Wie KI-Zitate wirklich funktionieren
Bevor du zitiert werden kannst, musst du die zwei völlig unterschiedlichen Wege verstehen, auf denen dich eine Answer-Engine finden kann.
Von einer KI-Answer-Engine zitiert zu werden bedeutet, die Quelle zu sein, die das Modell beim Verfassen einer Antwort zitiert, nennt oder verlinkt. Doch dorthin führt nicht ein Weg — es sind zwei, und sie verhalten sich so unterschiedlich, dass für den einen zu optimieren und den anderen zu ignorieren der häufigste Grund ist, warum guter Content nie zitiert wird.
Der erste Weg ist parametrisches Wissen — das, was das Modell aus seinen Trainingsdaten aufgenommen hat und nun aus dem Gedächtnis abruft. Der zweite ist abgerufenes Wissen — das, was es zur Antwortzeit live aus dem Web zieht, via Retrieval-Augmented Generation (RAG). Die Aufteilung ist enorm wichtig: Laut der Synthese von The Digital Bloom vom Dezember 2025 werden rund 60 % der ChatGPT-Anfragen rein aus dem parametrischen Gedächtnis beantwortet, ohne überhaupt eine Websuche auszulösen, und eine Praktiker-Schätzung setzt die Live-Websuche bei nur ~31 % der Prompts an.[9] Bei den meisten Antworten ist es dein Trainingsdaten-Fußabdruck, der dich erwähnt macht — wie oft und wie konsistent deine Marke im offenen Web erscheint — nicht irgendein Live-SEO-Zug.
Wenn eine Engine doch abruft, entscheidet eine mehrstufige Pipeline, was das Modell erreicht:
- Anfrage-Kodierung: Die Frage des Nutzers wird zu einem Vektor-Embedding (z. B. OpenAIs text-embedding-3-large mit 3.072 Dimensionen).
- Hybrider Abruf: Die dichte semantische Suche (Embeddings) wird mit dem spärlichen Keyword-Matching (BM25) fusioniert — eine Kombination, die rund 48 % Verbesserung gegenüber jeder Methode allein liefert.[9]
- Reranking: Cross-Encoder-Modelle bewerten die Kandidatenpassagen für die konkrete Anfrage neu (verbessern die Ranking-Qualität um ~28 % bei NDCG@10).
- Generierung: Nur die 5–10 besten abgerufenen Chunks werden als Kontext in den Prompt injiziert. Alles andere ist für das Modell bei dieser Antwort unsichtbar.
Diese letzte Zahl ist das ganze Spiel. Wenn deine Antwort über einen langen, fließenden Essay verschmiert ist, ist kein einzelner Chunk eigenständig, und du verlierst den Platz an einen Wettbewerber, dessen Passage für sich allein steht. Wie Discovered Labs es formulierte, wählen KI-Engines nach semantischer Relevanz, Entitätsklarheit und Drittvalidierung aus — nicht nach Link-Equity wie das klassische SEO.
Zwei Fußabdrücke, zwei Strategien
Answer-Engines, die dieser Leitfaden abdeckt
Der Top-10-Mythos: die ehrlichen Zahlen
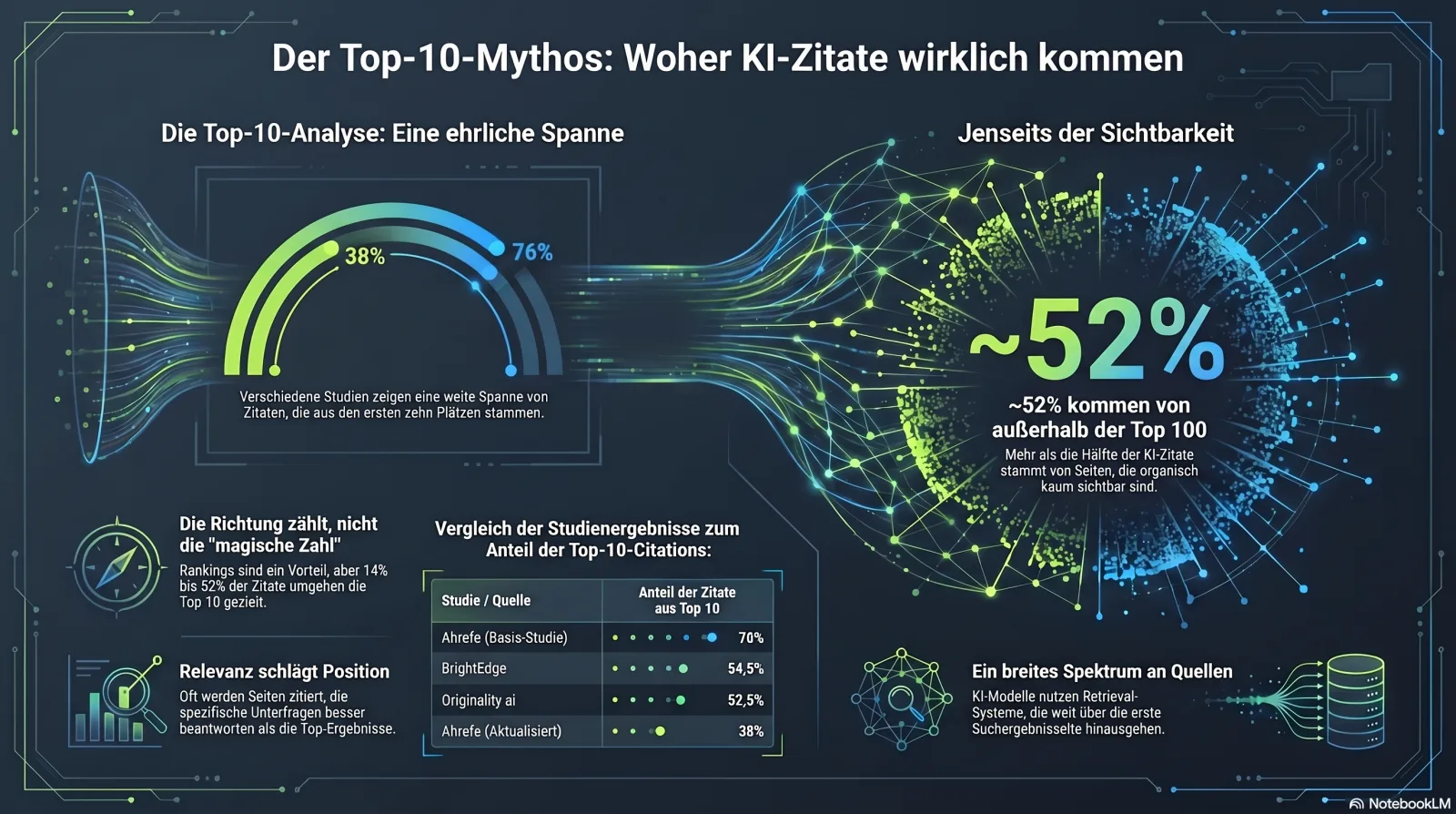
Du hast '76 % der KI-Zitate kommen aus den Top 10' gesehen. Du hast auch 38 % gesehen. Beides ist real. Hier ist der Grund.
Die meistzitierte Statistik in diesem Bereich ist irgendeine Version von „Die meisten KI-Zitate kommen von Seiten, die bereits in Googles Top 10 ranken." Sie ist zugleich wahr, teilweise wahr und irreführend — abhängig völlig davon, welche Studie du liest und wie sie gezählt hat. Hier ist die ehrliche Spanne:
Welcher Anteil der KI-Engine-Zitate kommt aus der organischen Top 10?
Fünf glaubwürdige Messungen, die sich widersprechen — weil sie Verschiedenes gemessen haben[2][3][4]
Diese Zahlen sind NICHT widersprüchlich. Ahrefs' 76 % zählt zitierte Seiten, die im gesamten Zitat-Set top-10 ranken; Originality.ais 52,5 % ist der Top-10-Anteil nur der Zitate, die sich mit den Top 100 überschneiden; die 38-%-Lesart kam später von einer anderen Keyword-Stichprobe, als das Fan-out tiefere Seiten zog. Die ehrliche Erkenntnis ist eine Spanne und eine Richtung — keine magische Einzelzahl.
Zusammen gelesen sind drei Dinge klar wahr:
- Gut zu ranken ist ein starker Rückenwind. Ahrefs' Analyse von 1,9 Mio. Zitaten über 1 Mio. AI Overviews fand, dass 76,1 % der zitierten Seiten in den Top 10 ranken, mit einem mittleren zitierten Rang von 3 und der primär zitierten URL auf einer mittleren Position von 2.[2] Wenn du ranken kannst, ranke.
- Aber es ist keine Garantie. Selbst dass das #1-Ergebnis zitiert wird, ist in Ahrefs' Worten „bestenfalls ein Münzwurf". Originality.ai beziffert die Zitatwahrscheinlichkeit eines Top-1-Ergebnisses auf rund 58 %.[3]
- Und eine große Minderheit der Zitate umgeht die Top 10 vollständig. Originality.ai fand, dass ~52 % aller AI-Overview-Zitate von Seiten außerhalb der Top 100 kommen; Ahrefs fand 14,4 % von Seiten, die überhaupt nicht top-100 ranken.[2][3] Diese Lücke ist die Öffnung für alle, die die Platzhirsche nicht überranken können.
Der Konvergenztrend zählt auch. BrightEdges 16-monatige Längsschnittstudie fand, dass die Überschneidung von AI Overviews mit dem Organischen von 32,3 % beim Start (Mai 2024) auf 54,5 % bis Ende 2025 stieg, wobei YMYL-Bereiche am meisten überschnitten — Gesundheit bei 75,3 %, Bildung bei 72,6 %.[4] In vertrauenswürdigen, risikoreichen Kategorien konvergieren klassisches Ranking und KI-Zitat. In allem anderen ist die Hintertür weiter offen.
Die Hintertür ist strukturell, nicht zufällig
ChatGPT vs. Perplexity vs. Google AIO
Die drei großen Engines rufen ab und zitieren unterschiedlich. Wo du investierst, hängt davon ab, welche deine Käufer nutzen.
„Für KI optimieren" ist zu grob, um danach zu handeln. Jede Engine hat eine eigene Abruf-Pipeline und einen eigenen Satz von Quellen, auf die sie sich stützt. Hier ist, wie sich die drei größten unterscheiden und was jeder Unterschied für deinen nächsten Zug bedeutet.
| Engine | Wie sie abruft | Was zitiert wird | Dein Zug |
|---|---|---|---|
| ChatGPT (Search) | Zuerst parametrisch — nur ~31 % der Prompts lösen eine Live-Websuche aus; sonst wird aus dem Trainingsdaten-Gedächtnis geantwortet. Nutzt den Bing-Index, wenn doch gesucht wird. | Wikipedia dominiert die Top-Quellen (47,9 %), dann Reddit und Forbes. Marken werden zur Trainingszeit häufig im offenen Web erwähnt. | Baue breite, konsistente Markenerwähnungen im Web auf (damit du in den Trainingsdaten lebst) UND strukturiere Seiten für den Live-Abruf. |
| Perplexity | Echtzeit-RAG bei jeder Anfrage. Sechsstufige Pipeline: Intent → hybrider Abruf (BM25 + dicht) → 3-stufiger Reranker → Prompt-Zusammenstellung mit vorab eingebetteten Zitaten → Synthese. Zitiert immer. Indexiert über 200 Mrd. URLs. | Reddit (46,7 %), YouTube, Gartner. Autoritative Quellen, frische URLs, originale First-Party-Daten. Bringt Nischen-Blogs problemlos an die Oberfläche. | Größter Hebel für kleine Sites. In sich geschlossene, statistikhaltige Passagen + Originaldaten gewinnen Zitate auch ohne Top-10-Ranking. |
| Googles KI-Übersichten | Im Google-Index über das Deep-Learning-Modell FastSearch / RankEmbed verankert — trainiert mit Klick- + Quality-Rater-Daten, priorisiert semantisches Matching und Geschwindigkeit über klassische Link-Signale. | Reddit (21 %), YouTube, Quora, LinkedIn — die vielfältigste der drei. Teilweise Überschneidung mit dem klassischen organischen Ranking. | Gut ranken (starker Rückenwind) UND Fan-out-Unterfragen beantworten. 14–52 % der Zitate kommen je nach Studie von außerhalb der Top 10. |
Perplexity ist die Engine mit dem größten Hebel für eine kleine Site. Sie führt bei jeder einzelnen Anfrage Echtzeit-RAG aus, zitiert immer, bringt 4–8 Quellen pro Antwort an die Oberfläche und zieht problemlos Nischen-Blogs und Reddit-Threads neben Wikipedia. Wenn du deine Zitat-Arbeit am schnellsten Früchte tragen sehen willst, ziele zuerst auf Perplexity — ihr Produktdesign ist strukturell freundlich zu kleineren, gut strukturierten Quellen.
Woher jede Engine ihre Top-Zitate zieht
Profounds 680-Mio.-Zitate-Studie — der Quellenmix ist pro Plattform völlig unterschiedlich[7]
ChatGPT stützt sich auf Wikipedia (47,9 % seines Top-Quellen-Anteils); Perplexity stützt sich auf Reddit (46,7 %); Googles KI-Übersichten sind am vielfältigsten und verteilen sich über Reddit, YouTube, Quora und LinkedIn. Eine Implikation: Ein Reddit-Thread oder eine starke Wikipedia-Entität über dich kann mehr wert sein als eine weitere Seite auf deiner eigenen Domain.
Überindexiere nicht auf den Quellenmix einer einzelnen Plattform
Die 7 zitierfreundlichen Schreibmuster
Das ist der Teil, den du voll kontrollierst. Sieben strukturelle Züge, jeder mit einem gemessenen oder mechanistischen Grund, warum er Zitate gewinnt.
Die grundlegende akademische Quelle hier ist die GEO-Studie (Aggarwal et al., Princeton / Georgia Tech / IIT Delhi / Allen Institute, KDD 2024). Über einen Benchmark vielfältiger Anfragen steigerten GEO-Methoden die Quellsichtbarkeit in generativen Antworten um bis zu 40 %, und die drei leistungsstärksten Taktiken waren bemerkenswert langweilig: Statistiken hinzufügen, Zitate hinzufügen und eigene Quellen zitieren.[1] Hier sind die sieben Muster, die aus dieser Arbeit und ihren Branchen-Replikationen folgen, sortiert nach Schwierigkeit.
| Muster | Warum es Zitate gewinnt | Schwierigkeit |
|---|---|---|
| Mit der Antwort beginnen (umgekehrte Pyramide, 40–60 Wörter) | RAG injiziert nur die 5–10 besten abgerufenen Chunks. Eine in sich geschlossene direkte Antwort bildet das Anfrage-Embedding sauber ab und wird nahezu wörtlich übernommen. | Einfach |
| An jede Aussage eine Statistik mit Quellenangabe anhängen | GEOs 'Statistik-Ergänzung' steigerte die Sichtbarkeit um ~22 %. 'Laut [Quelle, Datum] ist X gleich Y %' gibt dem Modell ein zitierfähiges, belegbares Atom. | Einfach |
| Experten-Zitate hinzufügen | GEOs 'Zitat-Ergänzung' war die stärkste Einzeltaktik — ~37 % Schub. Direkte Zitate benannter Autoritäten lesen sich als zitierfähige Belege. | Mittel |
| Eigene glaubwürdige Quellen zitieren | Kontraintuitiv, aber gemessen: GEOs 'Quellen zitieren' steigerte die EIGENE Sichtbarkeit der zitierenden Seite um ~30 %. Primärdaten zu referenzieren lässt dich wie ein Hub wirken. | Einfach |
| Entitäten explizit definieren, konsistent benennen | Definitorische 'X ist ein …'-Sätze + konsistente Benennung im Web stärken die neuronale Repräsentation der Entität und verbessern Recall und Abruf-Matching. | Mittel |
| Für den Abruf chunken — in sich geschlossene 200–500-Wort-Passagen | NVIDIA-Benchmarks: Seitenebenen-Chunking erreichte 0,648 Genauigkeit mit der geringsten Varianz. Jeder Abschnitt muss eine Anfrage isoliert beantworten — definieren, antworten, belegen, alles in einer Passage. | Mittel |
| Die NÄCHSTE logische Frage in angrenzenden Passagen beantworten | Engines erzeugen Fan-out-Unterabfragen und ziehen den Chunk, der jede am besten beantwortet. Komplementäre Abdeckung gewinnt Zitate, auch wenn du nicht in den Top 10 rankst (Jim Yu, BrightEdge). | Schwer |
GEO-Taktiken nach gemessenem Sichtbarkeitsschub
Aus dem GEO-Paper von KDD 2024 + der Branchen-Replikation von The Digital Bloom[1][9]
Der kontraintuitive Gewinner: eigene glaubwürdige Quellen zu zitieren erhöht deine Zitat-Chancen. Das Modell liest eine gut referenzierte Seite als vertrauenswürdigen Hub. Die Zitat-Ergänzung (~37 %) war die stärkste Einzeltaktik im GEO-Benchmark.
Die drei Züge für diese Woche
1. Schreibe die Einleitungen deiner fünf besten Artikel als direkte Antworten um. Vierzig bis sechzig Wörter, mit der exakten Frageformulierung als H2 direkt darüber. Streiche jeden „in diesem Artikel werden wir untersuchen …"-Einstieg. Dieser eine Block ist das, was ChatGPT, Perplexity und Google AIO am häufigsten anheben, oft wörtlich. Beginne mit der Antwort; erkläre danach.
2. Hänge an jede wichtige Aussage eine zugeschriebene Statistik. „Laut [Quelle, Datum] ist X gleich Y %." Das tut zwei Dinge zugleich: Es erfüllt GEOs Statistik-Ergänzungs-Taktik und gibt dem Modell ein in sich geschlossenes, belegbares Atom, das es risikolos zitieren kann. Vage Aussagen („viele Experten glauben") sind das Gegenteil — unzitierbar.
3. Zerlege lange Abschnitte in in sich geschlossene 200–500-Wort-Passagen. NVIDIAs Abruf-Benchmarks fanden, dass Seitenebenen-Chunking 0,648 Genauigkeit mit der geringsten Varianz erreichte.[9] Jede Passage sollte die Entität definieren, eine Frage beantworten und ihre stützende Statistik tragen — denn das Modell kann diese Passage in völliger Isolation vom Rest deiner Seite sehen.
Originaldaten: der stärkste Hebel
Wenn du der Ursprung einer Zahl bist, bist du das natürliche Zitat für diese Zahl. Nichts anderes verstärkt sich so.
Die am besten belegte Einzeltaktik in der gesamten Literatur ist die Veröffentlichung originaler, proprietärer Daten. Der Mechanismus ist einfach: Wenn du eine Umfrage durchführst, einen Benchmark veröffentlichst oder eine Studie herausgibst, wirst du zum Ursprung einer Statistik. Jedes Modell, das diese Zahl nutzen will, hat genau einen Ort, dem es sie zuschreiben kann — dir. Eine proprietäre Statistik ist das „zitierfähige Atom", das Answer-Engines wörtlich anheben, und anders als ein gut geschriebener Absatz kann kein Wettbewerber sie einfach besser umschreiben.
Hier ist die Datenlage auch am deutlichsten darüber, was nicht funktioniert. SolCrys' 17.551-Zitate-Studie der AEO-Kaufratgeber-Kategorie fand, dass die eigenen „.com"-Seiten der Anbieter zusammen nur 0,85 % aller Zitate ausmachten — während Wikipedia, TechRadar und Reddit dominierten.[10] Selbst SolCrys, der Herausgeber der Studie, wurde nur mit einer Kategorie-Erwähnungsrate von 4,82 % zitiert.
Was ein KI-Zitat tatsächlich vorhersagt (und was nicht)
Markenpräsenz schlägt Backlinks; deine eigene Verkaufsseite registriert kaum[9][10]
Das Marken-Suchvolumen korreliert mit LLM-Zitaten bei 0,334 — höher als jede Link-Metrik (The Digital Bloom). Derweil machen anbietereigene Eigenwerbungs-Seiten 0,85 % der Zitate aus (SolCrys). Die Erkenntnis: eine redaktionelle Drittquellen-Erwähnung oder ein Reddit-Thread über dich ist weit zitierfähiger als deine eigene „Wir sind die Besten"-Seite.
Der Originaldaten-Zug für ein kleines Team

Markenerwähnungen & Off-Site-Präsenz
Die stärkste Korrelation in den Daten ist gar nicht auf deiner Website. Sie ist überall sonst.
Weil ~60 % der ChatGPT-Antworten aus dem parametrischen Gedächtnis kommen, ist der stärkste Zitat-Hebel oft in deiner eigenen Analytik unsichtbar: wie oft und wie konsistent deine Marke im offenen Web erscheint. Die Synthese von The Digital Bloom fand, dass das Marken-Suchvolumen der Prädiktor #1 für LLM-Zitate ist, mit einer Korrelation von 0,334 — höher als jede Backlink-Metrik — und dass Sites, die auf 4+ Plattformen präsent sind, 2,8× wahrscheinlicher in ChatGPT-Antworten erscheinen.[9]
Die Evidenz auf Plattformebene ist genauso direkt. Wikipedia macht rund 22 % der Trainingsdaten großer LLM aus, weshalb eine Entität mit einer Wikipedia-Seite strukturell weit wahrscheinlicher erinnert wird als eine identische ohne. Eine Analyse von über 150.000 Zitaten vom Juni 2025 fand Reddit in 40,1 % der Fälle zitiert, über ChatGPT, Perplexity, Gemini und Claude hinweg.[9] Das sind die Orte, die die Modelle tatsächlich lesen.
Für eine kleine Site ist die umsetzbare Version eng und machbar:
- Sei konsistent. Gleicher Markenname, gleiche Ein-Zeilen-Beschreibung, gleiche Kategorie überall — deine Site, LinkedIn, Crunchbase, G2, dein Reddit-Profil. Inkonsistente Entitätsdaten schwächen die neuronale Repräsentation, die den Recall antreibt.
- Verdiene echte Drittquellen-Erwähnungen. Eine einzige redaktionelle Rezension im TechRadar-Stil oder ein echter Reddit-Thread über dich ist zitierfähiger als ein Dutzend Seiten auf deiner eigenen Domain.
- Tauche dort auf, wo die Engine deiner Branche zitiert. Für B2B ist das meist LinkedIn + Reddit; für Konsum/Lifestyle YouTube + Reddit. Echte, hilfreiche Teilnahme — keine Werbe-Drops.
- Strebe eine ehrliche Wikipedia-Präsenz an, wenn (und nur wenn) du die Relevanzkriterien erfüllst. Sie prägt den parametrischen Recall überproportional.
Schema & llms.txt: was 2026 real ist
Zwei der am meisten überverkauften 'KI-Zitat-Hacks'. Hier ist, was die Primärquellen tatsächlich sagen.
Strukturierte Daten zählen noch — aber als Vertrauens- und Parse-Signal, nicht als garantierter Zitat-Auslöser. Der Gemini-gestützte AI Mode behandelt Schema als Weg, deinen Content zu verstehen und ihm zu vertrauen, nicht als Anzeige-Hebel. Nutze JSON-LD und wende nur Schema an, das wirklich zur Seite passt. Der Haken 2026 ist, dass mehrere Schema-Typen still eingestellt wurden, sodass eine Strategie darauf vergeudete Mühe ist.
| Schema-Typ | Status 2026 | Was du wissen musst |
|---|---|---|
| Article / BlogPosting | Nutzen | Strukturelles Rückgrat. Googles Doku vom 10.12.2025 nennt KEINE Pflicht-Eigenschaften — halte es einfach und akkurat. Nutze JSON-LD. |
| Organization | Nutzen | Stärkt die Entitätsidentität und sameAs-Links — speist die Entitätsklarheit, die den Recall verbessert. |
| Product / LocalBusiness | Nutzen | Schema nur an die Seite anpassen. Der Gemini-gestützte AI Mode behandelt Schema als Vertrauenssignal, nicht als Anzeige-Auslöser. |
| FAQPage | Vorsicht | FAQ-Rich-Results wurden in der Google Suche zum 7. Mai 2026 eingestellt (nur gov/Gesundheit). Hilft einem Parser noch, Q&A-Struktur zu lesen — erwarte aber kein Rich Result. |
| HowTo | Veraltet | Rich Results für die meisten Sites in der Bereinigung 2025 entfernt. |
| ClaimReview / SpecialAnnouncement / VehicleListing + 4 weitere | Veraltet | Unter den 7 strukturierten Datentypen, die Google im Jun/Nov 2025 abkündigte. Baue keine Strategie darauf auf. |
Die Schlagzeilen-Änderung: laut Googles eigener FAQPage-Dokumentation erschienen FAQ-Rich-Results in der Google Suche ab dem 7. Mai 2026 nicht mehr und überleben nur für behörden- und gesundheitsfokussierte autoritative Sites.[6] HowTo-Rich-Results wurden für die meisten Sites in der Bereinigung 2025 entfernt, und Google kündigte zwischen Juni und November 2025 sieben strukturierte Datentypen ab.[12] FAQPage- und HowTo-Markup kann einem Parser noch helfen, deine Q&A-Struktur zu verstehen — erwarte aber kein Rich Result und behandle es nicht als Zitat-Garantie. (Für das JSON-LD, das du trotzdem ausliefern solltest, siehe unseren Leitfaden zu Schema-Markup für Kleinunternehmen.)
Gary Illyes (Google), Search Central Live, Juli 2025: Google unterstützt llms.txt NICHT und plant das auch nicht.
John Mueller verglich llms.txt öffentlich mit dem veralteten Meta-Keywords-Tag — seit über einem Jahrzehnt ignoriert.
Dezember 2025: Eine llms.txt-Datei tauchte kurz in Googles eigener Entwickler-Doku auf; auf Bluesky gefragt, ob das eine Befürwortung sei, antwortete Mueller 'um es direkt zu sagen, nein'. Das Search-Team entfernte sie.
Keine große Answer-Engine hat bestätigt, llms.txt für Ranking oder Zitate zu nutzen. Es ist ein vorgeschlagener Standard, den einige doku-lastige Sites veröffentlichen.
Ehrliches Fazit: geringe Kosten, wenig Belege. 'Schadet wahrscheinlich nicht', ist aber KEIN Zitat-Hebel. Verschwende keine echte Zeit darauf.
Verschwende keinen Sprint auf llms.txt
Die realistische Zitat-Checkliste
Alles oben, sequenziert in das, was eine Person ohne Budget tatsächlich ausliefern kann.
Die Forschung ist umfassend; deine Zeit nicht. Hier ist die Reihenfolge, in der Ein-Personen-Sites 2026 tatsächlich ausliefern, vorne beladen mit den Zügen mit dem größten Hebel und dem geringsten Aufwand.
| Phase | Zeit | Was du tust |
|---|---|---|
| 1. Struktur | Woche 1 | Schreibe deine 5 besten Einleitungen als 40–60-Wort-Direktantworten unter H2 mit der exakten Frage um. Hänge an jede Schlüsselaussage eine zugeschriebene Statistik. Zerlege lange Abschnitte in in sich geschlossene 200–500-Wort-Passagen. |
| 2. Schema | Woche 1 | Liefere Article- + Organization- + Author-JSON-LD sitewide aus. Halte es akkurat und an jede Seite angepasst. Überspring llms.txt. Baue nicht auf FAQPage/HowTo-Rich-Results. |
| 3. Fan-out-Abdeckung | Wochen 2–4 | Füge für jedes Prioritätsthema angrenzende Passagen hinzu, die die nächsten logischen Fragen beantworten. So gewinnst du die 14–52 % der Zitate, die die Top 10 umgehen. |
| 4. Originaldaten | Monat 2 | Veröffentliche ein First-Party-Forschungsstück — eine 200-Befragten-Umfrage, eine 50-Beispiel-Analyse, einen belegbaren Benchmark — mit einem Absatz Methodik. Werde zum Ursprung einer Zahl. |
| 5. Markenpräsenz | Monate 2–3 | Mache Entitätsdaten überall konsistent. Verdiene echte Drittquellen-Erwähnungen. Nimm echt an den 2 Plattformen teil, die die Engines deiner Branche am meisten zitieren (meist Reddit + LinkedIn oder YouTube). |
| 6. Kadenz | Laufend | Veröffentliche stetig. Frischer, konsistent strukturierter Content hält dich im rotierenden Quellenmix (40–60 % der zitierten Quellen wechseln monatlich). Schweigen kostet Zitate. |
Wo News Factory hineinpasst
Wer auch immer dein redaktionelles Schwungrad am Laufen hält — du, ein Freelancer oder ein KI-gestütztes System wie News Factory — die Strategie bleibt. Zitate gehen nicht an die lauteste Verkaufsseite. Sie gehen an die Quelle, die die exakte Frage beantwortet hat, mit einer zuschreibbaren Zahl, in einer Passage, die ein Abrufsystem für sich allein anheben könnte. Baue das, konsistent, an den Orten, die die Modelle tatsächlich lesen.
→ Mach das jetzt: Wähle drei Seiten. Schreibe jede Einleitung als 40–60-Wort-Direktantwort unter einem H2 mit der exakten Frage um, hänge an die zentrale Aussage jeder eine zugeschriebene Statistik und füge Article- + Author-Schema hinzu. Das ist die Arbeit für heute Abend — und sie bringt dich vor fast jede kleine Site, die noch nur für blaue Links optimiert.
Verwandte Lektüre
- AEO vs. SEO 2026: Warum Answer Engines die neue Suche sind — der strategische Rahmen, in dem dieser Leitfaden sitzt.
- AI Overviews & SGE: Wie kleine Seiten 2026 noch Klicks gewinnen — der Google-AIO-Schadensbericht und der Vergleichsanfragen-Carve-out.
- Schema-Markup für Kleinunternehmen — die JSON-LD-Blöcke, die in 30 Minuten auszuliefern sind.
- Topische Autorität: Warum mehr (gute) Inhalte zu veröffentlichen im SEO gewinnt — das Kadenz- und Fan-out-Abdeckungs-Problem im Detail.
Quellen & Referenzen
Zu den Top-10-Zahlen: Studien unterscheiden sich nach Methodik (gesamtes Zitat-Set vs. nur Zitate, die sich mit den Top 100 überschneiden; verschiedene Zeitfenster; AI Overviews ändern sich schnell). Die ehrliche Lesart ist eine Spanne (38–76 %) und eine Richtung, keine einzelne feste Zahl.