera três. A consequência prática: o reflexo de Disallow: / para cada user-agent de IA faz agora dois trabalhos ao mesmo tempo. Tira-o dos corpora de treino (muitas vezes o que queria) e apaga-o das respostas de busca de IA (quase nunca o que queria). A análise da Digital Applied ao quadro da Anthropic relata que cerca de 71% dos grandes editores de notícias bloqueiam pelo menos um bot de recuperação ou busca, frequentemente com a intenção de bloquear apenas o treino.[5] É exatamente o erro caro que este guia foi feito para evitar.
A frase que explica todo o tema
O que é o llms.txt — e porque provavelmente fará pouco
Uma ideia razoável com quase nenhuma prova de adoção por trás. Publique-o se for barato; não construa uma estratégia sobre ele.
O llms.txt é um ficheiro Markdown proposto pela comunidade que coloca na raiz do seu domínio (/llms.txt) e que lista as suas páginas mais importantes de forma limpa e analisável, para que um modelo de linguagem de grande dimensão encontre e compreenda o seu melhor conteúdo sem atravessar navegação, anúncios e scripts. Foi proposto por Jeremy Howard, da Answer.AI, em setembro de 2024. A analogia habitual é «um sitemap para LLMs», e a intenção é genuinamente sensata: dar aos modelos um mapa curado e de baixo ruído do que importa no seu site, opcionalmente com um /llms-full.txt mais completo que incorpora o conteúdo real.
O problema é a distância entre a ideia e a evidência. Após dezoito meses de conversa no setor, os dados são sóbrios:
- A adoção é de cerca de um em cada dez sites. O estudo da SE Ranking com 300.000 domínios encontrou uma taxa de adoção de 10,13%, e, crucialmente, a adoção foi quase idêntica nos níveis de tráfego baixo, médio e alto (~9–10% cada) — por isso não são os sites sofisticados que correm à frente.[1]
- Sem aumento mensurável de citações. A mesma análise da SE Ranking não encontrou diferença estatisticamente significativa na frequência de citações de IA entre sites com e sem llms.txt. Um modelo treinado com dados de citações de IA até melhorou quando a variável llms.txt foi removida.[1]
- Quase nada o lê. A Limy.AI monitorizou mais de 500 milhões de eventos de bots de IA em 90 dias e encontrou apenas 408 pedidos dirigidos diretamente ao llms.txt.[14] A Search Engine Land seguiu 10 sites 90 dias antes e depois de adicionar o ficheiro; só dois viram aumentos de tráfego de IA, e não por causa do ficheiro.[2]
- Sem suporte oficial. Em meados de 2026, nem a OpenAI, nem a Anthropic, nem a Google, nem a Perplexity confirmaram oficialmente que os seus sistemas leem ou agem sobre o llms.txt. Continua a ser uma especificação da comunidade, não um padrão adotado.
llms.txt: a realidade de adoção vs impacto
Um em cada dez sites tem-no; o benefício mensurável até agora é quase zero[1][14]
Isto não é um argumento contra publicar alguma vez um llms.txt — custa quase nada e é compatível com o futuro se as plataformas formalizarem o suporte. É um argumento contra tratá-lo como uma alavanca de crescimento. Dedique-lhe os dez minutos se quiser; não lhe dedique uma reunião de estratégia.
A opinião honesta para um site pequeno
robots.txt. É esse que os rastreadores obedecem de facto, e é esse que decide se está (ou não) nas respostas que os seus clientes estão a ler.robots.txt vs llms.txt: a comparação honesta
Mesmo diretório raiz, poderes completamente diferentes. Um é aplicável; o outro é um pedido cortês que ninguém é obrigado a ler.
