Por qué tu robots.txt está de pronto tres años desfasado
En 2023 necesitabas una línea para GPTBot. En 2026 un robots.txt moderno necesita reglas para una docena de bots de IA — y el viejo consejo de «bloquear toda la IA» ahora es contraproducente.
Si gestionas un sitio pequeño, hay bastantes probabilidades de que tu robots.txt no se haya tocado desde que añadiste una sola regla para GPTBot en 2023 — o de que nunca lo hayas tocado. Esa brecha importa más que antes. A mediados de 2025, los datos de red de Cloudflare mostraron que el rastreo de entrenamiento había crecido hasta cerca del 80% de toda la actividad de bots de IA, frente al 72% del año anterior.[3] Los rastreadores de IA son ya una parte significativa de quién llama a la puerta de tu servidor cada día, y las reglas que les des deciden dos cosas muy distintas: si tu contenido entrena gratis el modelo de otro, y si apareces cuando un comprador le pregunta algo a ChatGPT o Perplexity.
Lo que hace 2026 genuinamente diferente es que los grandes proveedores de IA dividieron su único rastreador en varios. OpenAI ya no opera un solo bot — opera GPTBot para entrenamiento, OAI-SearchBot para ChatGPT Search y ChatGPT-User para descargas bajo demanda. Anthropic opera tres. La consecuencia práctica: el movimiento instintivo de Disallow: / para cada user-agent de IA ahora hace dos trabajos a la vez. Te saca de los corpus de entrenamiento (a menudo lo que querías) y te borra de las respuestas de búsqueda de IA (casi nunca lo que querías). El análisis de Digital Applied del marco de Anthropic reporta que cerca del 71% de los grandes editores de noticias bloquean al menos un bot de recuperación o búsqueda, frecuentemente con la intención de bloquear solo el entrenamiento.[5] Ese es exactamente el error caro que esta guía evita.
La frase que explica todo el tema
Qué es llms.txt — y por qué probablemente no hará mucho
Una idea razonable con casi ninguna prueba de adopción detrás. Publícalo si es barato; no construyas una estrategia sobre él.
llms.txt es un archivo Markdown propuesto por la comunidad que colocas en la raíz de tu dominio (/llms.txt) y que lista tus páginas más importantes en formato limpio y parseable, para que un modelo de lenguaje encuentre y entienda tu mejor contenido sin atravesar navegación, anuncios y scripts. Lo propuso Jeremy Howard, de Answer.AI, en septiembre de 2024. La analogía habitual es «un sitemap para LLMs», y la intención es genuinamente sensata: dar a los modelos un mapa curado y de bajo ruido de lo que importa en tu sitio, opcionalmente con un /llms-full.txt más completo que inserte el contenido real.
El problema es la brecha entre la idea y la evidencia. Tras dieciocho meses de conversación en el sector, los datos son aleccionadores:
- La adopción es de uno de cada diez sitios. El estudio de SE Ranking sobre 300.000 dominios halló un 10,13% de adopción, y, crucialmente, la adopción fue casi idéntica en los niveles de tráfico bajo, medio y alto (~9–10% cada uno) — así que no son los sitios sofisticados los que corren por delante.[1]
- Sin mejora medible en citaciones. El mismo análisis de SE Ranking no halló diferencia estadísticamente significativa en la frecuencia de citaciones de IA entre sitios con y sin llms.txt. Un modelo entrenado con datos de citaciones de IA incluso mejoró cuando se eliminó la variable llms.txt.[1]
- Casi nada lo lee. Limy.AI monitorizó más de 500 millones de eventos de bots de IA en 90 días y halló solo 408 solicitudes dirigidas a llms.txt directamente.[14] Search Engine Land siguió 10 sitios 90 días antes y después de añadir el archivo; solo dos vieron aumentos de tráfico de IA, y no por el archivo.[2]
- Sin soporte oficial. A mediados de 2026, ni OpenAI, ni Anthropic, ni Google, ni Perplexity han confirmado oficialmente que sus sistemas lean o actúen sobre llms.txt. Sigue siendo una especificación comunitaria, no un estándar adoptado.
llms.txt: la realidad de adopción vs impacto
Uno de cada diez sitios lo tiene; el beneficio medible hasta ahora es casi cero[1][14]
Esto no es un argumento para no publicar nunca un llms.txt — cuesta casi nada y es compatible a futuro si las plataformas formalizan el soporte. Es un argumento contra tratarlo como una palanca de crecimiento. Dedica los diez minutos si quieres; no le dediques una reunión de estrategia.
La opinión honesta para un sitio pequeño
robots.txt. Ese es el que los rastreadores obedecen genuinamente, y el que decide si estás (o no) en las respuestas que leen tus clientes.robots.txt vs llms.txt: la comparación honesta
Mismo directorio raíz, poderes completamente distintos. Uno es exigible; el otro es una petición cortés que nadie está obligado a leer.
| Dimensión | robots.txt | llms.txt |
|---|---|---|
| Qué es | Un archivo de control de acceso que dice a los rastreadores qué pueden y no pueden descargar | Un archivo de curación en Markdown que lista tus mejores páginas para que un LLM las encuentre y parsee |
| Antigüedad y estatus | Robots Exclusion Protocol — un estándar web de ~30 años, ahora un RFC del IETF | Una propuesta comunitaria de sept 2024 (Jeremy Howard / Answer.AI). No es un estándar oficial |
| Ubicación | /robots.txt en la raíz de tu dominio | /llms.txt en la raíz de tu dominio (opcionalmente un /llms-full.txt más completo) |
| Cumplimiento | Respetado por todos los grandes rastreadores de IA (salvo algunos como Bytespider) | Solo informativo — ningún rastreador está obligado a leerlo o actuar sobre él |
| Quién lo consume de verdad | OpenAI, Anthropic, Perplexity, Google y Common Crawl lo leen | Ninguna gran plataforma de IA ha confirmado oficialmente que lee llms.txt (mediados de 2026) |
| Impacto medido | Controla directamente si un bot puede rastrear una ruta | El estudio de 300k dominios de SE Ranking no halló mejora significativa en citaciones |
| Qué no puede hacer | No puede frenar a un bot incumplidor y no controla los AI Overviews (índice de Googlebot) | No puede bloquear nada — es una sugerencia, no una puerta |
| ¿Vale la pena en 2026? | Sí — es tu palanca real. Mantenlo al día con la lista de bots de 2026 | Bajo coste, bajo riesgo, baja recompensa. Publícalo si es barato; no esperes tráfico de él |
La conclusión no es «llms.txt es inútil» — es que los dos archivos no son intercambiables, y el que de verdad cambia resultados hoy es el aburrido y antiguo. Si en 2026 solo tienes tiempo de dejar bien un archivo, que sea robots.txt, con reglas que reflejen el panorama actual de rastreadores de IA y no la versión de 2023.
El zoo de rastreadores de IA de 2026: quién te visita
Cada motor de IA opera su propio rastreador — y la mayoría operan dos o tres, cada uno con un trabajo distinto y una respuesta correcta distinta.
Antes de escribir una regla sensata, necesitas saber para qué sirve cada bot. Cada rastreador de IA hace uno de tres trabajos: recopila páginas para entrenar modelos, indexa páginas para respuestas de búsqueda de IA, o descarga una página en tiempo real porque un usuario le preguntó al asistente por ella ahora mismo. Son relaciones comerciales distintas, y en 2026 los grandes proveedores por fin las exponen como bots distintos que puedes controlar de forma independiente.
Los bots que verás más
| Bot | Propietario | Propósito | ¿robots.txt? | Decisión por defecto 2026 |
|---|---|---|---|---|
GPTBot | OpenAI | Entrenamiento — alimenta futuros modelos GPT | Sí | Bloquéalo si no quieres entrenar modelos gratis; permítelo si buscas máximo alcance futuro |
OAI-SearchBot | OpenAI | Indexa páginas para ChatGPT Search | Sí | PERMITIR — bloquearlo te elimina de las respuestas de ChatGPT Search |
ChatGPT-User | OpenAI | Descarga bajo demanda cuando un usuario abre tu URL | Sí | PERMITIR — bloquearlo rompe una descarga que el usuario pidió |
ClaudeBot | Anthropic | Entrenamiento — alimenta el corpus de Claude | Sí | Bloquéalo para no entrenar; es el rastreador más extractivo por ratio crawl-to-referral |
Claude-SearchBot | Anthropic | Indexa páginas para la búsqueda web de Claude | Sí | PERMITIR — así te cita Claude (nuevo en 2026) |
PerplexityBot | Perplexity | Indexa páginas para que Perplexity las cite | Sí (con matiz de rastreo sigiloso) | PERMITIR — Perplexity es el motor más amigable para sitios pequeños |
Google-Extended | Token de control — rige el uso de páginas ya rastreadas para entrenar Gemini/Vertex | Sí (es un token, no un bot — nunca en tus logs) | Opt-out opcional del entrenamiento de Gemini. NO controla los AI Overviews — usa el nuevo opt-out de GSC para eso | |
CCBot | Common Crawl | Corpus público que alimenta a muchos entrenadores de modelos | Sí | Bloquéalo para no entrar en el corpus abierto; inofensivo si lo permites |
Bytespider | ByteDance | Entrenamiento — alimenta a Doubao | No — incumplimiento documentado | Bloquéalo a nivel de WAF / IP — el robots.txt solo no lo detiene |
Dos filas merecen una segunda lectura. Google-Extended no es un rastreador real — es un token de control que nunca aparece en tus logs de servidor como una solicitud HTTP. Solo rige si Google puede usar páginas que ya ha rastreado (con el Googlebot normal) para entrenar Gemini y Vertex AI. Y Bytespider (ByteDance) tiene un historial documentado de ignorar robots.txt de forma inconsistente, por lo que bloquearlo requiere una regla de firewall o a nivel de IP en lugar de un cortés Disallow.
