Perché il tuo robots.txt è improvvisamente vecchio di tre anni
Nel 2023 bastava una riga per GPTBot. Nel 2026 un robots.txt moderno ha bisogno di regole per una dozzina di bot IA — e il vecchio consiglio «blocca tutta l'IA» ora è controproducente.
Se gestisci un piccolo sito, ci sono buone probabilità che il tuo robots.txt non sia stato toccato da quando hai aggiunto una singola regola per GPTBot nel 2023 — o che non l'abbia mai toccato. Questa lacuna conta più di prima. A metà 2025, i dati di rete di Cloudflare hanno mostrato che il crawling legato all'addestramento era cresciuto fino a circa l'80% di tutta l'attività dei bot IA, dal 72% dell'anno precedente.[3] I crawler IA sono ormai una fetta significativa di chi bussa alla porta del tuo server ogni giorno, e le regole che dai loro decidono due cose molto diverse: se i tuoi contenuti addestrano gratis il modello di qualcun altro, e se compari quando un acquirente fa una domanda a ChatGPT o Perplexity.
Ciò che rende il 2026 davvero diverso è che i grandi fornitori di IA hanno diviso il loro singolo crawler in diversi. OpenAI non gestisce più un solo bot — gestisce GPTBot per l'addestramento, OAI-SearchBot per ChatGPT Search e ChatGPT-User per i recuperi su richiesta. Anthropic ne gestisce tre. La conseguenza pratica: la mossa istintiva di Disallow: / per ogni user-agent IA ora fa due lavori contemporaneamente. Ti esclude dai corpus di addestramento (spesso quello che volevi) e ti cancella dalle risposte di ricerca IA (quasi mai quello che volevi). L'analisi di Digital Applied del quadro di Anthropic riporta che circa il 71% dei grandi editori di notizie blocca almeno un bot di recupero o ricerca, spesso con l'intenzione di bloccare solo l'addestramento.[5] È esattamente l'errore costoso che questa guida è fatta per evitare.
La frase che spiega tutto l'argomento
Cos'è llms.txt — e perché probabilmente farà poco
Un'idea ragionevole con quasi nessuna prova di adozione alle spalle. Pubblicalo se è gratis; non costruirci una strategia.
llms.txt è un file Markdown proposto dalla community che collochi nella radice del tuo dominio (/llms.txt) e che elenca le tue pagine più importanti in forma pulita e analizzabile, perché un modello linguistico di grandi dimensioni trovi e comprenda i tuoi contenuti migliori senza attraversare navigazione, pubblicità e script. È stato proposto da Jeremy Howard di Answer.AI nel settembre 2024. L'analogia abituale è «una sitemap per gli LLM», e l'intento è davvero sensato: dare ai modelli una mappa curata e a basso rumore di ciò che conta sul tuo sito, facoltativamente con un /llms-full.txt più completo che incorpora il contenuto reale.
Il problema è il divario tra l'idea e le prove. Dopo diciotto mesi di discussione nel settore, i dati fanno riflettere:
- L'adozione è circa un sito su dieci. Lo studio di SE Ranking su 300.000 domini ha trovato un tasso di adozione del 10,13%, e, cosa cruciale, l'adozione era quasi identica nelle fasce di traffico basso, medio e alto (~9–10% ciascuna) — quindi non sono i siti sofisticati a correre avanti.[1]
- Nessun aumento misurabile di citazioni. La stessa analisi di SE Ranking non ha trovato alcuna differenza statisticamente significativa nella frequenza delle citazioni IA tra siti con e senza llms.txt. Un modello addestrato su dati di citazioni IA è persino migliorato quando la variabile llms.txt è stata rimossa.[1]
- Quasi nulla lo legge. Limy.AI ha monitorato oltre 500 milioni di eventi di bot IA in 90 giorni e ha trovato solo 408 richieste rivolte direttamente a llms.txt.[14] Search Engine Land ha seguito 10 siti per 90 giorni prima e dopo l'aggiunta del file; solo due hanno visto aumenti di traffico IA, e non a causa del file.[2]
- Nessun supporto ufficiale. A metà 2026, né OpenAI, né Anthropic, né Google, né Perplexity hanno ufficialmente confermato che i loro sistemi leggano o agiscano su llms.txt. Resta una specifica della community, non uno standard adottato.
llms.txt: la realtà adozione vs impatto
Un sito su dieci lo ha; il beneficio misurabile finora è quasi zero[1][14]
Questo non è un argomento contro il pubblicare mai un llms.txt — costa quasi nulla ed è compatibile con il futuro se le piattaforme formalizzeranno il supporto. È un argomento contro il trattarlo come una leva di crescita. Dedicagli i dieci minuti se vuoi; non dedicargli una riunione di strategia.
Il parere onesto per un piccolo sito
robots.txt. È quello a cui i crawler obbediscono davvero, ed è quello che decide se sei (o no) nelle risposte che i tuoi clienti stanno leggendo.robots.txt vs llms.txt: il confronto onesto
Stessa directory radice, poteri completamente diversi. Uno è applicabile; l'altro è una richiesta cortese che nessuno è obbligato a leggere.
| Dimensione | robots.txt | llms.txt |
|---|---|---|
| Cos'è | Un file di controllo accessi che dice ai crawler cosa possono e non possono scaricare | Un file di curatela in Markdown che elenca le tue pagine migliori perché un LLM le trovi e le analizzi |
| Età e stato | Robots Exclusion Protocol — uno standard web di ~30 anni, ora un RFC dell'IETF | Una proposta della community del set 2024 (Jeremy Howard / Answer.AI). Non è uno standard ufficiale |
| Posizione | /robots.txt nella radice del tuo dominio | /llms.txt nella radice del tuo dominio (facoltativamente un /llms-full.txt più completo) |
| Applicazione | Rispettato da tutti i grandi crawler IA (tranne alcuni come Bytespider) | Solo consultivo — nessun crawler è obbligato a leggerlo o a tenerne conto |
| Chi lo usa davvero | OpenAI, Anthropic, Perplexity, Google e Common Crawl lo leggono tutti | Nessuna grande piattaforma IA ha ufficialmente confermato di leggere llms.txt (metà 2026) |
| Impatto misurato | Controlla direttamente se un bot può scansionare un percorso | Lo studio di SE Ranking su 300k domini non ha trovato aumenti significativi di citazioni |
| Cosa non può fare | Non può fermare un bot non conforme e non controlla gli AI Overviews (indice Googlebot) | Non può bloccare nulla — è un suggerimento, non un cancello |
| Vale la pena nel 2026? | Sì — è la tua vera leva. Tienilo aggiornato con la lista dei bot del 2026 | Basso costo, basso rischio, bassa ricompensa. Pubblicalo se è gratis; non aspettarti traffico da esso |
La conclusione non è «llms.txt è inutile» — è che i due file non sono intercambiabili, e quello che cambia davvero i risultati oggi è il noioso file di decenni fa. Se nel 2026 hai tempo di sistemare bene un solo file, che sia robots.txt, con regole che riflettano il panorama attuale dei crawler IA e non la versione del 2023.
Lo zoo dei crawler IA del 2026: chi ti visita davvero
Ogni motore IA gestisce il proprio crawler — e la maggior parte ne gestisce due o tre, ciascuno con un lavoro diverso e una risposta giusta diversa.
Prima di poter scrivere una regola sensata, devi sapere a cosa serve ogni bot. Ogni crawler IA svolge uno di tre lavori: raccoglie pagine per addestrare modelli, indicizza pagine per le risposte di ricerca IA, oppure recupera una pagina in tempo reale perché un utente ha chiesto all'assistente di essa proprio ora. Sono relazioni commerciali diverse, e nel 2026 i grandi fornitori le espongono finalmente come bot diversi che puoi controllare in modo indipendente.