| Dimensão | robots.txt | llms.txt |
|---|---|---|
| O que é | Um ficheiro de controlo de acesso que diz aos rastreadores o que podem e não podem descarregar | Um ficheiro de curadoria em Markdown que lista as suas melhores páginas para um LLM as encontrar e analisar |
| Idade e estatuto | Robots Exclusion Protocol — um padrão web de ~30 anos, agora um RFC do IETF | Uma proposta da comunidade de set 2024 (Jeremy Howard / Answer.AI). Não é um padrão oficial |
| Localização | /robots.txt na raiz do seu domínio | /llms.txt na raiz do seu domínio (opcionalmente um /llms-full.txt mais completo) |
| Aplicação | Respeitado por todos os grandes rastreadores de IA (exceto alguns como o Bytespider) | Apenas consultivo — nenhum rastreador é obrigado a lê-lo ou a agir sobre ele |
| Quem o consome de facto | OpenAI, Anthropic, Perplexity, Google e Common Crawl leem-no | Nenhuma grande plataforma de IA confirmou oficialmente que lê o llms.txt (meados de 2026) |
| Impacto medido | Controla diretamente se um bot pode rastrear um caminho | O estudo de 300 mil domínios da SE Ranking não encontrou aumento significativo de citações |
| O que não pode fazer | Não pode travar um bot incumpridor e não controla os AI Overviews (índice do Googlebot) | Não pode bloquear nada — é uma sugestão, não um portão |
| Vale a pena em 2026? | Sim — é a sua verdadeira alavanca. Mantenha-o atualizado com a lista de bots de 2026 | Baixo custo, baixo risco, baixa recompensa. Publique-o se for barato; não espere tráfego dele |
A conclusão não é «o llms.txt é inútil» — é que os dois ficheiros não são intercambiáveis, e o que realmente muda resultados hoje é o aborrecido e antigo. Se em 2026 só tiver tempo de pôr um ficheiro em ordem, que seja o robots.txt, com regras que reflitam o panorama atual de rastreadores de IA e não a versão de 2023.
O zoo de rastreadores de IA de 2026: quem o visita
Cada motor de IA opera o seu próprio rastreador — e a maioria opera dois ou três, cada um com um trabalho distinto e uma resposta certa distinta.
Antes de escrever uma regra sensata, precisa de saber para que serve cada bot. Cada rastreador de IA faz um de três trabalhos: recolhe páginas para treinar modelos, indexa páginas para respostas de busca de IA, ou busca uma página em tempo real porque um utilizador perguntou ao assistente sobre ela agora mesmo. São relações comerciais distintas, e em 2026 os grandes fornecedores finalmente expõem-nas como bots distintos que pode controlar de forma independente.
Os bots que verá mais
| Bot | Proprietário | Propósito | robots.txt? | Decisão predefinida 2026 |
|---|---|---|---|---|
GPTBot | OpenAI | Treino — alimenta os futuros modelos GPT | Sim | Bloqueie se não quiser treinar modelos de graça; permita para o máximo alcance futuro |
OAI-SearchBot | OpenAI | Indexa páginas para o ChatGPT Search | Sim | PERMITIR — bloqueá-lo remove-o das respostas do ChatGPT Search |
ChatGPT-User | OpenAI | Busca sob demanda quando um utilizador abre o seu URL | Sim | PERMITIR — bloqueá-lo quebra uma busca que o utilizador pediu |
ClaudeBot | Anthropic | Treino — alimenta o corpus de pré-treino do Claude | Sim | Bloqueie para recusar o treino; é o rastreador mais extrativo pelo rácio crawl-to-referral |
Claude-SearchBot | Anthropic | Indexa páginas para a ferramenta de busca web do Claude | Sim | PERMITIR — é assim que o Claude o cita (novo em 2026) |
PerplexityBot | Perplexity | Indexa páginas para a Perplexity as poder citar | Sim (com ressalva de rastreio furtivo) | PERMITIR — a Perplexity é o motor mais favorável às citações para sites pequenos |
Google-Extended | Token de controlo — rege o uso de páginas já rastreadas para treinar o Gemini/Vertex | Sim (é um token, não um bot real — nunca nos seus logs) | Recusa opcional do treino do Gemini. NÃO controla os AI Overviews — use o novo opt-out do GSC para isso | |
CCBot | Common Crawl | Corpus público que alimenta muitos treinadores de modelos | Sim | Bloqueie para ficar fora do corpus aberto; inofensivo se permitido |
Bytespider | ByteDance | Treino — alimenta o Doubao | Não — incumprimento documentado | Bloqueie ao nível de WAF / IP — o robots.txt sozinho não o trava |
Duas linhas merecem uma segunda leitura. O Google-Extended não é de todo um rastreador real — é um token de controlo que nunca aparece nos seus logs de servidor como um pedido HTTP. Apenas rege se o Google pode usar páginas que já rastreou (com o Googlebot normal) para treinar o Gemini e o Vertex AI. E o Bytespider (ByteDance) tem um historial documentado de ignorar o robots.txt de forma inconsistente, razão pela qual bloqueá-lo requer uma regra de firewall ou ao nível de IP em vez de um cortês Disallow.
A distinção que faz todo o trabalho
GPTBot não é o OAI-SearchBot. O ClaudeBot não é o Claude-SearchBot. Trate-os como um único grupo e apaga-se do canal de referência que mais cresce no ano.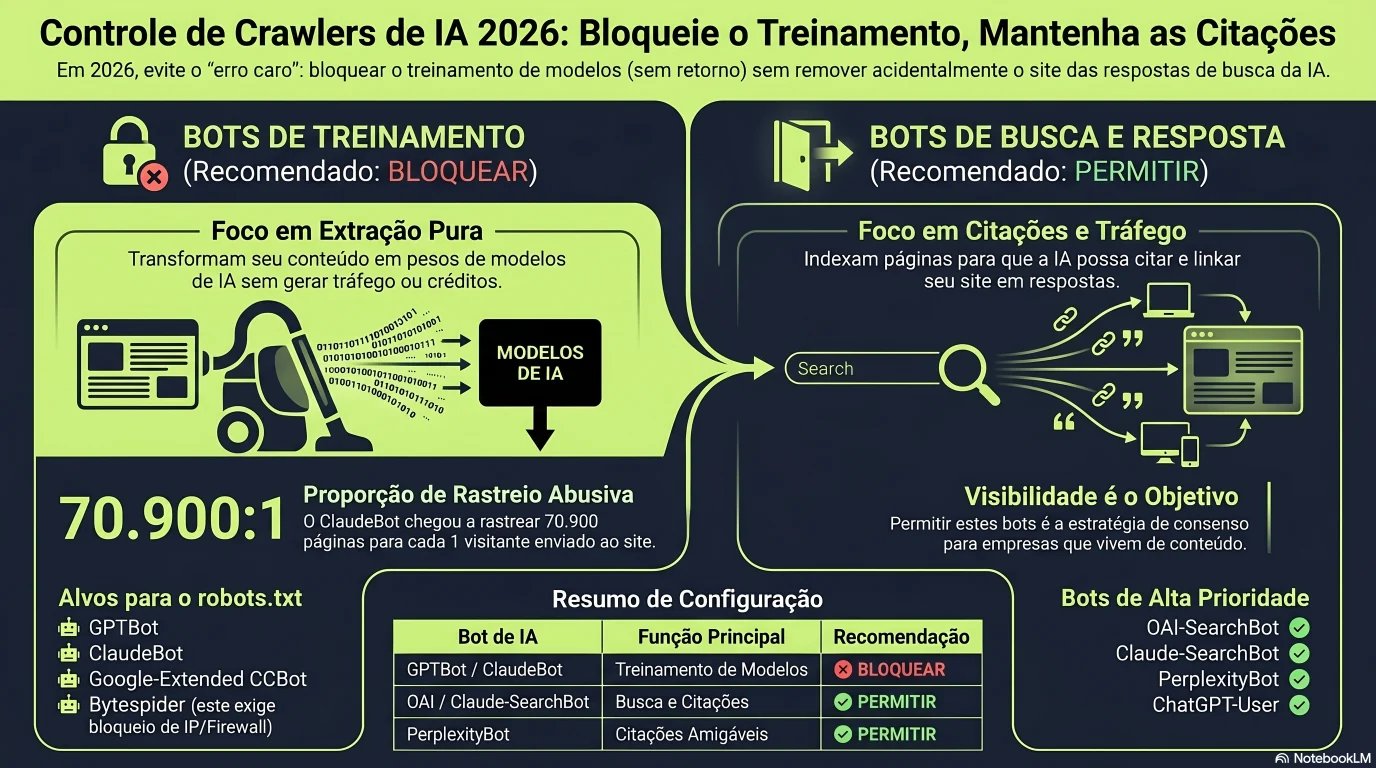
A economia: perda de tráfego vs perda de citações
A decisão de bloquear ou permitir é na verdade um compromisso entre dois tipos de perda. O rácio crawl-to-referral da Cloudflare é o número que o enquadra.
O argumento de negócio para bloquear os rastreadores de treino resume-se a um único rácio: quantas das suas páginas um bot rastreia por cada visitante que lhe envia de volta. A Cloudflare publica este rácio crawl-to-referral na sua rede, e a dispersão entre fornecedores é extraordinária. O Googlebot tradicional ronda as 5 páginas rastreadas por referral. O ClaudeBot da Anthropic, no seu pico de junho de 2025, rastreava cerca de 70.900 páginas por cada visitante que referia de volta — uma assimetria que reformula o acesso de treino como uma extração de valor unilateral.[5]
Rácio crawl-to-referral — páginas rastreadas por 1 visitante enviado de volta
Quanto mais baixo, mais justo para o editor. Os rastreadores de treino levam muito mais do que dão[3][5][9]
As barras estão numa única escala linear, por isso tudo o que está abaixo do ClaudeBot parece minúsculo — esse é o ponto. O pico do ClaudeBot (~70.900:1) e o GPTBot (1.276:1) empequenecem o Googlebot (~5:1) e o DuckDuckGo (~1,5:1). Em julho de 2025 a Anthropic tinha melhorado para ~38.000:1 e a Perplexity estava em 194:1, mas a diferença continua enorme.
Mas há uma armadilha que impede que «basta bloquear os bots de treino» seja gratuito, e é a nuance mais importante de todo este artigo. O bloqueio tem efeitos secundários nas citações. A análise da AuthorityTech de 2026 concluiu que os sites que bloqueiam o Google-Extended têm muito menos probabilidade de serem citados pelos motores generativos — mesmo nos AI Overviews, onde o Google tecnicamente mantém o acesso ao conteúdo através do índice normal.[11] E os dados da ppc.land mostram que o bloqueio é poroso também na outra direção: bloquear rastreadores de IA não trava de forma fiável as citações, porque os motores recorrem a caminhos alternativos, citações de terceiros e cópias em cache.[10] Pode perder o benefício de visibilidade sem ganhar plenamente a privacidade pela qual bloqueou.
Do outro lado da balança está o dano de tráfego que empurra as pessoas a bloquear em primeiro lugar. Os AI Overviews do Google cortaram mensuravelmente o tráfego de referência: a Digital Content Next relata quedas de tráfego de 1–25% para os membros, com média à volta dos 25%, e as taxas de cliques caem entre 34,5% e 79% quando surge um AI Overview, consoante o tipo de consulta.[8] Os editores inquiridos pela ppc.land esperam uma queda adicional de tráfego de 43% nos próximos três anos.[10] Quando a IA lhe tira tráfego e ao mesmo tempo o rastreia 70.000 para 1, a vontade de levantar a ponte levadiça é compreensível.
O que os AI Overviews fazem ao tráfego dos sites pequenos
O dano que empurra os donos a bloquear — e porque a decisão parece urgente[8][10]
Cerca de um quarto dos 1.000 maiores sites bloqueia agora o GPTBot. Mas repare no que bloquear só o GPTBot não faz: não o remove dos AI Overviews (índice diferente), e não impede o ChatGPT Search de o citar (isso é o OAI-SearchBot). O dano de tráfego e o rastreador que bloqueia muitas vezes nem sequer estão ligados.
A quota de rastreadores de IA consolida-se à volta de dois atores
O GPTBot e o ClaudeBot mais do que duplicaram a sua quota de rastreio de IA; o Bytespider desabou[3]
Entre 2024 e meados de 2025, a quota de rastreio de IA do GPTBot subiu de 4,7% para 11,7% e a do ClaudeBot de 6% para ~10%, enquanto o Bytespider da ByteDance caiu de 14,1% para 2,4%. Em maio de 2026, o dedicado Claude-SearchBot da Anthropic apareceu com 2,00% de quota — a primeira vez que o rastreador de busca de um grande fornecedor surge como um ator distinto e de dimensão notável.

O novo opt-out do Google — e porque o Google-Extended não o é
O controlo que os editores pediam há dois anos chegou finalmente em junho de 2026. Não é o mesmo que o Google-Extended, e a diferença importa.
Durante dois anos, a pergunta mais feita sobre rastreadores de IA foi alguma versão de: «Como apareço na busca normal do Google mas não nos AI Overviews?». Até junho de 2026, a resposta honesta era «não pode». O Google-Extended — o token a que a maioria recorria — só controla se o Google treina o Gemini e o Vertex AI com as suas páginas já rastreadas. Nunca controlou os AI Overviews nem o AI Mode, que recorrem ao índice padrão do Googlebot. Bloquear o Google-Extended não fazia nada para o manter fora dos resumos de IA que de facto comiam os seus cliques.[8]
Isso mudou a 3 de junho de 2026, quando o Google lançou um relatório de desempenho de IA na Search Console juntamente com um botão de opt-out que permite aos editores retirar conteúdo dos AI Overviews e do AI Mode sem perder o ranking de busca padrão.[6] A definição entra em vigor a 17 de junho de 2026, quando o Google começa a agir sobre o sinal, e ativá-la não afeta a sua posição nos resultados normais do Google.[7] Duas ressalvas a reler duas vezes: a app Gemini fica excluída deste opt-out (é um produto separado), e optar por sair significa aceitar que desaparece também a citação/visibilidade que obtinha dos AIO.
O que faz cada alavanca do Google
- Google-Extended (token do robots.txt) → recusa do treino do Gemini / Vertex. Não o remove dos AI Overviews.
- Botão de opt-out de IA do GSC (em vigor a 17 jun 2026) → retira conteúdo dos AI Overviews e do AI Mode, mantém o ranking normal. Exclui a app Gemini.
- Disallow Googlebot → opção nuclear; remove-o do Google por completo, incluindo a busca normal que ainda envia cliques reais. Quase nunca a escolha certa.
A configuração predefinida recomendada para 2026
Três perfis, uma decisão. Escolha o que corresponde ao seu objetivo e copie o robots.txt abaixo.
Não há uma única configuração correta — há uma configuração correta para o seu objetivo. Eis os três perfis que cobrem quase todos os sites pequenos, de «quero estar em cada resposta» a «mantém-me fora da IA por completo».
| Perfil | Para quem | Bots de treino | Bots de busca | Porquê |
|---|---|---|---|---|
| Visibilidade máxima | A maioria dos sites pequenos, blogues, negócios locais | Permitir tudo | Permitir tudo | Quer estar em cada resposta. O custo de largura de banda é trivial em pequena escala, e bloquear o treino tem efeitos secundários mensuráveis nas citações. |
| Bloquear o treino, manter as citações | Editores, sites de investigação original, quem recuse a extração unilateral | Bloquear GPTBot, ClaudeBot, Google-Extended, CCBot, Applebot-Extended, Bytespider (WAF) | Permitir OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User, Claude-User | A predefinição de consenso de 2026 para negócios de conteúdo: travar a extração unilateral, manter aberto o canal de citações. |
| Fora das respostas de IA por completo | Conteúdo pago, de subscrição ou juridicamente sensível | Bloquear todos os bots de treino | Bloquear todos os bots de busca/resposta + ativar o novo opt-out do GSC (em vigor a 17 jun 2026) | Aceita a perda de citações para manter o conteúdo fora das superfícies de IA. O ranking padrão do Google não é afetado pelo botão do GSC. |
Para a maioria dos sites pequenos, a recomendação honesta é o Perfil 1 — permitir tudo. O seu objetivo é a visibilidade, o custo de largura de banda do rastreio de IA é trivial em pequena escala, e bloquear os rastreadores de treino acarreta efeitos secundários nas citações que não pode prever totalmente. O perfil «bloquear o treino, manter as citações» (Perfil 2) é a predefinição certa para negócios de conteúdo, editores e quem publique investigação original e recuse genuinamente a extração unilateral. O Perfil 3 é só para conteúdo pago, de subscrição ou juridicamente sensível.
Esta é a configuração de consenso de 2026 para um site de conteúdo que quer travar o treino gratuito mas continuar citável na busca de IA. Cole-a em /robots.txt e adicione separadamente a regra de firewall para o Bytespider (ignora o robots.txt).
# --- Bloquear rastreadores de TREINO ---
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# --- PERMITIR rastreadores de busca / resposta (é assim que é citado) ---
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
# --- Tudo o resto ---
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xmlNotas: substitua example.com pelo seu domínio. O Bytespider precisa de um bloqueio ao nível de WAF ou IP — um Disallow não o trava de forma fiável. E lembre-se de que aqui o Google-Extended só bloqueia o treino do Gemini; para sair dos AI Overviews, use o novo opt-out da Search Console (em vigor a 17 de junho de 2026), não este ficheiro.
A higiene de rastreadores abre a porta — o conteúdo torna-a digna de atravessar
Como ver que bots o estão realmente a visitar
Antes de bloquear o que quer que seja, olhe para os seus logs. Pode estar a otimizar para um rastreador que nunca o visita — ou a bloquear um que gera todas as suas citações.
Regras escritas às escuras são palpites. Dedique vinte minutos a ver quem o rastreia de facto antes de mudar uma única linha, porque o panorama de bots varia enormemente por nicho. Eis a pilha de monitorização prática, da mais barata em diante:
- Logs de acesso do servidor / CDN. Filtre por user-agent para
GPTBot,OAI-SearchBot,ChatGPT-User,ClaudeBot,Claude-SearchBot,PerplexityBot,CCBoteBytespider. Isto diz-lhe a frequência e que páginas cada bot toca. Nota: oGoogle-Extendednunca aparecerá — é um token, não um pedido. - Cloudflare Radar AI Insights. Se estiver atrás da Cloudflare, o painel gratuito AI Insights mostra a atividade de rastreadores de IA e os dados crawl-to-referral citados neste artigo.
- Google Search Console. O novo relatório de desempenho de IA (junho de 2026) é onde verá as impressões de AI Overviews / AI Mode — e onde vive o botão de opt-out.
- Verifique a autenticidade. Os user-agents falsificados são comuns. Cruze os acessos suspeitos com os intervalos de IP publicados — a OpenAI lista-os em
openai.com/gptbot.json,openai.com/searchbot.jsoneopenai.com/chatgpt-user.json.
O check-up de higiene de rastreadores em 30 minutos
- Extraia os logs de acesso do último mês; liste cada user-agent de IA que o visitou e com que frequência.
- Abra o seu
robots.txtatual. Ainda menciona só o GPTBot? Atualize-o para a lista de bots de 2026 com o perfil que corresponde ao seu objetivo. - Certifique-se de que não está a bloquear por acidente o
OAI-SearchBot, oClaude-SearchBotou oPerplexityBot— é o erro dos 71% dos editores. - Adicione uma regra de WAF para o Bytespider se os seus logs o mostrarem a ignorar o seu robots.txt.
- Decida sobre os AI Overviews separadamente: deixe-os estar, ou use o opt-out do GSC a partir de 17 de junho de 2026. Não espere que o Google-Extended faça esse trabalho.
- Opcionalmente, publique um
llms.txtse a sua stack o gerar — depois esqueça-o e vá escrever conteúdo.
→ Faça-o agora: Abra https://o-seu-dominio.com/robots.txt num navegador. Se não mencionar o OAI-SearchBot nem o Claude-SearchBot, está desatualizado — e pode estar invisível para os próprios produtos de busca de IA que os seus clientes usam. Escolha um perfil da tabela acima, cole a configuração correspondente, e terá feito mais higiene de rastreadores do que a esmagadora maioria dos sites pequenos em 2026.
Leituras relacionadas
- AEO vs SEO em 2026: porque os motores de resposta são a nova busca — assim que os bots de busca o conseguem ler, é assim que ganha de facto a citação.
- AI Overviews e SGE: como os sites pequenos ainda podem ganhar cliques — os dados do dano de tráfego por trás da decisão de opt-out.
- Schema markup para pequenas empresas — os dados estruturados que ajudam os rastreadores que permitiu a compreender as suas páginas.
- SEO técnico para não programadores — robots.txt, sitemaps e o resto da canalização, em linguagem clara.
Referências e fontes
Artigo também disponível em: