Cómo funciona realmente la cita por IA
Antes de poder ser citado, tienes que entender las dos formas completamente distintas en que un motor de respuesta puede encontrarte.
Ser citado por un motor de respuesta de IA significa ser la fuente que el modelo cita, nombra o enlaza al componer una respuesta. Pero no hay un solo camino hacia eso — hay dos, y se comportan de forma tan distinta que optimizar para uno ignorando el otro es la razón más común por la que el buen contenido nunca se cita.
El primer camino es el conocimiento paramétrico — lo que el modelo absorbió de sus datos de entrenamiento y ahora recuerda de memoria. El segundo es el conocimiento recuperado — lo que extrae en vivo de la web en el momento de responder vía Generación Aumentada por Recuperación (RAG). La división importa enormemente: según la síntesis de diciembre de 2025 de The Digital Bloom, aproximadamente el 60% de las consultas de ChatGPT se responden puramente desde la memoria paramétrica sin activar ninguna búsqueda web, y una estimación de un profesional sitúa la búsqueda web en vivo en solo el ~31% de los prompts.[9] Para la mayoría de las respuestas, lo que te hace mencionado es tu huella en los datos de entrenamiento — con qué frecuencia y consistencia aparece tu marca por toda la web abierta — no ningún movimiento de SEO en vivo.
Cuando un motor sí recupera, una pipeline multi-etapa decide qué llega al modelo:
- Codificación de la consulta: la pregunta del usuario se convierte en un embedding vectorial (p. ej., text-embedding-3-large de OpenAI con 3.072 dimensiones).
- Recuperación híbrida: la búsqueda semántica densa (embeddings) se fusiona con el matching de keywords disperso (BM25) — una combinación que aporta aproximadamente una mejora del 48% sobre cualquiera de los métodos por separado.[9]
- Reranking: modelos cross-encoder re-puntúan los pasajes candidatos para la consulta concreta (mejorando la calidad del ranking ~28% en NDCG@10).
- Generación: solo los 5–10 fragmentos recuperados principales se inyectan en el prompt como contexto. Todo lo demás es invisible para el modelo en esa respuesta.
Esa cifra final es todo el juego. Si tu respuesta está esparcida por un ensayo largo y fluido, ningún fragmento es autosuficiente, y pierdes el hueco frente a un competidor cuyo pasaje se sostiene solo. Como dijo Discovered Labs, los motores de IA seleccionan por relevancia semántica, claridad de entidad y validación de terceros — no por equity de enlaces como hacía el SEO clásico.
Dos huellas, dos estrategias
Motores de respuesta que cubre esta guía
El mito del top-10: las cifras honestas
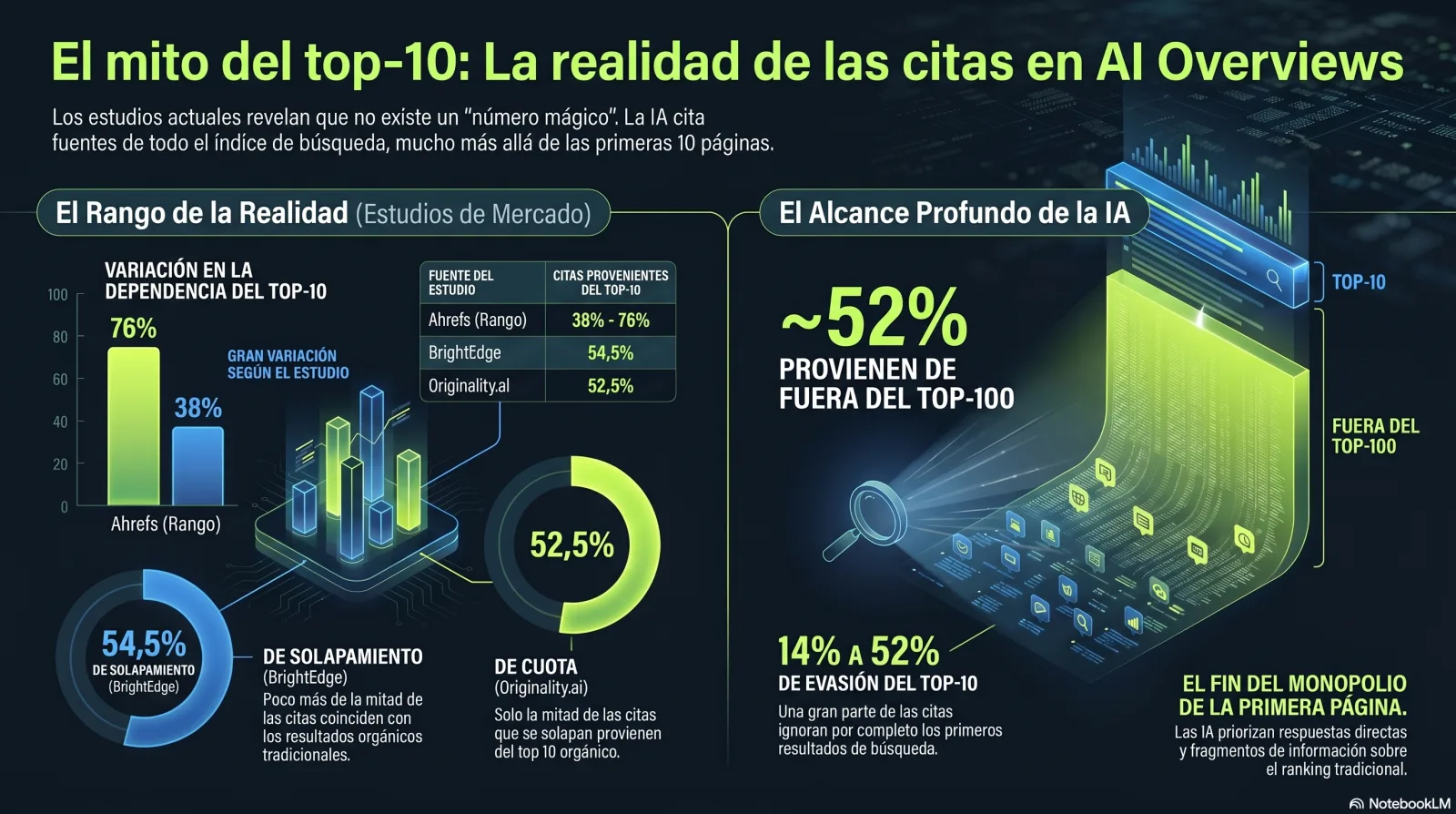
Has visto 'el 76% de las citas de IA vienen del top 10'. También has visto el 38%. Ambas son reales. Aquí está el porqué.
La estadística más citada en este espacio es alguna versión de «la mayoría de las citas de IA vienen de páginas que ya posicionan en el top 10 de Google». Es cierta, parcialmente cierta y engañosa a la vez — dependiendo enteramente de qué estudio leas y cómo contaron. Aquí está el rango honesto:
¿Qué cuota de las citas de motores de IA viene del top-10 orgánico?
Cinco mediciones creíbles que discrepan — porque midieron cosas distintas[2][3][4]
Estas cifras NO son contradictorias. El 76% de Ahrefs cuenta páginas citadas que posicionan top-10 en todo su conjunto de citas; el 52,5% de Originality.ai es la cuota top-10 solo de las citas que se solapan con el top-100; la lectura del 38% vino después de una muestra de keywords distinta al extraer el fan-out páginas más profundas. La conclusión honesta es un rango y una dirección — no una cifra mágica.
Leídas en conjunto, tres cosas son claramente ciertas:
- Posicionarse bien es un fuerte viento a favor. El análisis de Ahrefs de 1,9M de citas en 1M de AI Overviews encontró que el 76,1% de las páginas citadas posiciona en el top 10, con un rank citado mediano de 3 y la URL citada principal en una posición mediana de 2.[2] Si puedes posicionar, posiciona.
- Pero no es garantía. Incluso que el resultado #1 sea citado es, en palabras de Ahrefs, «una moneda al aire en el mejor de los casos». Originality.ai sitúa la probabilidad de cita de un resultado top-1 en torno al 58%.[3]
- Y una gran minoría de citas evita el top-10 por completo. Originality.ai encontró que ~52% de todas las citas de AI Overviews vienen de páginas fuera del top-100; Ahrefs encontró un 14,4% de páginas que no posicionan top-100 en absoluto.[2][3] Esa brecha es la apertura para todos los que no pueden superar en ranking a los incumbentes.
La tendencia de convergencia también importa. El estudio longitudinal de 16 meses de BrightEdge encontró que el solapamiento de AI Overviews con el orgánico subió del 32,3% en el lanzamiento (mayo 2024) al 54,5% para finales de 2025, con los verticales YMYL solapando más — Salud al 75,3%, Educación al 72,6%.[4] En categorías de confianza y alto riesgo, el rank clásico y la cita de IA están convergiendo. En todo lo demás, la puerta trasera es más ancha.
La puerta trasera es estructural, no accidental
ChatGPT vs Perplexity vs Google AIO
Los tres grandes motores recuperan y citan de forma distinta. Dónde inviertes depende de cuál usan tus compradores.
«Optimizar para IA» es demasiado grueso para actuar. Cada motor tiene una pipeline de recuperación distinta y un conjunto distinto de fuentes en las que se apoya. Aquí está cómo difieren los tres más grandes, y qué significa cada diferencia para tu siguiente movimiento.
| Motor | Cómo recupera | Qué se cita | Tu movimiento |
|---|---|---|---|
| ChatGPT (Search) | Primero paramétrico — solo ~31% de los prompts activan una búsqueda web en vivo; el resto responde desde la memoria de los datos de entrenamiento. Usa el índice de Bing cuando sí busca. | Wikipedia domina las top fuentes (47,9%), luego Reddit y Forbes. Marcas mencionadas con frecuencia por toda la web abierta en el momento del entrenamiento. | Construye menciones de marca amplias y consistentes por toda la web (para vivir en los datos de entrenamiento) Y estructura las páginas para la recuperación en vivo. |
| Perplexity | RAG en tiempo real en cada consulta. Pipeline de seis etapas: intención → recuperación híbrida (BM25 + densa) → reranker de 3 niveles → ensamblaje del prompt con citas pre-embebidas → síntesis. Siempre cita. Indexa más de 200B de URLs. | Reddit (46,7%), YouTube, Gartner. Fuentes autoritativas, URLs frescas, datos originales de primera mano. Surge blogs nicho con facilidad. | El mayor apalancamiento para sitios pequeños. Pasajes autónomos con estadísticas + datos originales ganan citas incluso sin rank en el top-10. |
| Resúmenes de IA de Google | Anclado en el índice de Google vía el modelo de deep learning FastSearch / RankEmbed — entrenado con datos de clic + evaluadores de calidad, prioriza el matching semántico y la velocidad sobre las señales clásicas de enlaces. | Reddit (21%), YouTube, Quora, LinkedIn — el más diversificado de los tres. Solapamiento parcial con el rank orgánico clásico. | Posiciónate bien (fuerte viento a favor) Y responde las sub-preguntas del fan-out. Entre el 14 y el 52% de las citas vienen de fuera del top-10, según el estudio. |
Perplexity es el motor de mayor apalancamiento para un sitio pequeño. Ejecuta RAG en tiempo real en cada consulta, siempre cita, surge 4–8 fuentes por respuesta y extrae con facilidad blogs nicho e hilos de Reddit junto a Wikipedia. Si quieres ver tu trabajo de citas dar frutos lo más rápido posible, apunta primero a Perplexity — su diseño de producto es estructuralmente amigable con fuentes más pequeñas y bien estructuradas.
De dónde extrae cada motor sus principales citas
El estudio de 680M de citas de Profound — la mezcla de fuentes es radicalmente distinta por plataforma[7]
ChatGPT se apoya en Wikipedia (47,9% de su cuota de top fuente); Perplexity se apoya en Reddit (46,7%); los Resúmenes de IA de Google son los más diversificados, repartidos entre Reddit, YouTube, Quora y LinkedIn. Una implicación: un hilo de Reddit o una entidad fuerte de Wikipedia sobre ti puede valer más que otra página en tu propio dominio.
No te sobre-indexes en la mezcla de fuentes de ninguna plataforma
Los 7 patrones de escritura amigables con las citas
Esta es la parte que controlas por completo. Siete movimientos estructurales, cada uno con una razón medida o mecanística por la que gana citas.
La fuente académica fundacional aquí es el estudio GEO (Aggarwal et al., Princeton / Georgia Tech / IIT Delhi / Allen Institute, KDD 2024). En un benchmark de consultas diversas, los métodos GEO impulsaron la visibilidad de la fuente en las respuestas generativas hasta un 40%, y las tres tácticas con mejor rendimiento eran notablemente aburridas: añade estadísticas, añade citas y cita tus propias fuentes.[1] Aquí están los siete patrones que se derivan de ese trabajo y de sus réplicas en la industria, ordenados por dificultad.
| Patrón | Por qué gana citas | Dificultad |
|---|---|---|
| Lidera con la respuesta (pirámide invertida, 40–60 palabras) | RAG inyecta solo los 5–10 fragmentos recuperados principales. Una respuesta directa y autónoma mapea limpiamente sobre el embedding de la consulta y se levanta casi literalmente. | Fácil |
| Adjunta una estadística a cada afirmación, con atribución | La 'Adición de Estadísticas' de GEO subió la visibilidad ~22%. 'Según [fuente, fecha], X es Y%' le da al modelo un átomo citable y defendible. | Fácil |
| Añade citas de expertos | La 'Adición de Citas' de GEO fue la táctica individual más fuerte — ~37% de lift. Las citas directas de autoridades nombradas se leen como evidencia citable. | Media |
| Cita tus propias fuentes creíbles | Contraintuitivo pero medido: 'Citar Fuentes' de GEO subió la visibilidad PROPIA de la página citante ~30%. Referenciar datos primarios te hace parecer un hub. | Fácil |
| Define entidades explícitamente, nómbralas de forma consistente | Frases definitorias 'X es un…' + nomenclatura consistente por toda la web fortalecen la representación neuronal de la entidad, mejorando el recall y el matching de recuperación. | Media |
| Fragmenta para la recuperación — pasajes autónomos de 200–500 palabras | Benchmarks de NVIDIA: la fragmentación a nivel de página alcanzó 0,648 de precisión con la menor varianza. Cada sección debe responder una consulta de forma aislada — define, responde, sustenta, todo en un pasaje. | Media |
| Responde la SIGUIENTE pregunta lógica en pasajes adyacentes | Los motores generan sub-consultas de fan-out y extraen el fragmento que mejor responde cada una. La cobertura complementaria gana citas incluso cuando no estás en el top-10 (Jim Yu de BrightEdge). | Difícil |
Tácticas GEO por lift de visibilidad medido
Del paper GEO de KDD 2024 + la réplica industrial de The Digital Bloom[1][9]
El ganador contraintuitivo: citar tus propias fuentes creíbles sube tus probabilidades de cita. El modelo lee una página bien referenciada como un hub de confianza. La Adición de Citas (~37%) fue la táctica individual más fuerte en el benchmark GEO.
Los tres movimientos para hacer esta semana
1. Reescribe las introducciones de tus cinco mejores artículos como respuestas directas. De cuarenta a sesenta palabras, usando la frase exacta de la pregunta como el H2 directamente encima. Elimina cada apertura tipo «en este artículo exploraremos…». Este bloque único es lo que ChatGPT, Perplexity y Google AIO levantan con más frecuencia, a menudo casi literalmente. Lidera con la respuesta; explica después.
2. Adjunta una estadística atribuida a cada afirmación importante. «Según [fuente, fecha], X es Y%.» Esto hace dos cosas a la vez: satisface la táctica de Adición de Estadísticas de GEO, y le da al modelo un átomo autónomo y defendible que puede citar sin riesgo. Las afirmaciones vagas («muchos expertos creen») son lo opuesto — incitables.
3. Divide las secciones largas en pasajes autónomos de 200–500 palabras. Los benchmarks de recuperación de NVIDIA encontraron que la fragmentación a nivel de página alcanzó 0,648 de precisión con la menor varianza.[9] Cada pasaje debe definir la entidad, responder una pregunta y llevar su estadística de apoyo — porque el modelo puede ver ese pasaje en completo aislamiento del resto de tu página.
Datos originales: la palanca más fuerte
Si eres el origen de una cifra, eres la cita natural para esa cifra. Nada más compone como esto.
La táctica individual mejor respaldada en toda la literatura es publicar datos originales y propietarios. El mecanismo es simple: cuando ejecutas una encuesta, publicas un benchmark o lanzas un estudio, te conviertes en el origen de una estadística. Cada modelo que quiera usar esa cifra tiene exactamente un lugar al que atribuirla — tú. Una estadística propietaria es el «átomo citable» que los motores de respuesta levantan casi literalmente, y a diferencia de un párrafo bien escrito, ningún competidor puede simplemente reescribirlo mejor.
Aquí también es donde los datos son más contundentes sobre lo que no funciona. El estudio de 17.551 citas de SolCrys sobre la categoría de guías de compra AEO encontró que las páginas «.com» propias de los vendedores representaban solo el 0,85% de todas las citas combinadas — mientras Wikipedia, TechRadar y Reddit dominaban.[10] Incluso SolCrys, el propio editor del estudio, fue citado a solo un 4,82% de tasa de mención de categoría.
Qué predice realmente una cita de IA (y qué no)
La presencia de marca supera a los backlinks; tu propia página de ventas apenas registra[9][10]
El volumen de búsqueda de marca correlaciona con las citas LLM a 0,334 — más alto que cualquier métrica de enlaces (The Digital Bloom). Mientras tanto, las páginas autopromocionales propias del vendedor son el 0,85% de las citas (SolCrys). La conclusión: una mención editorial de terceros o un hilo de Reddit sobre ti es mucho más citable que tu propia página de «somos los mejores».
La jugada de datos originales para un equipo pequeño

Menciones de marca y presencia off-site
La correlación más fuerte en los datos no está en tu sitio web en absoluto. Está en todas partes menos ahí.
Como ~60% de las respuestas de ChatGPT vienen de la memoria paramétrica, la palanca de citas más fuerte es a menudo invisible en tu propia analítica: con qué frecuencia, y con qué consistencia, aparece tu marca por toda la web abierta. La síntesis de The Digital Bloom encontró que el volumen de búsqueda de marca es el predictor #1 de citas LLM con una correlación de 0,334 — más alto que cualquier métrica de backlinks — y que los sitios presentes en 4+ plataformas tienen 2,8× más probabilidades de aparecer en respuestas de ChatGPT.[9]
La evidencia a nivel de plataforma es igual de directa. Wikipedia compone aproximadamente el 22% de los datos de entrenamiento de los grandes LLM, por lo que una entidad con una página de Wikipedia es estructuralmente mucho más probable de ser recordada que una idéntica sin ella. Un análisis de junio de 2025 de más de 150.000 citas encontró Reddit citado en el 40,1% de los casos en ChatGPT, Perplexity, Gemini y Claude.[9] Estos son los lugares que los modelos realmente leen.
Para un sitio pequeño, la versión accionable es estrecha y factible:
- Sé consistente. Mismo nombre de marca, misma descripción de una línea, misma categoría en todas partes — tu sitio, LinkedIn, Crunchbase, G2, tu perfil de Reddit. Datos de entidad inconsistentes debilitan la representación neuronal que impulsa el recall.
- Gana menciones genuinas de terceros. Una sola reseña editorial estilo TechRadar o un hilo real de Reddit sobre ti es más citable que una docena de páginas en tu propio dominio.
- Aparece donde cita el motor de tu vertical. Para B2B suele ser LinkedIn + Reddit; para consumo/lifestyle es YouTube + Reddit. Participación real y útil — no drops promocionales.
- Busca una presencia honesta en Wikipedia si (y solo si) cumples las directrices de notabilidad. Moldea desproporcionadamente el recall paramétrico.
Schema y llms.txt: qué es real en 2026
Dos de los 'hacks de citas de IA' más sobrevendidos. Aquí está lo que las fuentes primarias realmente dicen.
Los datos estructurados aún importan — pero como señal de confianza y parseo, no como disparador garantizado de citas. El AI Mode potenciado por Gemini trata el schema como una forma de entender y confiar en tu contenido, no como una palanca de visualización. Usa JSON-LD, y aplica solo schema que genuinamente coincida con la página. La trampa en 2026 es que varios tipos de schema han sido retirados silenciosamente, así que construir una estrategia sobre ellos es esfuerzo desperdiciado.
| Tipo de schema | Estado 2026 | Qué necesitas saber |
|---|---|---|
| Article / BlogPosting | Usar | Columna vertebral estructural. La doc de Google del 10-12-2025 indica que NO hay propiedades obligatorias — mantenlo simple y preciso. Usa JSON-LD. |
| Organization | Usar | Refuerza la identidad de la entidad y los enlaces sameAs — alimenta la claridad de entidad que mejora el recall. |
| Product / LocalBusiness | Usar | Adapta el schema solo a la página. El AI Mode potenciado por Gemini trata el schema como señal de confianza, no como disparador de visualización. |
| FAQPage | Precaución | Los rich results de FAQ se retiraron de Google Search el 7 de mayo de 2026 (solo sitios gov/salud). Aún ayuda a un parser a leer la estructura de Q&A — pero no esperes un rich result. |
| HowTo | Obsoleto | Rich results eliminados para la mayoría de sitios en la limpieza de 2025. |
| ClaimReview / SpecialAnnouncement / VehicleListing + 4 más | Obsoleto | Entre los 7 tipos de datos estructurados que Google dejó obsoletos en jun/nov 2025. No construyas una estrategia sobre estos. |
El cambio destacado: según la propia documentación de FAQPage de Google, los rich results de FAQ dejaron de aparecer en Google Search el 7 de mayo de 2026, sobreviviendo solo para sitios autoritativos gubernamentales y de salud.[6] Los rich results de HowTo fueron eliminados para la mayoría de sitios en la limpieza de 2025, y Google dejó obsoletos siete tipos de datos estructurados entre junio y noviembre de 2025.[12] El marcado FAQPage y HowTo aún puede ayudar a un parser a entender tu estructura de Q&A — pero no esperes un rich result ni lo trates como garantía de cita. (Para el JSON-LD que sí deberías enviar, mira nuestra guía de schema markup para pequeñas empresas.)
Gary Illyes (Google), Search Central Live, julio 2025: Google NO soporta llms.txt y no tiene planes de hacerlo.
John Mueller comparó públicamente llms.txt con la obsoleta etiqueta meta keywords — ignorada durante más de una década.
Diciembre 2025: un archivo llms.txt apareció brevemente en la propia doc de desarrolladores de Google; preguntado en Bluesky si era un respaldo, Mueller respondió 'para ser directo, no'. El equipo de Search lo eliminó.
Ningún motor de respuesta importante ha confirmado usar llms.txt para ranking o citas. Es un estándar propuesto que publican algunos sitios con mucha documentación.
Veredicto honesto: bajo coste, poca evidencia. 'Probablemente no hace daño', pero NO es una palanca de citas. No le dediques tiempo real.
No malgastes un sprint en llms.txt
La checklist realista de citas
Todo lo anterior, secuenciado en lo que una persona sin presupuesto realmente puede enviar.
La investigación es exhaustiva; tu tiempo no. Aquí está el orden en el que los sitios de una sola persona están enviando de verdad en 2026, cargado al frente con los movimientos de mayor apalancamiento y menor esfuerzo.
| Fase | Tiempo | Qué estás haciendo |
|---|---|---|
| 1. Estructura | Semana 1 | Reescribe tus 5 mejores introducciones como respuestas directas de 40–60 palabras bajo H2 con la pregunta exacta. Adjunta una estadística atribuida a cada afirmación clave. Divide las secciones largas en pasajes autónomos de 200–500 palabras. |
| 2. Schema | Semana 1 | Envía JSON-LD de Article + Organization + Author en todo el sitio. Mantenlo preciso y adaptado a cada página. Salta llms.txt. No construyas sobre los rich results de FAQPage/HowTo. |
| 3. Cobertura de fan-out | Semanas 2–4 | Para cada tema prioritario, añade pasajes adyacentes que respondan las siguientes preguntas lógicas. Así es como ganas el 14–52% de las citas que evitan el top-10. |
| 4. Datos originales | Mes 2 | Publica una pieza de investigación de primera mano — una encuesta de 200 respuestas, un desglose de 50 ejemplos, un benchmark defendible — con un párrafo de metodología. Conviértete en el origen de una cifra. |
| 5. Presencia de marca | Meses 2–3 | Haz los datos de entidad consistentes en todas partes. Gana menciones genuinas de terceros. Participa de verdad en las 2 plataformas que más citan los motores de tu vertical (normalmente Reddit + LinkedIn o YouTube). |
| 6. Cadencia | Continuo | Publica de forma constante. El contenido fresco y consistentemente estructurado te mantiene en la mezcla rotativa de fuentes (40–60% de las fuentes citadas cambia mes a mes). El silencio cuesta citas. |
Dónde encaja News Factory
Quienquiera que mantenga tu volante editorial girando — tú, un freelancer o un sistema asistido por IA como News Factory — la estrategia se mantiene. Las citas no van a la página de ventas más ruidosa. Van a la fuente que respondió la pregunta exacta, con una cifra atribuible, en un pasaje que un sistema de recuperación podría levantar por sí solo. Construye eso, de forma consistente, en los lugares que los modelos realmente leen.
→ Haz esto ahora: Elige tres páginas. Reescribe cada introducción como una respuesta directa de 40–60 palabras bajo un H2 con la pregunta exacta, adjunta una estadística atribuida a la afirmación central de cada una, y añade schema de Article + Author. Eso es el trabajo de esta noche — y te pone por delante de casi todos los sitios pequeños que aún optimizan solo para enlaces azules.
Lectura relacionada
- AEO vs SEO en 2026: Por Qué los Motores de Respuesta Son la Nueva Búsqueda — el marco estratégico dentro del cual encaja esta guía.
- Resúmenes de IA y SGE: Cómo los Sitios Pequeños Pueden Seguir Ganando Clics en 2026 — el informe de daños de Google AIO y el carve-out de consultas comparativas.
- Schema Markup para Pequeñas Empresas — los bloques JSON-LD que enviar en 30 minutos.
- Autoridad Temática: Por Qué Publicar Más (Buen) Contenido Gana en SEO — el problema de cadencia y cobertura de fan-out en profundidad.
Referencias y Fuentes
Sobre las cifras del top-10: los estudios difieren por metodología (conjunto completo de citas vs. solo citas que se solapan con el top-100; ventanas de fechas distintas; los AI Overviews cambian rápido). La lectura honesta es un rango (38–76%) y una dirección, no una cifra única y asentada.