I bot che vedrai più spesso
| Bot | Proprietario | Scopo | robots.txt? | Decisione predefinita 2026 |
|---|---|---|---|---|
GPTBot | OpenAI | Addestramento — alimenta i futuri modelli GPT | Sì | Bloccalo se non vuoi addestrare modelli gratis; consentilo per la massima portata futura |
OAI-SearchBot | OpenAI | Indicizza le pagine per ChatGPT Search | Sì | CONSENTIRE — bloccarlo ti elimina dalle risposte di ChatGPT Search |
ChatGPT-User | OpenAI | Recupero su richiesta quando un utente apre il tuo URL | Sì | CONSENTIRE — bloccarlo rompe un recupero che l'utente ha richiesto |
ClaudeBot | Anthropic | Addestramento — alimenta il corpus di pre-addestramento di Claude | Sì | Bloccalo per rinunciare all'addestramento; è il crawler più estrattivo per rapporto crawl-to-referral |
Claude-SearchBot | Anthropic | Indicizza le pagine per lo strumento di ricerca web di Claude | Sì | CONSENTIRE — è così che Claude ti cita (nuovo nel 2026) |
PerplexityBot | Perplexity | Indicizza le pagine perché Perplexity possa citarle | Sì (con riserva sul crawling furtivo) | CONSENTIRE — Perplexity è il motore più favorevole alle citazioni per i piccoli siti |
Google-Extended | Token di controllo — regola l'uso delle pagine già scansionate per addestrare Gemini/Vertex | Sì (è un token, non un vero bot — mai nei tuoi log) | Rinuncia opzionale all'addestramento di Gemini. NON controlla gli AI Overviews — usa il nuovo opt-out di GSC per questo | |
CCBot | Common Crawl | Corpus pubblico che alimenta molti addestratori di modelli | Sì | Bloccalo per restare fuori dal corpus aperto; innocuo se consentito |
Bytespider | ByteDance | Addestramento — alimenta Doubao | No — non conformità documentata | Bloccalo a livello di WAF / IP — il solo robots.txt non lo ferma |
Due righe meritano una seconda lettura. Google-Extended non è affatto un vero crawler — è un token di controllo che non compare mai nei log del tuo server come richiesta HTTP. Regola solo se Google può usare pagine che ha già scansionato (con il normale Googlebot) per addestrare Gemini e Vertex AI. E Bytespider (ByteDance) ha una storia documentata di ignorare robots.txt in modo incoerente, motivo per cui bloccarlo richiede una regola di firewall o a livello di IP anziché un cortese Disallow.
La distinzione che fa tutto il lavoro
GPTBot non è OAI-SearchBot. ClaudeBot non è Claude-SearchBot. Trattali come un unico gruppo e ti cancelli dal canale di referral in più rapida crescita dell'anno.
L'economia: perdita di traffico vs perdita di citazioni
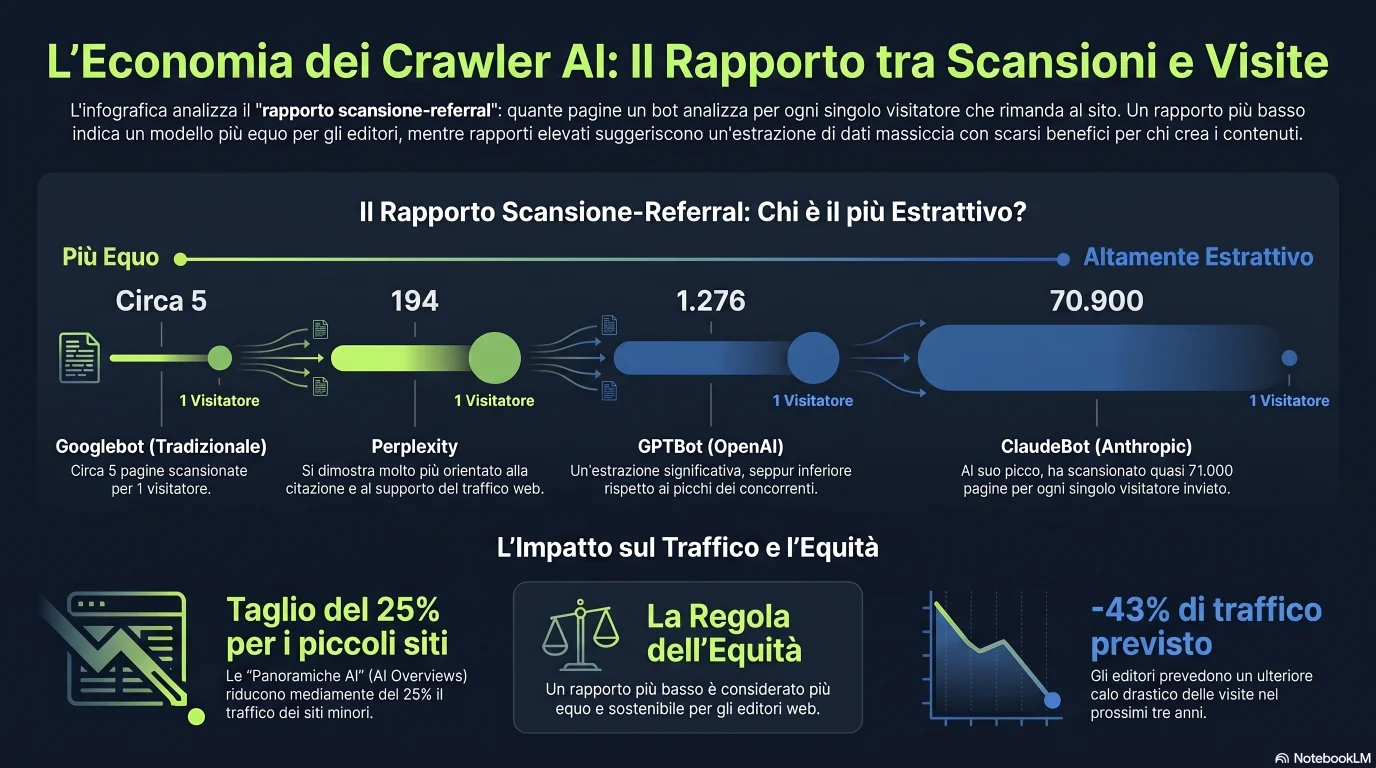
La decisione di bloccare o consentire è in realtà un compromesso tra due tipi di perdita. Il rapporto crawl-to-referral di Cloudflare è il numero che lo inquadra.
L'argomento commerciale per bloccare i crawler di addestramento si riduce a un singolo rapporto: quante delle tue pagine un bot scansiona per ogni visitatore che ti rimanda. Cloudflare pubblica questo rapporto crawl-to-referral sulla sua rete, e la differenza tra i fornitori è straordinaria. Il Googlebot tradizionale si attesta intorno a 5 pagine scansionate per referral. Il ClaudeBot di Anthropic, al suo picco di giugno 2025, scansionava circa 70.900 pagine per ogni visitatore che rimandava — un'asimmetria che ridefinisce l'accesso di addestramento come un'estrazione di valore unilaterale.[5]
Rapporto crawl-to-referral — pagine scansionate per 1 visitatore rimandato
Più basso è, più equo è per l'editore. I crawler di addestramento prendono molto più di quanto danno[3][5][9]
Le barre sono su un'unica scala lineare, ecco perché tutto ciò che sta sotto ClaudeBot sembra minuscolo — è proprio questo il punto. Il picco di ClaudeBot (~70.900:1) e GPTBot (1.276:1) fanno impallidire Googlebot (~5:1) e DuckDuckGo (~1,5:1). A luglio 2025 Anthropic era migliorato a ~38.000:1 e Perplexity era a 194:1, ma il divario resta enorme.
Ma c'è un'insidia che impedisce a «basta bloccare i bot di addestramento» di essere gratuito, ed è la sfumatura più importante di tutto questo articolo. Il blocco ha effetti collaterali sulle citazioni. L'analisi di AuthorityTech del 2026 ha rilevato che i siti che bloccano Google-Extended hanno molte meno probabilità di essere citati dai motori generativi — anche negli AI Overviews, dove Google mantiene tecnicamente l'accesso ai contenuti tramite l'indice normale.[11] E i dati di ppc.land mostrano che il blocco è poroso anche nell'altra direzione: bloccare i crawler IA non ferma in modo affidabile le citazioni, perché i motori attingono da percorsi alternativi, citazioni di terzi e copie nella cache.[10] Puoi perdere il vantaggio di visibilità senza ottenere del tutto la privacy per cui hai bloccato.
Sull'altro piatto della bilancia c'è il danno di traffico che spinge le persone a bloccare in primo luogo. Gli AI Overviews di Google hanno tagliato in modo misurabile il traffico di referral: Digital Content Next riporta cali di traffico dell'1–25% per i membri, con una media intorno al 25%, e i tassi di clic calano dal 34,5% al 79% quando appare un AI Overview, a seconda del tipo di query.[8] Gli editori intervistati da ppc.land prevedono un ulteriore calo di traffico del 43% nei prossimi tre anni.[10] Quando l'IA ti toglie il traffico e al contempo ti scansiona 70.000 a 1, la voglia di alzare il ponte levatoio è comprensibile.
Cosa fanno gli AI Overviews al traffico dei piccoli siti
Il danno che spinge i proprietari a bloccare — e perché la decisione sembra urgente[8][10]
Circa un quarto dei primi 1.000 siti ora blocca GPTBot. Ma nota cosa bloccare solo GPTBot non fa: non ti rimuove dagli AI Overviews (indice diverso) e non impedisce a ChatGPT Search di citarti (quello è OAI-SearchBot). Il danno di traffico e il crawler che blocchi spesso non sono nemmeno collegati.
La quota dei crawler IA si consolida attorno a due attori
GPTBot e ClaudeBot hanno più che raddoppiato la loro quota di crawling IA; Bytespider è crollato[3]
Tra il 2024 e metà 2025, la quota di crawling IA di GPTBot è salita dal 4,7% all'11,7% e quella di ClaudeBot dal 6% a ~10%, mentre il Bytespider di ByteDance è sceso dal 14,1% al 2,4%. A maggio 2026, il dedicato Claude-SearchBot di Anthropic è comparso con il 2,00% di quota — la prima volta che il crawler di ricerca di un grande fornitore si presenta come un attore distinto e di dimensioni notevoli.
Il nuovo opt-out di Google — e perché Google-Extended non lo è
Il controllo che gli editori chiedevano da due anni è finalmente arrivato a giugno 2026. Non è la stessa cosa di Google-Extended, e la differenza conta.
Per due anni, la domanda più frequente sui crawler IA è stata una versione di: «Come compaio nella ricerca Google normale ma non negli AI Overviews?». Fino a giugno 2026, la risposta onesta era «non puoi». Google-Extended — il token a cui la maggior parte ricorreva — controlla solo se Google addestra Gemini e Vertex AI sulle tue pagine già scansionate. Non ha mai controllato gli AI Overviews né l'AI Mode, che attingono all'indice standard di Googlebot. Bloccare Google-Extended non faceva nulla per tenerti fuori dai riassunti IA che si mangiavano davvero i tuoi clic.[8]
Le cose sono cambiate il 3 giugno 2026, quando Google ha rilasciato un report sulle prestazioni IA in Search Console insieme a un interruttore di opt-out che consente agli editori di rimuovere i contenuti dagli AI Overviews e dall'AI Mode senza perdere il ranking di ricerca standard.[6] L'impostazione diventa efficace il 17 giugno 2026, quando Google inizia ad agire sul segnale, e attivarla non influisce sulla tua posizione nei risultati Google normali.[7] Due avvertenze da leggere due volte: l'app Gemini è esclusa da questo opt-out (è un prodotto separato), e rinunciare significa accettare che sparisca anche la citazione/visibilità che ottenevi dagli AIO.
Cosa fa ciascuna leva di Google
- Google-Extended (token robots.txt) → rinuncia all'addestramento di Gemini / Vertex. Non ti rimuove dagli AI Overviews.
- Interruttore di opt-out IA di GSC (efficace dal 17 giu 2026) → rimuove i contenuti dagli AI Overviews e dall'AI Mode, mantiene il ranking normale. Esclude l'app Gemini.
- Disallow Googlebot → opzione nucleare; ti rimuove del tutto da Google, inclusa la ricerca normale che invia clic reali. Quasi mai la scelta giusta.
La configurazione predefinita consigliata per il 2026
Tre profili, una decisione. Scegli quello che corrisponde al tuo obiettivo e copia il robots.txt qui sotto.
Non esiste un'unica configurazione corretta — esiste una configurazione corretta per il tuo obiettivo. Ecco i tre profili che coprono quasi ogni piccolo sito, da «voglio essere in ogni risposta» a «tienimi del tutto fuori dall'IA».
| Profilo | Per chi | Bot di addestramento | Bot di ricerca | Perché |
|---|---|---|---|---|
| Massima visibilità | La maggior parte dei piccoli siti, blog, attività locali | Consentire tutto | Consentire tutto | Vuoi essere in ogni risposta. Il costo di banda è trascurabile su piccola scala, e bloccare l'addestramento ha effetti collaterali misurabili sulle citazioni. |
| Bloccare l'addestramento, mantenere le citazioni | Editori, siti di ricerca originale, chiunque rifiuti l'estrazione unilaterale | Bloccare GPTBot, ClaudeBot, Google-Extended, CCBot, Applebot-Extended, Bytespider (WAF) | Consentire OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User, Claude-User | L'impostazione predefinita di consenso del 2026 per le aziende di contenuti: fermare l'estrazione unilaterale, tenere aperto il canale delle citazioni. |
| Fuori dalle risposte IA del tutto | Contenuti a pagamento, in abbonamento o legalmente sensibili | Bloccare tutti i bot di addestramento | Bloccare tutti i bot di ricerca/risposta + attivare il nuovo opt-out di GSC (efficace dal 17 giu 2026) | Accetti la perdita di citazioni per tenere i contenuti fuori dalle superfici IA. Il ranking standard di Google non è influenzato dall'interruttore di GSC. |
Per la maggior parte dei piccoli siti, la raccomandazione onesta è il Profilo 1 — consentire tutto. Il tuo obiettivo è la visibilità, il costo di banda del crawling IA è trascurabile su piccola scala, e bloccare i crawler di addestramento comporta effetti collaterali sulle citazioni che non puoi prevedere del tutto. Il profilo «bloccare l'addestramento, mantenere le citazioni» (Profilo 2) è l'impostazione predefinita giusta per le aziende di contenuti, gli editori e chiunque pubblichi ricerca originale e rifiuti davvero l'estrazione unilaterale. Il Profilo 3 è solo per contenuti a pagamento, in abbonamento o legalmente sensibili.
Questa è la configurazione di consenso del 2026 per un sito di contenuti che vuole fermare l'addestramento gratuito pur restando citabile nella ricerca IA. Incollala in /robots.txt e aggiungi separatamente la regola di firewall per Bytespider (ignora robots.txt).
# --- Bloccare i crawler di ADDESTRAMENTO ---
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# --- CONSENTIRE i crawler di ricerca / risposta (è così che vieni citato) ---
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
# --- Tutto il resto ---
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xmlNote: sostituisci example.com con il tuo dominio. Bytespider richiede un blocco a livello di WAF o IP — un Disallow non lo ferma in modo affidabile. E ricorda che qui Google-Extended blocca solo l'addestramento di Gemini; per uscire dagli AI Overviews, usa il nuovo opt-out di Search Console (efficace dal 17 giugno 2026), non questo file.
L'igiene dei crawler apre la porta — il contenuto la rende degna di essere attraversata
Come vedere quali bot ti stanno davvero visitando
Prima di bloccare qualcosa, guarda i tuoi log. Potresti ottimizzare per un crawler che non viene mai — o bloccarne uno che genera tutte le tue citazioni.
Le regole scritte al buio sono ipotesi. Dedica venti minuti a guardare chi ti scansiona davvero prima di cambiare una singola riga, perché il panorama dei bot varia enormemente per nicchia. Ecco lo stack di monitoraggio pratico, dal più economico in poi:
- Log di accesso del server / CDN. Filtra per user-agent per
GPTBot,OAI-SearchBot,ChatGPT-User,ClaudeBot,Claude-SearchBot,PerplexityBot,CCBoteBytespider. Questo ti dice la frequenza e quali pagine tocca ogni bot. Nota:Google-Extendednon comparirà mai — è un token, non una richiesta. - Cloudflare Radar AI Insights. Se sei dietro Cloudflare, la dashboard gratuita AI Insights mostra l'attività dei crawler IA e i dati crawl-to-referral citati in questo articolo.
- Google Search Console. Il nuovo report sulle prestazioni IA (giugno 2026) è dove vedrai le impression di AI Overviews / AI Mode — e dove si trova l'interruttore di opt-out.
- Verifica l'autenticità. Gli user-agent falsificati sono comuni. Confronta gli accessi sospetti con gli intervalli IP pubblicati — OpenAI li elenca su
openai.com/gptbot.json,openai.com/searchbot.jsoneopenai.com/chatgpt-user.json.
Il check-up di igiene dei crawler in 30 minuti
- Estrai i log di accesso dell'ultimo mese; elenca ogni user-agent IA che ti ha visitato e con quale frequenza.
- Apri il tuo
robots.txtattuale. Menziona ancora solo GPTBot? Aggiornalo alla lista dei bot del 2026 con il profilo che corrisponde al tuo obiettivo. - Assicurati di non bloccare per errore
OAI-SearchBot,Claude-SearchBotoPerplexityBot— è l'errore del 71% degli editori. - Aggiungi una regola WAF per Bytespider se i tuoi log lo mostrano ignorare il tuo robots.txt.
- Decidi sugli AI Overviews separatamente: lasciali stare, o usa l'opt-out di GSC dal 17 giugno 2026. Non aspettarti che Google-Extended faccia quel lavoro.
- Facoltativamente, pubblica un
llms.txtse il tuo stack lo genera — poi dimenticalo e mettiti a scrivere contenuti.
→ Fallo ora: Apri https://il-tuo-dominio.com/robots.txt in un browser. Se non menziona OAI-SearchBot né Claude-SearchBot, è obsoleto — e potresti essere invisibile agli stessi prodotti di ricerca IA che i tuoi clienti usano. Scegli un profilo dalla tabella sopra, incolla la configurazione corrispondente, e avrai fatto più igiene dei crawler della stragrande maggioranza dei piccoli siti nel 2026.
Letture correlate
- AEO vs SEO nel 2026: perché i motori di risposta sono la nuova ricerca — una volta che i bot di ricerca possono leggerti, ecco come ottieni davvero la citazione.
- AI Overviews e SGE: come i piccoli siti possono ancora guadagnare clic — i dati sul danno di traffico dietro la decisione di opt-out.
- Schema markup per le piccole imprese — i dati strutturati che aiutano i crawler che hai ammesso a comprendere le tue pagine.
- SEO tecnico per non sviluppatori — robots.txt, sitemap e il resto degli ingranaggi, in parole chiare.
Riferimenti e fonti
Articolo disponibile anche in: