Why Your robots.txt Is Suddenly Three Years Out of Date
In 2023 you needed one line for GPTBot. In 2026 the modern robots.txt needs rules for a dozen AI-specific bots — and the old "block all AI" advice is now actively harmful.
If you run a small site, there is a decent chance your robots.txt hasn't been touched since you added a single GPTBot rule in 2023 — or that you've never touched it at all. That gap matters more than it used to. By mid-2025, Cloudflare's network data showed training-related crawling had grown to roughly 80% of all AI bot activity, up from 72% a year earlier.[3] AI crawlers are now a meaningful slice of who knocks on your server's door every day, and the rules you give them decide two very different things: whether your content trains someone else's model for free, and whether you show up when a buyer asks ChatGPT or Perplexity a question.
The thing that makes 2026 genuinely different is that the major AI vendors split their single crawler into several. OpenAI no longer runs one bot — it runs GPTBot for training, OAI-SearchBot for ChatGPT Search, and ChatGPT-User for on-demand fetches. Anthropic runs three. The practical consequence: the instinctive move of Disallow: / for every AI user-agent now does two jobs at once. It opts you out of training corpora (often what you wanted) and deletes you from AI search answers (almost never what you wanted). Digital Applied's analysis of Anthropic's framework reports that roughly 71% of top news publishers block at least one retrieval or search bot, frequently while intending to block only training.[5] That is the exact, expensive mistake this guide is built to prevent.
The one sentence that explains the whole topic
What llms.txt Is — and Why It Probably Won't Do Much
A reasonable idea with almost no adoption proof behind it. Ship one if it's cheap; don't build a strategy on it.
llms.txt is a community-proposed Markdown file you place at your domain root (/llms.txt) that lists your most important pages in clean, parseable form, so a large language model can find and understand your best content without wading through navigation, ads, and scripts. It was proposed by Jeremy Howard of Answer.AI in September 2024. The analogy people reach for is "a sitemap for LLMs," and the intent is genuinely sensible: give the models a curated, low-noise map of what matters on your site, optionally with a fuller /llms-full.txt that inlines the actual content.
The problem is the gap between the idea and the evidence. After eighteen months of industry conversation, the data is sobering:
- Adoption is about one in ten sites. SE Ranking's study of 300,000 domains found a 10.13% adoption rate, and crucially, adoption was nearly identical across low-, mid-, and high-traffic tiers (~9–10% each) — so it isn't the sophisticated sites racing ahead.[1]
- No measurable citation lift. The same SE Ranking analysis found no statistically significant difference in AI citation frequency between sites with and without an llms.txt. A model trained on AI-citation data actually improved when the llms.txt variable was removed.[1]
- Almost nothing reads it. Limy.AI monitored over 500 million AI bot events across 90 days and found only 408 requests that targeted llms.txt directly.[14] Search Engine Land tracked 10 sites for 90 days before and after adding the file; only two saw AI traffic increases, and not because of the file.[2]
- No official support. As of mid-2026, none of OpenAI, Anthropic, Google, or Perplexity has officially confirmed that its systems read or act on llms.txt. It remains a community spec, not an adopted standard.
llms.txt: the adoption-vs-impact reality
One in ten sites have it; the measurable payoff so far is roughly zero[1][14]
This is not an argument against ever shipping an llms.txt — it costs almost nothing and is forward-compatible if platforms formalize support later. It is an argument against treating it as a growth lever. Spend the ten minutes if you like; do not spend a strategy meeting on it.
The honest take for a small site
robots.txt. That's the one the crawlers genuinely obey, and it's the one that decides whether you're in (or out of) the answers your customers are reading.robots.txt vs llms.txt: The Honest Comparison
Same root directory, completely different powers. One is enforceable; one is a polite request nobody is obligated to read.
| Dimension | robots.txt | llms.txt |
|---|---|---|
| What it is | An access-control file telling crawlers what they may and may not fetch | A curation file in Markdown listing your best pages so an LLM can find and parse them |
| Age & status | Robots Exclusion Protocol — a ~30-year web standard, now an IETF RFC | A community proposal from Sept 2024 (Jeremy Howard / Answer.AI). Not an official standard |
| Location | /robots.txt at your domain root | /llms.txt at your domain root (optionally a fuller /llms-full.txt) |
| Enforcement | Honored by all the major AI crawlers (except a few like Bytespider) | Advisory only — no crawler is obligated to read or act on it |
| Who actually consumes it | OpenAI, Anthropic, Perplexity, Google, Common Crawl all read it | No major AI platform has officially confirmed it reads llms.txt (mid-2026) |
| Measured impact | Directly controls whether a bot is allowed to crawl a path | SE Ranking's 300k-domain study found no statistically significant citation lift |
| What it can't do | Can't stop a non-compliant bot, and doesn't control AI Overviews (Googlebot index) | Can't block anything — it's a suggestion, not a gate |
| Worth doing in 2026? | Yes — it's your real lever. Keep it current with the 2026 bot list | Low-cost, low-risk, low-reward. Ship one if it's cheap; don't expect traffic from it |
The takeaway is not "llms.txt is useless" — it's that the two files are not interchangeable, and the one that actually changes outcomes today is the boring, decades-old one. If you only have time to get one file right in 2026, make it robots.txt, with rules that reflect the current AI crawler landscape rather than the 2023 version of it.
The 2026 AI Crawler Zoo: Who's Actually Visiting
Every AI engine runs its own crawler — and most of them run two or three, each with a different job and a different right answer.
Before you can write a sensible rule, you need to know what each bot is for. Every AI crawler does one of three jobs: it collects pages for model training, it indexes pages for AI search answers, or it fetches a page in real time because a user asked the assistant about it right now. These are different commercial relationships, and in 2026 the major vendors finally expose them as different bots you can control independently.
The bots you'll see most
| Bot | Owner | Purpose | robots.txt? | 2026 default call |
|---|---|---|---|---|
GPTBot | OpenAI | Training — feeds future GPT models | Yes | Block if you don't want to train models for free; allow if you want maximum future reach |
OAI-SearchBot | OpenAI | Indexes pages for ChatGPT Search | Yes | ALLOW — blocking removes you from ChatGPT Search answers |
ChatGPT-User | OpenAI | On-demand fetch when a user pastes/opens your URL | Yes | ALLOW — blocking breaks a fetch the user explicitly asked for |
ClaudeBot | Anthropic | Training — feeds Claude's pre-training corpus | Yes | Block to opt out of training; the most extractive crawler by crawl-to-referral ratio |
Claude-SearchBot | Anthropic | Indexes pages for Claude's web search tool | Yes | ALLOW — this is how Claude cites you (new in 2026) |
PerplexityBot | Perplexity | Indexes pages so Perplexity can cite them | Yes (stealth-crawler caveat) | ALLOW — Perplexity is the most citation-friendly engine for small sites |
Google-Extended | Control token — governs Gemini/Vertex training use of already-crawled pages | Yes (it's a token, not a real bot — never in your logs) | Optional opt-out of Gemini training. Does NOT control AI Overviews — use the new GSC opt-out for that | |
CCBot | Common Crawl | Public corpus that feeds many model trainers | Yes | Block to keep out of the open training corpus; harmless to allow |
Bytespider | ByteDance | Training — feeds Doubao | No — documented non-compliance | Block at the WAF / IP level — robots.txt alone won't stop it |
Two rows deserve a second read. Google-Extended is not a real crawler at all — it's a control token that never appears in your server logs as an HTTP request. It only governs whether Google may use pages it has already crawled (via the normal Googlebot) to train Gemini and Vertex AI. And Bytespider (ByteDance) has a documented history of ignoring robots.txt inconsistently, which is why blocking it requires a firewall or IP-level rule rather than a polite Disallow.
The distinction that does all the work
GPTBot is not OAI-SearchBot. ClaudeBot is not Claude-SearchBot. Treat them as one bucket and you delete yourself from the fastest-growing referral channel of the year.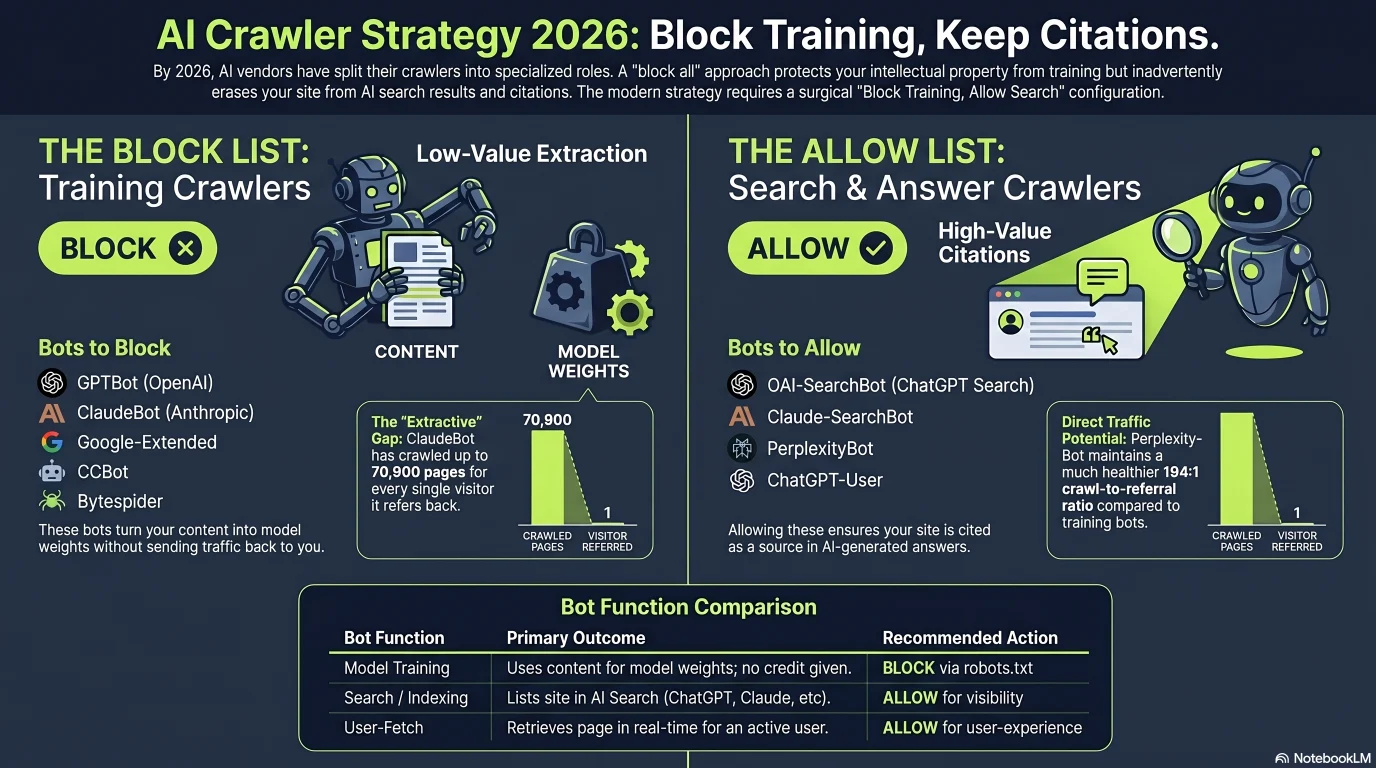
The Economics: Traffic Loss vs Citation Loss
The block-or-allow decision is really a trade between two kinds of loss. Cloudflare's crawl-to-referral ratio is the number that frames it.
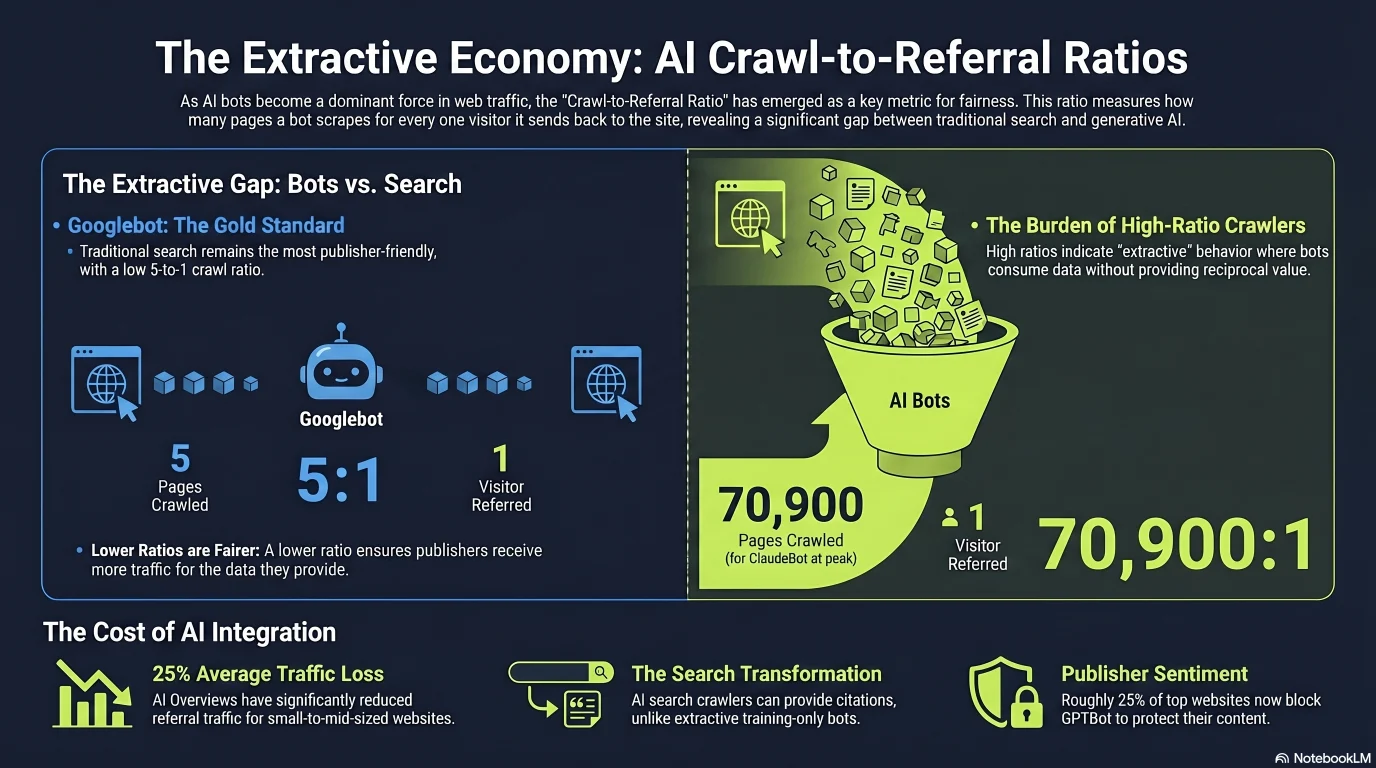
The business argument for blocking training crawlers comes down to a single ratio: how many of your pages a bot crawls for every one visitor it sends back. Cloudflare publishes this crawl-to-referral ratio across its network, and the spread between vendors is extraordinary. Traditional Googlebot sits around 5 pages crawled per referral. Anthropic's ClaudeBot, at its June 2025 peak, was crawling roughly 70,900 pages for every visitor it referred back — an asymmetry that reframes training access as a one-way extraction of value.[5]
Crawl-to-referral ratio — pages crawled per 1 visitor sent back
Lower is fairer to publishers. Training crawlers take vastly more than they give[3][5][9]
The bars are on a single linear scale, which is why everything below ClaudeBot looks tiny — that's the point. ClaudeBot's peak (~70,900:1) and GPTBot (1,276:1) dwarf Googlebot (~5:1) and DuckDuckGo (~1.5:1). By July 2025 Anthropic had improved to ~38,000:1 and Perplexity sat at 194:1, but the gap between training crawlers and classic search remains enormous.
But there's a catch that stops "just block the training bots" from being a free lunch, and it's the most important nuance in this whole article. Blocking has citation side-effects. AuthorityTech's 2026 analysis found that sites blocking Google-Extended are significantly less likely to be cited by generative engines — even in AI Overviews, where Google technically retains content access through the regular index.[11] And ppc.land's data shows blocking is leaky in the other direction too: blocking AI crawlers doesn't reliably stop citations, because engines pull from alternate paths, third-party quotes, and cached copies.[10] You can lose the visibility upside without fully gaining the privacy you blocked for.
On the other side of the ledger sits the traffic damage that pushes people to block in the first place. Google AI Overviews have measurably cut referral traffic: Digital Content Next reports 1–25% traffic declines for members, averaging around 25%, and click-through rates drop anywhere from 34.5% to 79% when an AI Overview appears, depending on query type.[8] Publishers surveyed by ppc.land expect a further 43% traffic decline over the next three years.[10] When AI is both taking your traffic and crawling you 70,000-to-1, the urge to pull up the drawbridge is understandable.
What AI Overviews are doing to small-site traffic
The damage that pushes owners to block — and why the decision feels urgent[8][10]
Roughly a quarter of the top 1,000 sites now block GPTBot. But notice what blocking GPTBot alone does not do: it doesn't remove you from AI Overviews (different index), and it doesn't stop ChatGPT Search citing you (that's OAI-SearchBot). The traffic damage and the crawler you block are often not even connected.
AI crawler share is consolidating around two players
GPTBot and ClaudeBot more than doubled their share of AI crawling; Bytespider collapsed[3]
Between 2024 and mid-2025, GPTBot's share of AI crawling rose from 4.7% to 11.7% and ClaudeBot from 6% to ~10%, while ByteDance's Bytespider fell from 14.1% to 2.4%. In May 2026, Anthropic's dedicated Claude-SearchBot appeared at 2.00% share — the first time a major vendor's search crawler showed up as a distinct, sizeable actor.
Google's New Opt-Out — and Why Google-Extended Isn't It
The control publishers have wanted for two years finally shipped in June 2026. It is not the same thing as Google-Extended, and the difference matters.
For two years, the single most-asked question about AI crawlers was some version of: "How do I appear in normal Google Search but not in AI Overviews?" Until June 2026, the honest answer was "you can't." Google-Extended — the token most people reached for — only controls whether Google trains Gemini and Vertex AI on your already-crawled pages. It has never controlled AI Overviews or AI Mode, which draw on the standard Googlebot index. Blocking Google-Extended did nothing to keep you out of the AI summaries actually eating your clicks.[8]
That changed on June 3, 2026, when Google shipped a Search Console AI performance report alongside an opt-out toggle that lets publishers remove content from AI Overviews and AI Mode without losing standard Search ranking.[6] The setting takes effect June 17, 2026, when Google begins acting on the signal, and activating it does not affect your ranking in regular Google Search results.[7] Two caveats worth reading twice: the standalone Gemini app is excluded from this opt-out (it's a separate product), and opting out means accepting whatever citation/visibility you were getting from AIO disappears too.
Which Google lever does what
- Google-Extended (robots.txt token) → opt out of Gemini / Vertex training. Does not remove you from AI Overviews.
- GSC AI opt-out toggle (effective Jun 17, 2026) → remove content from AI Overviews and AI Mode, keep normal Search ranking. Excludes the standalone Gemini app.
- Disallow Googlebot → nuclear option; removes you from Google entirely, including the regular search that still sends real clicks. Almost never the right call.
The Recommended 2026 Default Config
Three profiles, one decision. Pick the one that matches your goal, then copy the robots.txt below.
There is no single correct configuration — there's a correct configuration for your goal. Here are the three profiles that cover almost every small site, from "I want to be in every answer" to "keep me out of AI entirely."
| Profile | Who it's for | Training bots | Search bots | Why |
|---|---|---|---|---|
| Maximum visibility | Most small sites, blogs, local businesses | Allow all | Allow all | You want to be in every answer. Bandwidth cost is trivial at small scale, and blocking training has measurable citation side-effects. |
| Block training, keep citations | Publishers, original-research sites, anyone who resents free training | Block GPTBot, ClaudeBot, Google-Extended, CCBot, Applebot-Extended, Bytespider (WAF) | Allow OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User, Claude-User | The 2026 consensus default for content businesses: stop the one-way extraction, keep the citation channel open. |
| Out of AI answers entirely | Paywalled, membership, or legally-sensitive content | Block all training bots | Block all search/answer bots + toggle the new GSC AI opt-out (effective Jun 17, 2026) | Accept the citation loss to keep content out of AI surfaces. Standard Google Search ranking is unaffected by the GSC toggle. |
For most small sites, the honest recommendation is Profile 1 — allow everything. Your goal is visibility, the bandwidth cost of AI crawling is trivial at small scale, and blocking training crawlers carries citation side-effects you can't fully predict. The "block training, keep citations" profile (Profile 2) is the right default for content businesses, publishers, and anyone shipping original research who genuinely resents one-way extraction. Profile 3 is for paywalled, membership, or legally-sensitive content only.
This is the 2026 consensus config for a content site that wants to stop free training while staying citable in AI search. Paste it into /robots.txt, then add the Bytespider firewall rule separately (it ignores robots.txt).
# --- Block TRAINING crawlers ---
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# --- ALLOW search / answer crawlers (this is how you get cited) ---
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
# --- Everything else ---
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xmlNotes: replace example.com with your domain. Bytespider needs a WAF or server-level IP block — a Disallow won't reliably stop it. And remember Google-Extended here only blocks Gemini training; to leave AI Overviews, use the new Search Console opt-out (effective June 17, 2026), not this file.
Crawler hygiene opens the door — content keeps it worth walking through
How to See Which Bots Are Actually Hitting You
Before you block anything, look at your logs. You may be optimizing for a crawler that never visits — or blocking one that drives all your citations.
Rules written in the dark are guesses. Spend twenty minutes looking at who's actually crawling you before you change a single line, because the bot landscape varies wildly by niche. Here's the practical monitoring stack, cheapest first:
- Server / CDN access logs. Filter by user-agent for
GPTBot,OAI-SearchBot,ChatGPT-User,ClaudeBot,Claude-SearchBot,PerplexityBot,CCBot, andBytespider. This tells you frequency and which pages each bot hits. Note:Google-Extendedwill never appear — it's a token, not a request. - Cloudflare Radar AI Insights. If you're behind Cloudflare, the free AI Insights dashboard shows AI crawler activity and the crawl-to-referral data referenced throughout this article.
- Google Search Console. The new AI performance report (June 2026) is where you'll see AI Overviews / AI Mode impressions — and where the opt-out toggle lives.
- Verify authenticity. Spoofed user-agents are common. Cross-check suspicious hits against published IP ranges — OpenAI lists them at
openai.com/gptbot.json,openai.com/searchbot.json, andopenai.com/chatgpt-user.json.
The 30-minute crawler-hygiene checkup
- Pull last month's access logs; list every AI user-agent that hit you and how often.
- Open your current
robots.txt. Does it still only mention GPTBot? Update it to the 2026 bot list using the profile that matches your goal. - Make sure you are not accidentally blocking
OAI-SearchBot,Claude-SearchBot, orPerplexityBot— that's the 71%-of-publishers mistake. - Add a Bytespider WAF rule if your logs show it ignoring your robots.txt.
- Decide on AI Overviews separately: leave them be, or use the GSC opt-out from June 17, 2026. Don't expect Google-Extended to do that job.
- Optionally ship an
llms.txtif your stack generates one — then forget about it and go write content.
→ Do this now: Open https://your-domain.com/robots.txt in a browser. If it doesn't mention OAI-SearchBot or Claude-SearchBot, it's out of date — and you may be invisible to the exact AI search products your customers are using. Pick a profile from the table above, paste the matching config, and you've done more crawler hygiene than the overwhelming majority of small sites have in 2026.
Related reading
- AEO vs SEO in 2026: Why Answer Engines Are the New Search — once the search bots can read you, this is how you actually earn the citation.
- AI Overviews & SGE: How Small Sites Can Still Win Clicks — the traffic-damage data behind the opt-out decision.
- Schema Markup for Small Businesses — the structured data that helps the crawlers you allowed in understand your pages.
- Technical SEO for Non-Developers — robots.txt, sitemaps, and the rest of the plumbing, in plain English.