Comment fonctionne réellement la citation par IA
Avant de pouvoir être cité, il faut comprendre les deux façons complètement différentes dont un moteur de réponse peut vous trouver.
Être cité par un moteur de réponse IA signifie être la source que le modèle cite, nomme ou lie lorsqu'il compose une réponse. Mais il n'y a pas un seul chemin vers cela — il y en a deux, et ils se comportent si différemment qu'optimiser pour l'un en ignorant l'autre est la raison la plus courante pour laquelle un bon contenu n'est jamais cité.
Le premier chemin est la connaissance paramétrique — ce que le modèle a absorbé de ses données d'entraînement et rappelle désormais de mémoire. Le second est la connaissance récupérée — ce qu'il tire en direct du web au moment de répondre via la Génération Augmentée par Récupération (RAG). La distinction compte énormément : selon la synthèse de décembre 2025 de The Digital Bloom, environ 60% des requêtes ChatGPT sont répondues purement depuis la mémoire paramétrique sans déclencher de recherche web, et une estimation de praticien situe la recherche web en direct à seulement ~31% des prompts.[9] Pour la majorité des réponses, ce qui vous fait mentionner est votre empreinte dans les données d'entraînement — la fréquence et la cohérence avec lesquelles votre marque apparaît sur le web ouvert — et non un quelconque mouvement SEO en direct.
Quand un moteur récupère bel et bien, une pipeline multi-étapes décide ce qui atteint le modèle :
- Encodage de la requête : la question de l'utilisateur devient un embedding vectoriel (p. ex. text-embedding-3-large d'OpenAI à 3 072 dimensions).
- Récupération hybride : la recherche sémantique dense (embeddings) est fusionnée avec l'appariement de mots-clés clairsemé (BM25) — une combinaison qui apporte environ une amélioration de 48% par rapport à chaque méthode seule.[9]
- Reranking : des modèles cross-encoder re-notent les passages candidats pour la requête précise (améliorant la qualité du classement de ~28% sur NDCG@10).
- Génération : seuls les 5–10 fragments récupérés en tête sont injectés dans le prompt comme contexte. Tout le reste est invisible pour le modèle dans cette réponse.
Ce dernier chiffre est tout l'enjeu. Si votre réponse est étalée sur un long essai fluide, aucun fragment n'est autosuffisant, et vous perdez la place au profit d'un concurrent dont le passage tient debout seul. Comme l'a dit Discovered Labs, les moteurs IA sélectionnent sur la pertinence sémantique, la clarté d'entité et la validation par des tiers — pas sur l'équité de liens comme le faisait le SEO classique.
Deux empreintes, deux stratégies
Moteurs de réponse couverts par ce guide
Le mythe du top-10 : les chiffres honnêtes
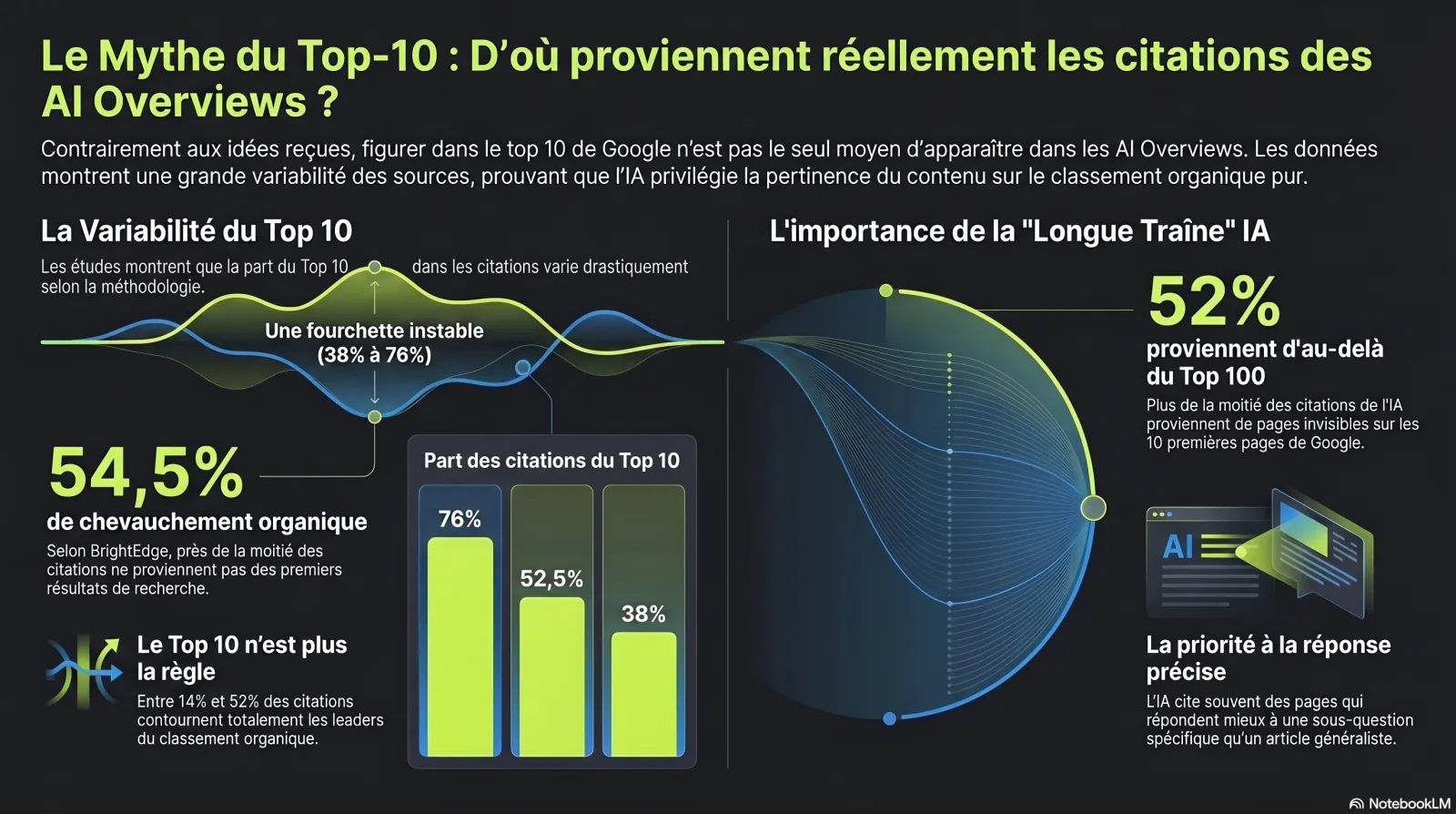
Vous avez vu '76% des citations IA viennent du top 10'. Vous avez aussi vu 38%. Les deux sont réels. Voici pourquoi.
La statistique la plus citée dans ce domaine est une version de « la plupart des citations IA viennent de pages déjà classées dans le top 10 de Google ». Elle est vraie, partiellement vraie et trompeuse à la fois — dépendant entièrement de l'étude que vous lisez et de la façon dont ils ont compté. Voici la fourchette honnête :
Quelle part des citations des moteurs IA vient du top-10 organique ?
Cinq mesures crédibles qui divergent — parce qu'elles ont mesuré des choses différentes[2][3][4]
Ces chiffres ne sont PAS contradictoires. Les 76% d'Ahrefs comptent les pages citées classées top-10 sur tout son ensemble de citations ; les 52,5% d'Originality.ai sont la part top-10 uniquement des citations qui chevauchent le top-100 ; la lecture de 38% est venue plus tard d'un échantillon de mots-clés différent, le fan-out tirant des pages plus profondes. La conclusion honnête est une fourchette et une direction — pas un chiffre magique.
Lues ensemble, trois choses sont clairement vraies :
- Bien se classer est un fort vent arrière. L'analyse d'Ahrefs de 1,9M de citations sur 1M d'AI Overviews a trouvé que 76,1% des pages citées se classent dans le top 10, avec un rang cité médian de 3 et l'URL citée principale à une position médiane de 2.[2] Si vous pouvez vous classer, classez-vous.
- Mais ce n'est pas une garantie. Même que le résultat #1 soit cité est, selon Ahrefs, « un pile ou face au mieux ». Originality.ai situe la probabilité de citation d'un résultat top-1 autour de 58%.[3]
- Et une large minorité de citations contourne entièrement le top-10. Originality.ai a trouvé que ~52% de toutes les citations d'AI Overviews viennent de pages hors du top-100 ; Ahrefs a trouvé 14,4% de pages ne se classant pas du tout top-100.[2][3] Cet écart est l'ouverture pour tous ceux qui ne peuvent pas surclasser les acteurs en place.
La tendance de convergence compte aussi. L'étude longitudinale de 16 mois de BrightEdge a trouvé que le chevauchement AI Overviews/organique est passé de 32,3% au lancement (mai 2024) à 54,5% fin 2025, les verticales YMYL chevauchant le plus — Santé à 75,3%, Éducation à 72,6%.[4] Dans les catégories de confiance à enjeux élevés, le classement classique et la citation IA convergent. Dans tout le reste, la porte dérobée est plus large.
La porte dérobée est structurelle, pas accidentelle
ChatGPT vs Perplexity vs Google AIO
Les trois grands moteurs récupèrent et citent différemment. Où investir dépend de celui qu'utilisent vos acheteurs.
« Optimiser pour l'IA » est trop grossier pour agir. Chaque moteur a une pipeline de récupération distincte et un ensemble distinct de sources sur lesquelles il s'appuie. Voici comment les trois plus grands diffèrent, et ce que chaque différence signifie pour votre prochain mouvement.
| Moteur | Comment il récupère | Ce qui est cité | Votre mouvement |
|---|---|---|---|
| ChatGPT (Search) | Paramétrique d'abord — seuls ~31% des prompts déclenchent une recherche web en direct ; sinon il répond depuis la mémoire des données d'entraînement. Utilise l'index de Bing lorsqu'il cherche. | Wikipedia domine les top sources (47,9%), puis Reddit et Forbes. Marques fréquemment mentionnées sur le web ouvert au moment de l'entraînement. | Construisez des mentions de marque larges et cohérentes sur le web (pour vivre dans les données d'entraînement) ET structurez les pages pour la récupération en direct. |
| Perplexity | RAG en temps réel à chaque requête. Pipeline en six étapes : intention → récupération hybride (BM25 + dense) → reranker à 3 niveaux → assemblage du prompt avec citations pré-intégrées → synthèse. Cite toujours. Indexe plus de 200 milliards d'URL. | Reddit (46,7%), YouTube, Gartner. Sources autoritatives, URL fraîches, données originales de première main. Fait remonter facilement les blogs de niche. | Le plus fort levier pour les petits sites. Des passages autonomes porteurs de statistiques + des données originales gagnent des citations même sans classement top-10. |
| Aperçus IA de Google | Ancré dans l'index de Google via le modèle de deep learning FastSearch / RankEmbed — entraîné sur les données de clic + évaluateurs de qualité, privilégie l'appariement sémantique et la vitesse sur les signaux de liens classiques. | Reddit (21%), YouTube, Quora, LinkedIn — le plus diversifié des trois. Chevauchement partiel avec le classement organique classique. | Classez-vous bien (fort vent arrière) ET répondez aux sous-questions du fan-out. Entre 14 et 52% des citations viennent de l'extérieur du top-10, selon l'étude. |
Perplexity est le moteur à plus fort levier pour un petit site. Il exécute du RAG en temps réel à chaque requête, cite toujours, fait remonter 4–8 sources par réponse et tire facilement les blogs de niche et les fils Reddit aux côtés de Wikipedia. Si vous voulez voir votre travail de citation porter ses fruits le plus vite, visez Perplexity en premier — son design produit est structurellement favorable aux sources plus petites et bien structurées.
D'où chaque moteur tire ses principales citations
L'étude de 680M de citations de Profound — le mix de sources est radicalement différent par plateforme[7]
ChatGPT s'appuie sur Wikipedia (47,9% de sa part de top source) ; Perplexity s'appuie sur Reddit (46,7%) ; les Aperçus IA de Google sont les plus diversifiés, répartis sur Reddit, YouTube, Quora et LinkedIn. Une implication : un fil Reddit ou une entité Wikipedia forte à votre sujet peut valoir plus qu'une autre page sur votre propre domaine.
Ne vous sur-indexez pas sur le mix de sources d'une seule plateforme
Les 7 modèles d'écriture favorables aux citations
C'est la partie que vous contrôlez entièrement. Sept mouvements structurels, chacun avec une raison mesurée ou mécanistique pour laquelle il gagne des citations.
La source académique fondatrice ici est l'étude GEO (Aggarwal et al., Princeton / Georgia Tech / IIT Delhi / Allen Institute, KDD 2024). Sur un benchmark de requêtes diverses, les méthodes GEO ont boosté la visibilité de source dans les réponses génératives jusqu'à 40%, et les trois tactiques les plus performantes étaient remarquablement banales : ajouter des statistiques, ajouter des citations et citer vos propres sources.[1] Voici les sept modèles qui découlent de ce travail et de ses réplications industrielles, triés par difficulté.
| Modèle | Pourquoi il gagne des citations | Difficulté |
|---|---|---|
| Commencez par la réponse (pyramide inversée, 40–60 mots) | Le RAG n'injecte que les 5–10 fragments récupérés en tête. Une réponse directe et autonome s'aligne nettement sur l'embedding de la requête et est reprise quasi mot pour mot. | Facile |
| Rattachez une statistique à chaque affirmation, avec attribution | L'« Ajout de Statistiques » de GEO a augmenté la visibilité de ~22%. « Selon [source, date], X est Y% » donne au modèle un atome citable et défendable. | Facile |
| Ajoutez des citations d'experts | L'« Ajout de Citations » de GEO a été la tactique individuelle la plus forte — ~37% de gain. Les citations directes d'autorités nommées se lisent comme des preuves citables. | Moyenne |
| Citez vos propres sources crédibles | Contre-intuitif mais mesuré : « Citer les Sources » de GEO a augmenté la visibilité PROPRE de la page citante de ~30%. Référencer des données primaires vous fait passer pour un hub. | Facile |
| Définissez les entités explicitement, nommez-les de façon cohérente | Les phrases définitoires « X est un… » + une dénomination cohérente sur le web renforcent la représentation neuronale de l'entité, améliorant le rappel et l'appariement de récupération. | Moyenne |
| Fragmentez pour la récupération — passages autonomes de 200–500 mots | Benchmarks NVIDIA : la fragmentation au niveau de la page a atteint 0,648 de précision avec la plus faible variance. Chaque section doit répondre à une requête de façon isolée — définir, répondre, étayer, le tout dans un passage. | Moyenne |
| Répondez à la PROCHAINE question logique dans des passages adjacents | Les moteurs génèrent des sous-requêtes de fan-out et tirent le fragment qui répond le mieux à chacune. Une couverture complémentaire gagne des citations même hors top-10 (Jim Yu de BrightEdge). | Difficile |
Tactiques GEO par gain de visibilité mesuré
Du paper GEO de KDD 2024 + la réplication industrielle de The Digital Bloom[1][9]
Le gagnant contre-intuitif : citer vos propres sources crédibles augmente vos chances de citation. Le modèle lit une page bien référencée comme un hub de confiance. L'Ajout de Citations (~37%) a été la tactique individuelle la plus forte du benchmark GEO.
Les trois mouvements à faire cette semaine
1. Réécrivez les introductions de vos cinq meilleurs articles en réponses directes. De quarante à soixante mots, en utilisant la formulation exacte de la question comme H2 juste au-dessus. Supprimez chaque ouverture du type « dans cet article, nous explorerons… ». Ce bloc unique est ce que ChatGPT, Perplexity et Google AIO extraient le plus souvent, fréquemment mot pour mot. Commencez par la réponse ; expliquez ensuite.
2. Rattachez une statistique attribuée à chaque affirmation importante. « Selon [source, date], X est Y%. » Cela fait deux choses à la fois : ça satisfait la tactique d'Ajout de Statistiques de GEO, et ça donne au modèle un atome autonome et défendable qu'il peut citer sans risque. Les affirmations vagues (« beaucoup d'experts pensent ») sont l'inverse — incitables.
3. Découpez les longues sections en passages autonomes de 200–500 mots. Les benchmarks de récupération de NVIDIA ont trouvé que la fragmentation au niveau de la page atteignait 0,648 de précision avec la plus faible variance.[9] Chaque passage doit définir l'entité, répondre à une question et porter sa statistique d'appui — car le modèle peut voir ce passage en isolation complète du reste de votre page.
Données originales : le levier le plus fort
Si vous êtes l'origine d'un chiffre, vous êtes la citation naturelle pour ce chiffre. Rien d'autre ne compose comme ça.
La tactique individuelle la mieux étayée de toute la littérature est de publier des données originales et propriétaires. Le mécanisme est simple : quand vous menez une enquête, publiez un benchmark ou sortez une étude, vous devenez l'origine d'une statistique. Chaque modèle voulant utiliser ce chiffre a exactement un endroit où l'attribuer — vous. Une statistique propriétaire est l'« atome citable » que les moteurs de réponse extraient mot pour mot, et contrairement à un paragraphe bien écrit, aucun concurrent ne peut simplement le réécrire en mieux.
C'est aussi là que les données sont les plus tranchées sur ce qui ne marche pas. L'étude de 17 551 citations de SolCrys sur la catégorie des guides d'achat AEO a trouvé que les pages « .com » propres des vendeurs ne représentaient que 0,85% de toutes les citations combinées — tandis que Wikipedia, TechRadar et Reddit dominaient.[10] Même SolCrys, l'éditeur de l'étude lui-même, n'a été cité qu'à un taux de mention de catégorie de 4,82%.
Ce qui prédit réellement une citation IA (et ce qui ne le fait pas)
La présence de marque bat les backlinks ; votre propre page de vente enregistre à peine[9][10]
Le volume de recherche de marque corrèle avec les citations LLM à 0,334 — plus haut que toute métrique de liens (The Digital Bloom). Pendant ce temps, les pages autopromotionnelles propres des vendeurs sont 0,85% des citations (SolCrys). La conclusion : une mention éditoriale tierce ou un fil Reddit à votre sujet est bien plus citable que votre propre page « nous sommes les meilleurs ».
Le coup des données originales pour une petite équipe

Mentions de marque et présence off-site
La corrélation la plus forte dans les données n'est pas du tout sur votre site web. Elle est partout ailleurs.
Comme ~60% des réponses de ChatGPT viennent de la mémoire paramétrique, le levier de citation le plus fort est souvent invisible dans votre propre analytique : la fréquence et la cohérence avec lesquelles votre marque apparaît sur le web ouvert. La synthèse de The Digital Bloom a trouvé que le volume de recherche de marque est le prédicteur #1 des citations LLM avec une corrélation de 0,334 — plus haut que toute métrique de backlinks — et que les sites présents sur 4+ plateformes ont 2,8× plus de chances d'apparaître dans les réponses de ChatGPT.[9]
La preuve au niveau des plateformes est tout aussi directe. Wikipedia constitue environ 22% des données d'entraînement des grands LLM, raison pour laquelle une entité avec une page Wikipedia est structurellement bien plus susceptible d'être rappelée qu'une identique sans. Une analyse de juin 2025 de plus de 150 000 citations a trouvé Reddit cité dans 40,1% des cas sur ChatGPT, Perplexity, Gemini et Claude.[9] Ce sont les endroits que les modèles lisent réellement.
Pour un petit site, la version actionnable est étroite et faisable :
- Soyez cohérent. Même nom de marque, même description d'une ligne, même catégorie partout — votre site, LinkedIn, Crunchbase, G2, votre profil Reddit. Des données d'entité incohérentes affaiblissent la représentation neuronale qui pilote le rappel.
- Gagnez de véritables mentions tierces. Une seule critique éditoriale de style TechRadar ou un vrai fil Reddit à votre sujet est plus citable qu'une douzaine de pages sur votre propre domaine.
- Apparaissez là où cite le moteur de votre verticale. Pour le B2B, c'est généralement LinkedIn + Reddit ; pour le grand public/lifestyle, c'est YouTube + Reddit. Participation réelle et utile — pas de dépôts promotionnels.
- Poursuivez une présence Wikipedia honnêtement si (et seulement si) vous remplissez les critères de notoriété. Elle façonne de manière disproportionnée le rappel paramétrique.
Schema et llms.txt : ce qui est réel en 2026
Deux des 'hacks de citation IA' les plus survendus. Voici ce que les sources primaires disent réellement.
Les données structurées comptent encore — mais comme signal de confiance et de parsing, pas comme déclencheur de citation garanti. L'AI Mode propulsé par Gemini traite le schema comme un moyen de comprendre et faire confiance à votre contenu, pas comme un levier d'affichage. Utilisez JSON-LD, et n'appliquez que le schema qui correspond réellement à la page. Le piège en 2026 est que plusieurs types de schema ont été discrètement retirés, donc bâtir une stratégie dessus est un effort gaspillé.
| Type de schema | Statut 2026 | Ce qu'il faut savoir |
|---|---|---|
| Article / BlogPosting | À utiliser | Colonne vertébrale structurelle. La doc de Google du 10/12/2025 indique AUCUNE propriété obligatoire — gardez-le simple et exact. Utilisez JSON-LD. |
| Organization | À utiliser | Renforce l'identité de l'entité et les liens sameAs — alimente la clarté d'entité qui améliore le rappel. |
| Product / LocalBusiness | À utiliser | N'adaptez le schema qu'à la page. L'AI Mode propulsé par Gemini traite le schema comme un signal de confiance, pas comme un déclencheur d'affichage. |
| FAQPage | Prudence | Les rich results FAQ ont été retirés de Google Search le 7 mai 2026 (sites gov/santé uniquement). Aide encore un parser à lire la structure Q&R — mais n'attendez pas de rich result. |
| HowTo | Obsolète | Rich results supprimés pour la plupart des sites lors du nettoyage de 2025. |
| ClaimReview / SpecialAnnouncement / VehicleListing + 4 autres | Obsolète | Parmi les 7 types de données structurées rendus obsolètes par Google en juin/nov 2025. Ne bâtissez pas de stratégie dessus. |
Le changement marquant : selon la propre documentation FAQPage de Google, les rich results FAQ ont cessé d'apparaître dans Google Search le 7 mai 2026, ne survivant que pour les sites autoritatifs gouvernementaux et de santé.[6] Les rich results HowTo ont été supprimés pour la plupart des sites lors du nettoyage de 2025, et Google a rendu obsolètes sept types de données structurées entre juin et novembre 2025.[12] Le balisage FAQPage et HowTo peut encore aider un parser à comprendre votre structure Q&R — mais n'attendez pas de rich result et ne le traitez pas comme une garantie de citation. (Pour le JSON-LD que vous devriez encore expédier, voyez notre guide de schema markup pour petites entreprises.)
Gary Illyes (Google), Search Central Live, juillet 2025 : Google ne prend PAS en charge llms.txt et n'a aucun projet en ce sens.
John Mueller a publiquement comparé llms.txt à la balise meta keywords obsolète — ignorée depuis plus d'une décennie.
Décembre 2025 : un fichier llms.txt est brièvement apparu dans la propre doc développeurs de Google ; interrogé sur Bluesky pour savoir si c'était un soutien, Mueller a répondu « pour être direct, non ». L'équipe Search l'a retiré.
Aucun grand moteur de réponse n'a confirmé utiliser llms.txt pour le classement ou les citations. C'est une norme proposée que publient quelques sites riches en documentation.
Verdict honnête : faible coût, faible preuve. « Ça ne nuit probablement pas », mais ce n'est PAS un levier de citation. N'y consacrez pas de temps réel.
Ne gaspillez pas un sprint sur llms.txt
La checklist réaliste des citations
Tout ce qui précède, séquencé en ce qu'une personne sans budget peut réellement expédier.
La recherche est exhaustive ; votre temps ne l'est pas. Voici l'ordre dans lequel les sites d'une seule personne expédient réellement en 2026, chargé en tête avec les mouvements à plus fort levier et moindre effort.
| Phase | Temps | Ce que vous faites |
|---|---|---|
| 1. Structure | Semaine 1 | Réécrivez vos 5 meilleures introductions en réponses directes de 40–60 mots sous des H2 reprenant la question exacte. Rattachez une statistique attribuée à chaque affirmation clé. Découpez les longues sections en passages autonomes de 200–500 mots. |
| 2. Schema | Semaine 1 | Expédiez du JSON-LD Article + Organization + Author sur tout le site. Gardez-le exact et adapté à chaque page. Sautez llms.txt. Ne bâtissez pas sur les rich results FAQPage/HowTo. |
| 3. Couverture de fan-out | Semaines 2–4 | Pour chaque sujet prioritaire, ajoutez des passages adjacents répondant aux prochaines questions logiques. C'est ainsi que vous gagnez les 14–52% de citations qui contournent le top-10. |
| 4. Données originales | Mois 2 | Publiez une pièce de recherche de première main — un sondage de 200 répondants, un décorticage de 50 exemples, un benchmark défendable — avec un paragraphe de méthodologie. Devenez l'origine d'un chiffre. |
| 5. Présence de marque | Mois 2–3 | Rendez les données d'entité cohérentes partout. Gagnez de véritables mentions tierces. Participez pour de vrai sur les 2 plateformes que les moteurs de votre verticale citent le plus (généralement Reddit + LinkedIn ou YouTube). |
| 6. Cadence | En continu | Publiez régulièrement. Un contenu frais et structuré de façon cohérente vous maintient dans le mix tournant de sources (40–60% des sources citées changent d'un mois à l'autre). Le silence coûte des citations. |
Où s'inscrit News Factory
Quel que soit celui qui fait tourner votre volant éditorial — vous, un freelance ou un système assisté par IA comme News Factory — la stratégie tient. Les citations ne vont pas à la page de vente la plus bruyante. Elles vont à la source qui a répondu à la question exacte, avec un chiffre attribuable, dans un passage qu'un système de récupération pourrait extraire de lui-même. Construisez cela, de façon cohérente, dans les endroits que les modèles lisent réellement.
→ Faites ceci maintenant : Choisissez trois pages. Réécrivez chaque introduction en réponse directe de 40–60 mots sous un H2 reprenant la question exacte, rattachez une statistique attribuée à l'affirmation centrale de chacune, et ajoutez du schema Article + Author. C'est le travail de ce soir — et ça vous place devant presque tous les petits sites qui optimisent encore uniquement pour les liens bleus.
Lecture connexe
- AEO vs SEO en 2026 : Pourquoi les Moteurs de Réponse Sont la Nouvelle Recherche — le cadre stratégique dans lequel s'inscrit ce guide.
- Aperçus IA et SGE : Comment les Petits Sites Peuvent Encore Gagner des Clics en 2026 — le bilan des dégâts de Google AIO et le carve-out des requêtes comparatives.
- Schema Markup pour Petites Entreprises — les blocs JSON-LD à expédier en 30 minutes.
- Autorité Thématique : Pourquoi Publier Plus de (Bon) Contenu Gagne en SEO — le problème de cadence et de couverture de fan-out en profondeur.
Références et Sources
Sur les chiffres du top-10 : les études diffèrent par méthodologie (ensemble complet de citations vs. seulement les citations chevauchant le top-100 ; fenêtres de dates différentes ; les AI Overviews changent vite). La lecture honnête est une fourchette (38–76%) et une direction, pas un chiffre unique et figé.