Come funziona davvero la citazione da IA
Prima di poter essere citato, devi capire i due modi completamente diversi in cui un motore di risposta può trovarti.
Essere citato da un motore di risposta AI significa essere la fonte che il modello cita, nomina o collega quando compone una risposta. Ma non c'è un solo percorso verso questo — ce ne sono due, e si comportano in modo così diverso che ottimizzare per uno ignorando l'altro è la ragione più comune per cui un buon contenuto non viene mai citato.
Il primo percorso è la conoscenza parametrica — ciò che il modello ha assorbito dai suoi dati di addestramento e ora ricorda a memoria. Il secondo è la conoscenza recuperata — ciò che estrae dal web in tempo reale al momento della risposta tramite Generazione Aumentata dal Recupero (RAG). La divisione conta enormemente: secondo la sintesi di dicembre 2025 di The Digital Bloom, circa il 60% delle query di ChatGPT viene risposto puramente dalla memoria parametrica senza attivare alcuna ricerca web, e una stima di un professionista colloca la ricerca web in tempo reale a solo il ~31% dei prompt.[9] Per la maggior parte delle risposte, ciò che ti fa menzionare è la tua impronta nei dati di addestramento — con quale frequenza e coerenza il tuo brand appare nel web aperto — non una mossa SEO in tempo reale.
Quando un motore davvero recupera, una pipeline multifase decide cosa raggiunge il modello:
- Codifica della query: la domanda dell'utente diventa un embedding vettoriale (es. text-embedding-3-large di OpenAI a 3.072 dimensioni).
- Recupero ibrido: la ricerca semantica densa (embedding) si fonde con il matching di keyword sparso (BM25) — una combinazione che porta circa un miglioramento del 48% rispetto a ciascun metodo da solo.[9]
- Reranking: modelli cross-encoder ripuntano i passaggi candidati per la query specifica (migliorando la qualità del ranking del ~28% su NDCG@10).
- Generazione: solo i 5–10 chunk recuperati principali vengono iniettati nel prompt come contesto. Tutto il resto è invisibile al modello per quella risposta.
Quel numero finale è tutto il gioco. Se la tua risposta è spalmata su un saggio lungo e fluido, nessun chunk è autosufficiente, e perdi il posto a favore di un concorrente il cui passaggio si regge da solo. Come ha detto Discovered Labs, i motori AI selezionano per rilevanza semantica, chiarezza dell'entità e validazione di terze parti — non per equity di link come faceva il SEO classico.
Due impronte, due strategie
Motori di risposta che questa guida copre
Il mito della top-10: i numeri onesti
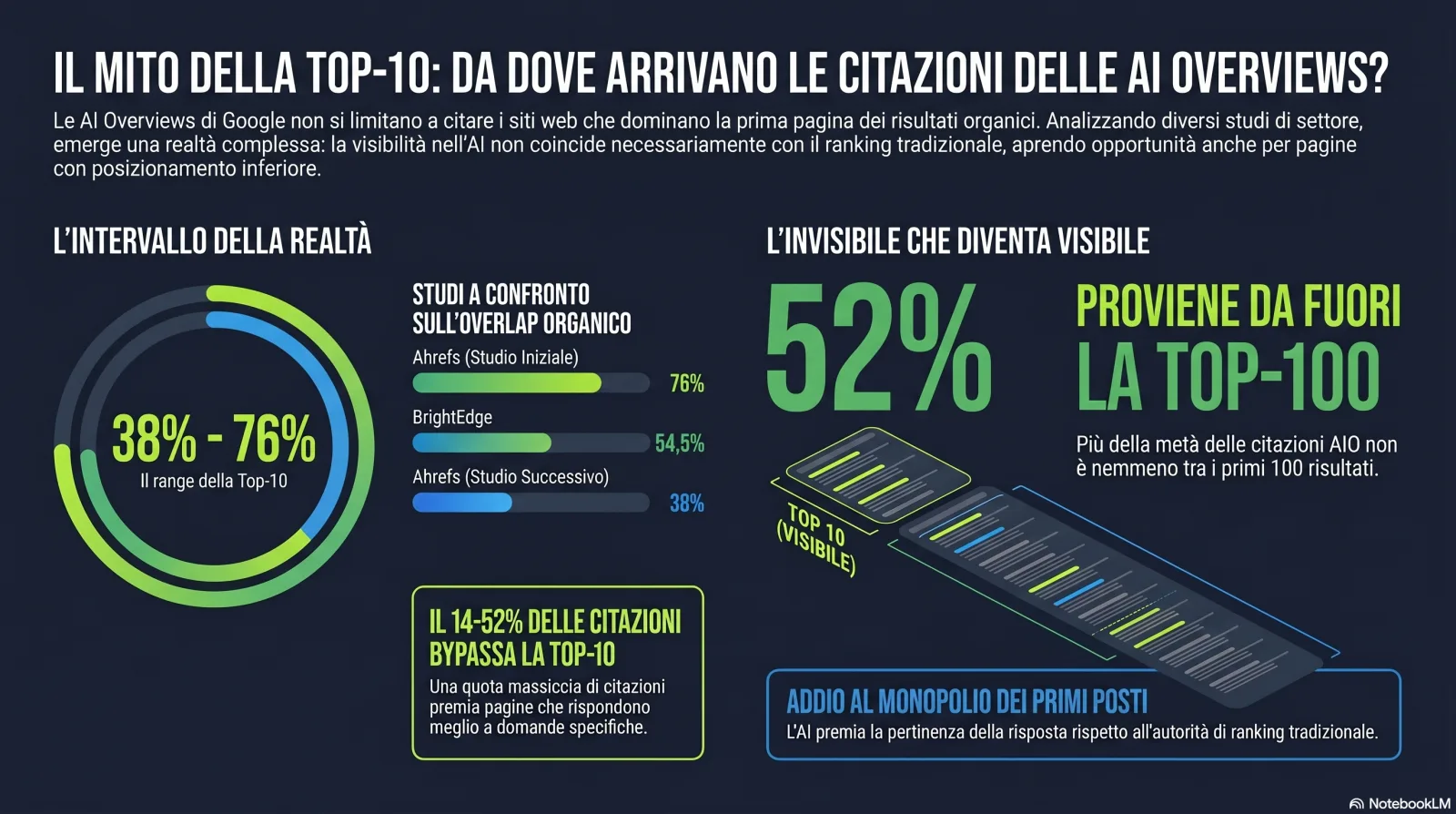
Hai visto 'il 76% delle citazioni AI viene dalla top 10'. Hai anche visto il 38%. Entrambi sono reali. Ecco perché.
La statistica più citata in questo spazio è una qualche versione di «la maggior parte delle citazioni AI viene da pagine che si posizionano già nella top 10 di Google». È vera, parzialmente vera e fuorviante allo stesso tempo — dipendendo interamente da quale studio leggi e da come hanno contato. Ecco l'intervallo onesto:
Quale quota delle citazioni dei motori AI viene dalla top-10 organica?
Cinque misurazioni credibili che divergono — perché hanno misurato cose diverse[2][3][4]
Questi numeri NON sono contraddittori. Il 76% di Ahrefs conta pagine citate che si posizionano top-10 sull'intero set di citazioni; il 52,5% di Originality.ai è la quota top-10 solo delle citazioni che si sovrappongono alla top-100; la lettura del 38% è arrivata dopo da un campione di keyword diverso, quando il fan-out ha tirato pagine più profonde. La conclusione onesta è un intervallo e una direzione — non un numero magico.
Lette insieme, tre cose sono chiaramente vere:
- Posizionarsi bene è un forte vento a favore. L'analisi di Ahrefs di 1,9M di citazioni su 1M di AI Overviews ha trovato che il 76,1% delle pagine citate si posiziona nella top 10, con un rank citato mediano di 3 e l'URL citato principale in una posizione mediana di 2.[2] Se puoi posizionarti, posizionati.
- Ma non è una garanzia. Persino che il risultato #1 venga citato è, nelle parole di Ahrefs, «un lancio di moneta nella migliore delle ipotesi». Originality.ai colloca la probabilità di citazione di un risultato top-1 attorno al 58%.[3]
- E una grande minoranza di citazioni evita del tutto la top-10. Originality.ai ha trovato che ~52% di tutte le citazioni delle AI Overviews viene da pagine fuori dalla top-100; Ahrefs ha trovato il 14,4% da pagine che non si posizionano affatto nella top-100.[2][3] Quel divario è l'apertura per tutti coloro che non riescono a superare nel ranking gli incumbent.
Conta anche la tendenza alla convergenza. Lo studio longitudinale di 16 mesi di BrightEdge ha trovato che la sovrapposizione tra AI Overviews e organico è salita dal 32,3% al lancio (maggio 2024) al 54,5% entro fine 2025, con i verticali YMYL che si sovrappongono di più — Salute al 75,3%, Istruzione al 72,6%.[4] Nelle categorie di fiducia e alto rischio, il ranking classico e la citazione AI stanno convergendo. In tutto il resto, la porta sul retro è più ampia.
La porta sul retro è strutturale, non accidentale
ChatGPT vs Perplexity vs Google AIO
I tre grandi motori recuperano e citano in modo diverso. Dove investi dipende da quale usano i tuoi acquirenti.
«Ottimizza per l'AI» è troppo grossolano per agire. Ogni motore ha una pipeline di recupero distinta e un insieme distinto di fonti su cui si appoggia. Ecco come differiscono i tre più grandi, e cosa significa ogni differenza per la tua prossima mossa.
| Motore | Come recupera | Cosa viene citato | La tua mossa |
|---|---|---|---|
| ChatGPT (Search) | Prima parametrico — solo ~31% dei prompt attivano una ricerca web live; il resto risponde dalla memoria dei dati di addestramento. Usa l'indice di Bing quando cerca. | Wikipedia domina le top fonti (47,9%), poi Reddit e Forbes. Brand menzionati di frequente nel web aperto al momento dell'addestramento. | Costruisci menzioni del brand ampie e coerenti nel web (per vivere nei dati di addestramento) E struttura le pagine per il recupero live. |
| Perplexity | RAG in tempo reale su ogni query. Pipeline a sei fasi: intento → recupero ibrido (BM25 + denso) → reranker a 3 livelli → assemblaggio del prompt con citazioni pre-incorporate → sintesi. Cita sempre. Indicizza oltre 200 miliardi di URL. | Reddit (46,7%), YouTube, Gartner. Fonti autorevoli, URL freschi, dati originali di prima mano. Fa emergere blog di nicchia con facilità. | Massima leva per i siti piccoli. Passaggi autonomi con statistiche + dati originali conquistano citazioni anche senza ranking in top-10. |
| Panoramiche AI di Google | Ancorato all'indice di Google tramite il modello di deep learning FastSearch / RankEmbed — addestrato su dati di clic + valutatori di qualità, privilegia il matching semantico e la velocità sui classici segnali di link. | Reddit (21%), YouTube, Quora, LinkedIn — il più diversificato dei tre. Sovrapposizione parziale con il ranking organico classico. | Posizionati bene (forte vento a favore) E rispondi alle sotto-domande del fan-out. Dal 14 al 52% delle citazioni viene da fuori la top-10, a seconda dello studio. |
Perplexity è il motore con la maggiore leva per un sito piccolo. Esegue RAG in tempo reale su ogni singola query, cita sempre, fa emergere 4–8 fonti per risposta e tira con facilità blog di nicchia e thread di Reddit accanto a Wikipedia. Se vuoi vedere il tuo lavoro sulle citazioni dare frutti il più velocemente possibile, punta prima a Perplexity — il suo design di prodotto è strutturalmente amico di fonti più piccole e ben strutturate.
Da dove ogni motore tira le sue principali citazioni
Lo studio di 680M di citazioni di Profound — il mix di fonti è radicalmente diverso per piattaforma[7]
ChatGPT si appoggia a Wikipedia (47,9% della sua quota di top fonte); Perplexity si appoggia a Reddit (46,7%); le Panoramiche AI di Google sono le più diversificate, distribuendosi su Reddit, YouTube, Quora e LinkedIn. Un'implicazione: un thread di Reddit o una forte entità Wikipedia su di te può valere più di un'altra pagina sul tuo dominio.
Non sovra-indicizzarti sul mix di fonti di una singola piattaforma
I 7 schemi di scrittura amici delle citazioni
Questa è la parte che controlli completamente. Sette mosse strutturali, ognuna con una ragione misurata o meccanicistica per cui conquista citazioni.
La fonte accademica fondante qui è lo studio GEO (Aggarwal et al., Princeton / Georgia Tech / IIT Delhi / Allen Institute, KDD 2024). Su un benchmark di query diverse, i metodi GEO hanno aumentato la visibilità della fonte nelle risposte generative fino al 40%, e le tre tattiche più performanti erano notevolmente noiose: aggiungi statistiche, aggiungi citazioni e cita le tue fonti.[1] Ecco i sette schemi che derivano da quel lavoro e dalle sue repliche nel settore, ordinati per difficoltà.
| Schema | Perché conquista citazioni | Difficoltà |
|---|---|---|
| Apri con la risposta (piramide rovesciata, 40–60 parole) | Il RAG inietta solo i 5–10 chunk recuperati principali. Una risposta diretta e autonoma mappa in modo pulito l'embedding della query e viene sollevata quasi alla lettera. | Facile |
| Allega una statistica a ogni affermazione, con attribuzione | L'"Aggiunta di Statistiche" del GEO ha alzato la visibilità del ~22%. "Secondo [fonte, data], X è Y%" dà al modello un atomo citabile e difendibile. | Facile |
| Aggiungi citazioni di esperti | L'"Aggiunta di Citazioni" del GEO è stata la singola tattica più forte — ~37% di aumento. Le citazioni dirette di autorità nominate si leggono come prove citabili. | Medio |
| Cita le tue fonti credibili | Controintuitivo ma misurato: "Citare le Fonti" del GEO ha alzato la visibilità PROPRIA della pagina citante del ~30%. Referenziare dati primari ti fa sembrare un hub. | Facile |
| Definisci le entità in modo esplicito, nominale in modo coerente | Frasi definitorie "X è un…" + denominazione coerente nel web rafforzano la rappresentazione neuronale dell'entità, migliorando il recall e il matching di recupero. | Medio |
| Spezza per il recupero — passaggi autonomi di 200–500 parole | Benchmark NVIDIA: il chunking a livello di pagina ha raggiunto 0,648 di accuratezza con la varianza minore. Ogni sezione deve rispondere a una query isolatamente — definisci, rispondi, sostieni, tutto in un passaggio. | Medio |
| Rispondi alla PROSSIMA domanda logica in passaggi adiacenti | I motori generano sotto-query di fan-out ed estraggono il chunk che risponde meglio a ciascuna. La copertura complementare conquista citazioni anche quando non sei in top-10 (Jim Yu, di BrightEdge). | Difficile |
Tattiche GEO per aumento di visibilità misurato
Dal paper GEO di KDD 2024 + la replica industriale di The Digital Bloom[1][9]
Il vincitore controintuitivo: citare le tue fonti credibili aumenta le tue probabilità di citazione. Il modello legge una pagina ben referenziata come un hub di fiducia. L'Aggiunta di Citazioni (~37%) è stata la singola tattica più forte nel benchmark GEO.
Le tre mosse da fare questa settimana
1. Riscrivi le introduzioni dei tuoi cinque articoli migliori come risposte dirette. Da quaranta a sessanta parole, usando la formulazione esatta della domanda come H2 direttamente sopra. Elimina ogni apertura del tipo «in questo articolo esploreremo…». Questo singolo blocco è ciò che ChatGPT, Perplexity e Google AIO sollevano più spesso, spesso alla lettera. Apri con la risposta; spiega dopo.
2. Allega una statistica attribuita a ogni affermazione importante. «Secondo [fonte, data], X è Y%.» Questo fa due cose insieme: soddisfa la tattica di Aggiunta di Statistiche del GEO e dà al modello un atomo autonomo e difendibile che può citare senza rischio. Le affermazioni vaghe («molti esperti credono») sono l'opposto — non citabili.
3. Spezza le sezioni lunghe in passaggi autonomi di 200–500 parole. I benchmark di recupero di NVIDIA hanno trovato che il chunking a livello di pagina ha raggiunto 0,648 di accuratezza con la varianza minore.[9] Ogni passaggio dovrebbe definire l'entità, rispondere a una domanda e portare la sua statistica di supporto — perché il modello può vedere quel passaggio in completo isolamento dal resto della tua pagina.
Dati originali: la leva più forte
Se sei l'origine di un numero, sei la citazione naturale per quel numero. Niente altro si compone così.
La singola tattica meglio supportata in tutta la letteratura è pubblicare dati originali e proprietari. Il meccanismo è semplice: quando esegui un sondaggio, pubblichi un benchmark o rilasci uno studio, diventi l'origine di una statistica. Ogni modello che vuole usare quel numero ha esattamente un posto a cui attribuirlo — te. Una statistica proprietaria è l'«atomo citabile» che i motori di risposta sollevano alla lettera, e a differenza di un paragrafo ben scritto, nessun concorrente può semplicemente riscriverlo meglio.
Qui è anche dove i dati sono più espliciti su ciò che non funziona. Lo studio di 17.551 citazioni di SolCrys sulla categoria delle guide all'acquisto AEO ha trovato che le pagine «.com» di proprietà dei vendor rappresentavano solo lo 0,85% di tutte le citazioni complessive — mentre Wikipedia, TechRadar e Reddit dominavano.[10] Persino SolCrys, l'editore stesso dello studio, è stato citato solo a un tasso di menzione di categoria del 4,82%.
Cosa prevede davvero una citazione AI (e cosa no)
La presenza del brand batte i backlink; la tua pagina di vendita registra a malapena[9][10]
Il volume di ricerca del brand correla con le citazioni LLM a 0,334 — più alto di qualsiasi metrica di link (The Digital Bloom). Intanto le pagine autopromozionali di proprietà del vendor sono lo 0,85% delle citazioni (SolCrys). La conclusione: una menzione editoriale di terze parti o un thread di Reddit su di te è molto più citabile della tua pagina «siamo i migliori».
La mossa dei dati originali per un piccolo team

Menzioni del brand e presenza off-site
La correlazione più forte nei dati non è affatto sul tuo sito. È ovunque tranne lì.
Poiché ~60% delle risposte di ChatGPT viene dalla memoria parametrica, la leva di citazione più forte è spesso invisibile nella tua stessa analitica: con quale frequenza, e con quale coerenza, il tuo brand appare nel web aperto. La sintesi di The Digital Bloom ha trovato che il volume di ricerca del brand è il predittore #1 di citazioni LLM con una correlazione di 0,334 — più alto di qualsiasi metrica di backlink — e che i siti presenti su 4+ piattaforme hanno 2,8× più probabilità di apparire nelle risposte di ChatGPT.[9]
L'evidenza a livello di piattaforma è altrettanto diretta. Wikipedia compone circa il 22% dei dati di addestramento dei grandi LLM, ragione per cui un'entità con una pagina Wikipedia è strutturalmente molto più probabile da ricordare di una identica senza. Un'analisi di giugno 2025 di oltre 150.000 citazioni ha trovato Reddit citato nel 40,1% dei casi su ChatGPT, Perplexity, Gemini e Claude.[9] Questi sono i luoghi che i modelli leggono davvero.
Per un sito piccolo, la versione azionabile è stretta e fattibile:
- Sii coerente. Stesso nome del brand, stessa descrizione di una riga, stessa categoria ovunque — il tuo sito, LinkedIn, Crunchbase, G2, il tuo profilo Reddit. Dati di entità incoerenti indeboliscono la rappresentazione neuronale che alimenta il recall.
- Conquista menzioni genuine di terze parti. Una singola recensione editoriale in stile TechRadar o un thread reale di Reddit su di te è più citabile di una dozzina di pagine sul tuo dominio.
- Compari dove cita il motore del tuo verticale. Per il B2B di solito è LinkedIn + Reddit; per consumo/lifestyle è YouTube + Reddit. Partecipazione reale e utile — non drop promozionali.
- Persegui una presenza onesta su Wikipedia se (e solo se) soddisfi le linee guida di rilevanza. Plasma in modo sproporzionato il recall parametrico.
Schema e llms.txt: cosa è reale nel 2026
Due dei 'trucchi per le citazioni AI' più sopravvalutati. Ecco cosa dicono davvero le fonti primarie.
I dati strutturati contano ancora — ma come segnale di fiducia e parsing, non come trigger garantito di citazioni. L'AI Mode potenziato da Gemini tratta lo schema come un modo per capire e fidarsi del tuo contenuto, non come una leva di visualizzazione. Usa JSON-LD, e applica solo schema che corrisponda genuinamente alla pagina. La trappola nel 2026 è che diversi tipi di schema sono stati ritirati in silenzio, quindi costruire una strategia su di essi è fatica sprecata.
| Tipo di schema | Stato 2026 | Cosa devi sapere |
|---|---|---|
| Article / BlogPosting | Usare | Spina dorsale strutturale. La doc di Google del 10-12-2025 indica che NON ci sono proprietà obbligatorie — tienilo semplice e accurato. Usa JSON-LD. |
| Organization | Usare | Rafforza l'identità dell'entità e i link sameAs — alimenta la chiarezza dell'entità che migliora il recall. |
| Product / LocalBusiness | Usare | Adatta lo schema solo alla pagina. L'AI Mode potenziato da Gemini tratta lo schema come segnale di fiducia, non come trigger di visualizzazione. |
| FAQPage | Cautela | I rich result FAQ sono stati ritirati da Google Search il 7 maggio 2026 (solo siti gov/salute). Aiuta ancora un parser a leggere la struttura Q&A — ma non aspettarti un rich result. |
| HowTo | Deprecato | Rich result rimossi per la maggior parte dei siti nella pulizia del 2025. |
| ClaimReview / SpecialAnnouncement / VehicleListing + altri 4 | Deprecato | Tra i 7 tipi di dati strutturati che Google ha deprecato a giu/nov 2025. Non costruire una strategia su questi. |
Il cambiamento principale: secondo la documentazione FAQPage di Google, i rich result FAQ hanno smesso di apparire nella Google Search dal 7 maggio 2026, sopravvivendo solo per siti autorevoli governativi e sanitari.[6] I rich result HowTo sono stati rimossi per la maggior parte dei siti nella pulizia del 2025, e Google ha deprecato sette tipi di dati strutturati tra giugno e novembre 2025.[12] Il markup FAQPage e HowTo può ancora aiutare un parser a capire la tua struttura Q&A — ma non aspettarti un rich result né trattarlo come garanzia di citazione. (Per il JSON-LD che dovresti comunque spedire, vedi la nostra guida allo schema markup per piccole imprese.)
Gary Illyes (Google), Search Central Live, luglio 2025: Google NON supporta llms.txt e non ha piani per farlo.
John Mueller ha paragonato pubblicamente llms.txt al deprecato tag meta keywords — ignorato da oltre un decennio.
Dicembre 2025: un file llms.txt è apparso brevemente nella doc per sviluppatori di Google; alla domanda su Bluesky se fosse un endorsement, Mueller ha risposto 'per essere diretto, no'. Il team di Search lo ha rimosso.
Nessun motore di risposta importante ha confermato di usare llms.txt per ranking o citazioni. È uno standard proposto che pochi siti ricchi di documentazione pubblicano.
Verdetto onesto: basso costo, poche prove. 'Probabilmente non fa male', ma NON è una leva per le citazioni. Non dedicarci tempo reale.
Non sprecare uno sprint su llms.txt
La checklist realistica delle citazioni
Tutto quanto sopra, sequenziato in ciò che una persona senza budget può davvero spedire.
La ricerca è esaustiva; il tuo tempo no. Ecco l'ordine in cui i siti di una sola persona stanno davvero spedendo nel 2026, caricato in avanti con le mosse a maggiore leva e minore sforzo.
| Fase | Tempo | Cosa stai facendo |
|---|---|---|
| 1. Struttura | Settimana 1 | Riscrivi le tue 5 migliori introduzioni come risposte dirette di 40–60 parole sotto H2 con la domanda esatta. Allega una statistica attribuita a ogni affermazione chiave. Spezza le sezioni lunghe in passaggi autonomi di 200–500 parole. |
| 2. Schema | Settimana 1 | Spedisci JSON-LD di Article + Organization + Author su tutto il sito. Tienilo accurato e adattato a ogni pagina. Salta llms.txt. Non costruire sui rich result FAQPage/HowTo. |
| 3. Copertura fan-out | Settimane 2–4 | Per ogni tema prioritario, aggiungi passaggi adiacenti che rispondano alle prossime domande logiche. È così che conquisti il 14–52% delle citazioni che evitano la top-10. |
| 4. Dati originali | Mese 2 | Pubblica un pezzo di ricerca di prima mano — un sondaggio di 200 rispondenti, un'analisi di 50 esempi, un benchmark difendibile — con un paragrafo di metodologia. Diventa l'origine di un numero. |
| 5. Presenza del brand | Mesi 2–3 | Rendi i dati di entità coerenti ovunque. Conquista menzioni genuine di terze parti. Partecipa davvero sulle 2 piattaforme che i motori del tuo verticale citano di più (di solito Reddit + LinkedIn o YouTube). |
| 6. Cadenza | Continuo | Pubblica in modo costante. Contenuto fresco e strutturato in modo coerente ti mantiene nel mix rotante di fonti (40–60% delle fonti citate cambia mese su mese). Il silenzio costa citazioni. |
Dove si inserisce News Factory
Chiunque tenga in moto il tuo volano editoriale — tu, un freelancer o un sistema assistito dall'AI come News Factory — la strategia regge. Le citazioni non vanno alla pagina di vendita più rumorosa. Vanno alla fonte che ha risposto alla domanda esatta, con un numero attribuibile, in un passaggio che un sistema di recupero potrebbe sollevare da solo. Costruisci quello, in modo coerente, nei luoghi che i modelli leggono davvero.
→ Fai questo ora: Scegli tre pagine. Riscrivi ogni introduzione come una risposta diretta di 40–60 parole sotto un H2 con la domanda esatta, allega una statistica attribuita all'affermazione centrale di ciascuna, e aggiungi schema di Article + Author. È il lavoro di stasera — e ti mette davanti a quasi ogni sito piccolo che ancora ottimizza solo per i link blu.
Letture correlate
- AEO vs SEO nel 2026: Perché i Motori di Risposta Sono la Nuova Ricerca — il quadro strategico in cui questa guida si inserisce.
- Panoramiche AI & SGE: Come i Piccoli Siti Possono Ancora Ottenere Clic nel 2026 — il rapporto danni di Google AIO e il carve-out delle query comparative.
- Schema Markup per Piccole Imprese — i blocchi JSON-LD da spedire in 30 minuti.
- Autorità Tematica: Perché Pubblicare Più Contenuti (Buoni) Vince nel SEO — il problema di cadenza e copertura fan-out in profondità.
Riferimenti e Fonti
Sui numeri della top-10: gli studi differiscono per metodologia (intero set di citazioni vs. solo citazioni che si sovrappongono alla top-100; finestre temporali diverse; le AI Overviews cambiano in fretta). La lettura onesta è un intervallo (38–76%) e una direzione, non un singolo numero assestato.