La distinción que hace todo el trabajo
GPTBot no es OAI-SearchBot. ClaudeBot no es Claude-SearchBot. Trátalos como un solo grupo y te borras del canal de referidos que más crece del año.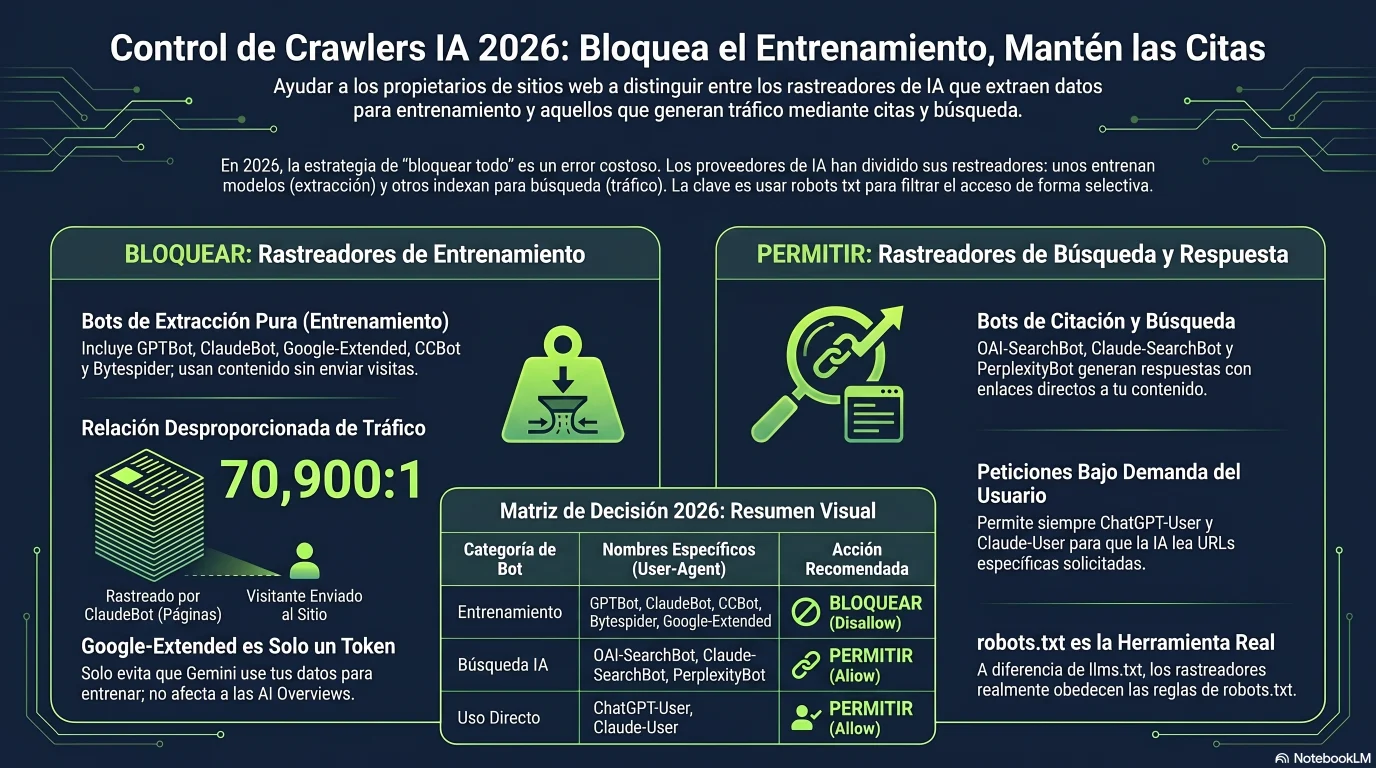
La economía: pérdida de tráfico vs pérdida de citaciones
La decisión de bloquear o permitir es en realidad un intercambio entre dos tipos de pérdida. El ratio crawl-to-referral de Cloudflare es el número que lo enmarca.
El argumento de negocio para bloquear los rastreadores de entrenamiento se reduce a un único ratio: cuántas de tus páginas rastrea un bot por cada visitante que te envía de vuelta. Cloudflare publica este ratio crawl-to-referral en su red, y la dispersión entre proveedores es extraordinaria. El Googlebot tradicional ronda las 5 páginas rastreadas por referido. El ClaudeBot de Anthropic, en su pico de junio de 2025, rastreaba aproximadamente 70.900 páginas por cada visitante que refería de vuelta — una asimetría que replantea el acceso de entrenamiento como una extracción de valor unilateral.[5]
Ratio crawl-to-referral — páginas rastreadas por 1 visitante enviado de vuelta
Cuanto más bajo, más justo para el editor. Los rastreadores de entrenamiento toman mucho más de lo que dan[3][5][9]
Las barras están en una sola escala lineal, por eso todo lo que está por debajo de ClaudeBot parece diminuto — ese es el punto. El pico de ClaudeBot (~70.900:1) y GPTBot (1.276:1) empequeñecen a Googlebot (~5:1) y DuckDuckGo (~1,5:1). Para julio de 2025 Anthropic había mejorado a ~38.000:1 y Perplexity estaba en 194:1, pero la brecha sigue siendo enorme.
Pero hay una trampa que impide que «solo bloquea los bots de entrenamiento» sea gratis, y es el matiz más importante de todo este artículo. El bloqueo tiene efectos secundarios en las citaciones. El análisis de AuthorityTech de 2026 halló que los sitios que bloquean Google-Extended tienen mucha menos probabilidad de ser citados por motores generativos — incluso en AI Overviews, donde Google técnicamente conserva el acceso al contenido a través del índice normal.[11] Y los datos de ppc.land muestran que el bloqueo es poroso en la otra dirección también: bloquear rastreadores de IA no detiene de forma fiable las citaciones, porque los motores tiran de rutas alternativas, citas de terceros y copias en caché.[10] Puedes perder el beneficio de visibilidad sin ganar del todo la privacidad por la que bloqueaste.
Al otro lado de la balanza está el daño de tráfico que empuja a la gente a bloquear en primer lugar. Los AI Overviews de Google han recortado medibles el tráfico de referidos: Digital Content Next reporta caídas de tráfico del 1–25% para miembros, con media en torno al 25%, y los CTR caen entre 34,5% y 79% cuando aparece un AI Overview, según el tipo de consulta.[8] Los editores encuestados por ppc.land esperan una caída adicional de tráfico del 43% en los próximos tres años.[10] Cuando la IA te quita tráfico y a la vez te rastrea 70.000 a 1, las ganas de levantar el puente levadizo son comprensibles.
Lo que los AI Overviews hacen al tráfico de sitios pequeños
El daño que empuja a los dueños a bloquear — y por qué la decisión se siente urgente[8][10]
Cerca de una cuarta parte de los 1.000 sitios principales bloquean ahora GPTBot. Pero fíjate en lo que bloquear solo GPTBot no hace: no te retira de los AI Overviews (índice distinto), y no impide que ChatGPT Search te cite (eso es OAI-SearchBot). El daño de tráfico y el rastreador que bloqueas a menudo ni siquiera están conectados.
La cuota de rastreadores de IA se consolida en torno a dos actores
GPTBot y ClaudeBot más que duplicaron su cuota de rastreo de IA; Bytespider se desplomó[3]
Entre 2024 y mediados de 2025, la cuota de rastreo de IA de GPTBot subió del 4,7% al 11,7% y la de ClaudeBot del 6% a ~10%, mientras Bytespider de ByteDance cayó del 14,1% al 2,4%. En mayo de 2026, el Claude-SearchBot dedicado de Anthropic apareció con un 2,00% de cuota — la primera vez que el rastreador de búsqueda de un gran proveedor aparece como un actor distinto y de tamaño notable.

El nuevo opt-out de Google — y por qué Google-Extended no lo es
El control que los editores llevaban dos años pidiendo por fin llegó en junio de 2026. No es lo mismo que Google-Extended, y la diferencia importa.
Durante dos años, la pregunta más repetida sobre rastreadores de IA fue alguna versión de: «¿Cómo aparezco en la búsqueda normal de Google pero no en los AI Overviews?». Hasta junio de 2026, la respuesta honesta era «no puedes». Google-Extended — el token al que la mayoría recurría — solo controla si Google entrena Gemini y Vertex AI con tus páginas ya rastreadas. Nunca ha controlado los AI Overviews ni AI Mode, que tiran del índice estándar de Googlebot. Bloquear Google-Extended no hacía nada para mantenerte fuera de los resúmenes de IA que de verdad se comían tus clics.[8]
Eso cambió el 3 de junio de 2026, cuando Google lanzó un informe de rendimiento de IA en Search Console junto a un toggle de opt-out que permite a los editores retirar contenido de los AI Overviews y AI Mode sin perder el ranking de búsqueda estándar.[6] El ajuste surte efecto el 17 de junio de 2026, cuando Google empieza a actuar sobre la señal, y activarlo no afecta tu posición en los resultados normales de Google.[7] Dos matices que conviene leer dos veces: la app Gemini queda excluida de este opt-out (es un producto separado), y optar por salir significa aceptar que desaparece también la citación/visibilidad que obtenías de los AIO.
Qué hace cada palanca de Google
- Google-Extended (token de robots.txt) → opt-out del entrenamiento de Gemini / Vertex. No te retira de los AI Overviews.
- Toggle de opt-out de IA en GSC (efectivo 17 jun 2026) → retira contenido de AI Overviews y AI Mode, conserva el ranking normal. Excluye la app Gemini.
- Disallow Googlebot → opción nuclear; te retira de Google por completo, incluida la búsqueda normal que sí envía clics reales. Casi nunca es lo correcto.
La configuración por defecto recomendada para 2026
Tres perfiles, una decisión. Elige el que coincida con tu objetivo y copia el robots.txt de abajo.
No hay una única configuración correcta — hay una configuración correcta para tu objetivo. Estos son los tres perfiles que cubren casi cualquier sitio pequeño, desde «quiero estar en cada respuesta» hasta «mantenme fuera de la IA por completo».
| Perfil | Para quién | Bots de entrenamiento | Bots de búsqueda | Por qué |
|---|---|---|---|---|
| Máxima visibilidad | La mayoría de sitios pequeños, blogs, negocios locales | Permitir todo | Permitir todo | Quieres estar en cada respuesta. El coste de ancho de banda es trivial a pequeña escala y bloquear el entrenamiento tiene efectos secundarios en las citaciones. |
| Bloquear entrenamiento, mantener citaciones | Editores, sitios de investigación original, quien rechace la extracción unilateral | Bloquear GPTBot, ClaudeBot, Google-Extended, CCBot, Applebot-Extended, Bytespider (WAF) | Permitir OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User, Claude-User | El default de consenso de 2026 para negocios de contenido: frena la extracción unilateral, mantén abierto el canal de citaciones. |
| Fuera de las respuestas de IA por completo | Contenido de pago, de membresía o legalmente sensible | Bloquear todos los bots de entrenamiento | Bloquear todos los bots de búsqueda/respuesta + activar el nuevo opt-out de GSC (efectivo 17 jun 2026) | Aceptas la pérdida de citaciones para mantener el contenido fuera de las superficies de IA. El ranking estándar de Google no se ve afectado por el toggle de GSC. |
Para la mayoría de sitios pequeños, la recomendación honesta es el Perfil 1 — permitir todo. Tu objetivo es la visibilidad, el coste de ancho de banda del rastreo de IA es trivial a pequeña escala, y bloquear los rastreadores de entrenamiento conlleva efectos secundarios en las citaciones que no puedes predecir del todo. El perfil «bloquear entrenamiento, mantener citaciones» (Perfil 2) es el default correcto para negocios de contenido, editores y cualquiera que publique investigación original que de verdad rechace la extracción unilateral. El Perfil 3 es solo para contenido de pago, de membresía o legalmente sensible.
Esta es la configuración de consenso de 2026 para un sitio de contenido que quiere frenar el entrenamiento gratis pero seguir siendo citable en la búsqueda de IA. Pégala en /robots.txt y añade la regla de firewall para Bytespider por separado (ignora robots.txt).
# --- Bloquear rastreadores de ENTRENAMIENTO ---
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# --- PERMITIR rastreadores de búsqueda / respuesta (así te citan) ---
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
# --- Todo lo demás ---
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xmlNotas: reemplaza example.com por tu dominio. Bytespider necesita un bloqueo a nivel de WAF o IP — un Disallow no lo detiene de forma fiable. Y recuerda que aquí Google-Extended solo bloquea el entrenamiento de Gemini; para salir de los AI Overviews, usa el nuevo opt-out de Search Console (efectivo 17 jun 2026), no este archivo.
La higiene de rastreadores abre la puerta — el contenido la mantiene digna de cruzar
Cómo ver qué bots te están visitando de verdad
Antes de bloquear nada, mira tus logs. Puede que estés optimizando para un rastreador que nunca te visita — o bloqueando uno que impulsa todas tus citaciones.
Las reglas escritas a oscuras son conjeturas. Dedica veinte minutos a mirar quién te rastrea de verdad antes de cambiar una sola línea, porque el panorama de bots varía enormemente por nicho. Esta es la pila de monitorización práctica, de lo más barato a lo demás:
- Logs de acceso del servidor / CDN. Filtra por user-agent para
GPTBot,OAI-SearchBot,ChatGPT-User,ClaudeBot,Claude-SearchBot,PerplexityBot,CCBotyBytespider. Esto te dice frecuencia y qué páginas toca cada bot. Nota:Google-Extendednunca aparecerá — es un token, no una solicitud. - Cloudflare Radar AI Insights. Si estás tras Cloudflare, el panel gratuito AI Insights muestra la actividad de rastreadores de IA y los datos crawl-to-referral citados en este artículo.
- Google Search Console. El nuevo informe de rendimiento de IA (junio 2026) es donde verás las impresiones de AI Overviews / AI Mode — y donde vive el toggle de opt-out.
- Verifica la autenticidad. Los user-agents falsificados son comunes. Coteja los accesos sospechosos contra los rangos de IP publicados — OpenAI los lista en
openai.com/gptbot.json,openai.com/searchbot.jsonyopenai.com/chatgpt-user.json.
El chequeo de higiene de rastreadores en 30 minutos
- Saca los logs de acceso del último mes; lista cada user-agent de IA que te visitó y con qué frecuencia.
- Abre tu
robots.txtactual. ¿Sigue mencionando solo GPTBot? Actualízalo a la lista de bots de 2026 con el perfil que coincida con tu objetivo. - Asegúrate de no estar bloqueando por accidente
OAI-SearchBot,Claude-SearchBotoPerplexityBot— ese es el error del 71% de los editores. - Añade una regla de WAF para Bytespider si tus logs lo muestran ignorando tu robots.txt.
- Decide sobre los AI Overviews por separado: déjalos estar, o usa el opt-out de GSC desde el 17 jun 2026. No esperes que Google-Extended haga ese trabajo.
- Opcionalmente, publica un
llms.txtsi tu stack lo genera — luego olvídalo y ponte a escribir contenido.
→ Hazlo ahora: Abre https://tu-dominio.com/robots.txt en un navegador. Si no menciona OAI-SearchBot ni Claude-SearchBot, está desfasado — y puede que seas invisible para los mismos productos de búsqueda de IA que usan tus clientes. Elige un perfil de la tabla de arriba, pega la configuración correspondiente, y habrás hecho más higiene de rastreadores que la inmensa mayoría de sitios pequeños en 2026.
Lecturas relacionadas
- AEO vs SEO en 2026: por qué los motores de respuesta son la nueva búsqueda — una vez que los bots de búsqueda pueden leerte, así ganas de verdad la citación.
- Resúmenes de IA y SGE: cómo los sitios pequeños pueden seguir ganando clics — los datos del daño de tráfico detrás de la decisión de opt-out.
- Schema markup para pequeñas empresas — los datos estructurados que ayudan a los rastreadores que permitiste a entender tus páginas.
- SEO técnico para no desarrolladores — robots.txt, sitemaps y el resto de la fontanería, en lenguaje claro.
Referencias y fuentes
Artículo también disponible en: