How AI Citation Actually Works
Before you can be cited, you have to understand the two completely different ways an answer engine can find you.
Getting cited by an AI answer engine means being the source the model quotes, names, or links when it composes an answer. But there isn't one path to that — there are two, and they behave so differently that optimising for one while ignoring the other is the most common reason good content never gets cited.
The first path is parametric knowledge — what the model absorbed from its training data and now recalls from memory. The second is retrieved knowledge — what it pulls live from the web at answer time via Retrieval-Augmented Generation (RAG). The split matters enormously: by The Digital Bloom's December 2025 synthesis, roughly 60% of ChatGPT queries are answered purely from parametric memory without triggering a web search at all, and one practitioner estimate puts live web search at only ~31% of prompts.[9] For the majority of answers, what gets you mentioned is your training-data footprint — how often and how consistently your brand appears across the open web — not any live SEO move.
When an engine does retrieve, a multi-stage pipeline decides what reaches the model:
- Query encoding: the user's question becomes a vector embedding (e.g. OpenAI's text-embedding-3-large at 3,072 dimensions).
- Hybrid retrieval: dense semantic search (embeddings) is fused with sparse keyword matching (BM25) — a combination that delivers roughly a 48% improvement over either method alone.[9]
- Reranking: cross-encoder models re-score the candidate passages for the specific query (improving ranking quality by ~28% on NDCG@10).
- Generation: only the top 5-10 retrieved chunks are injected into the prompt as context. Everything else is invisible to the model for that answer.
That final number is the whole game. If your answer is smeared across a long, flowing essay, no single chunk is self-sufficient, and you lose the slot to a competitor whose passage stands alone. As Discovered Labs put it, AI engines select on semantic relevance, entity clarity, and third-party validation — not link equity the way classical SEO did.
Two footprints, two strategies
Answer engines this guide covers
The Top-10 Myth: The Honest Numbers
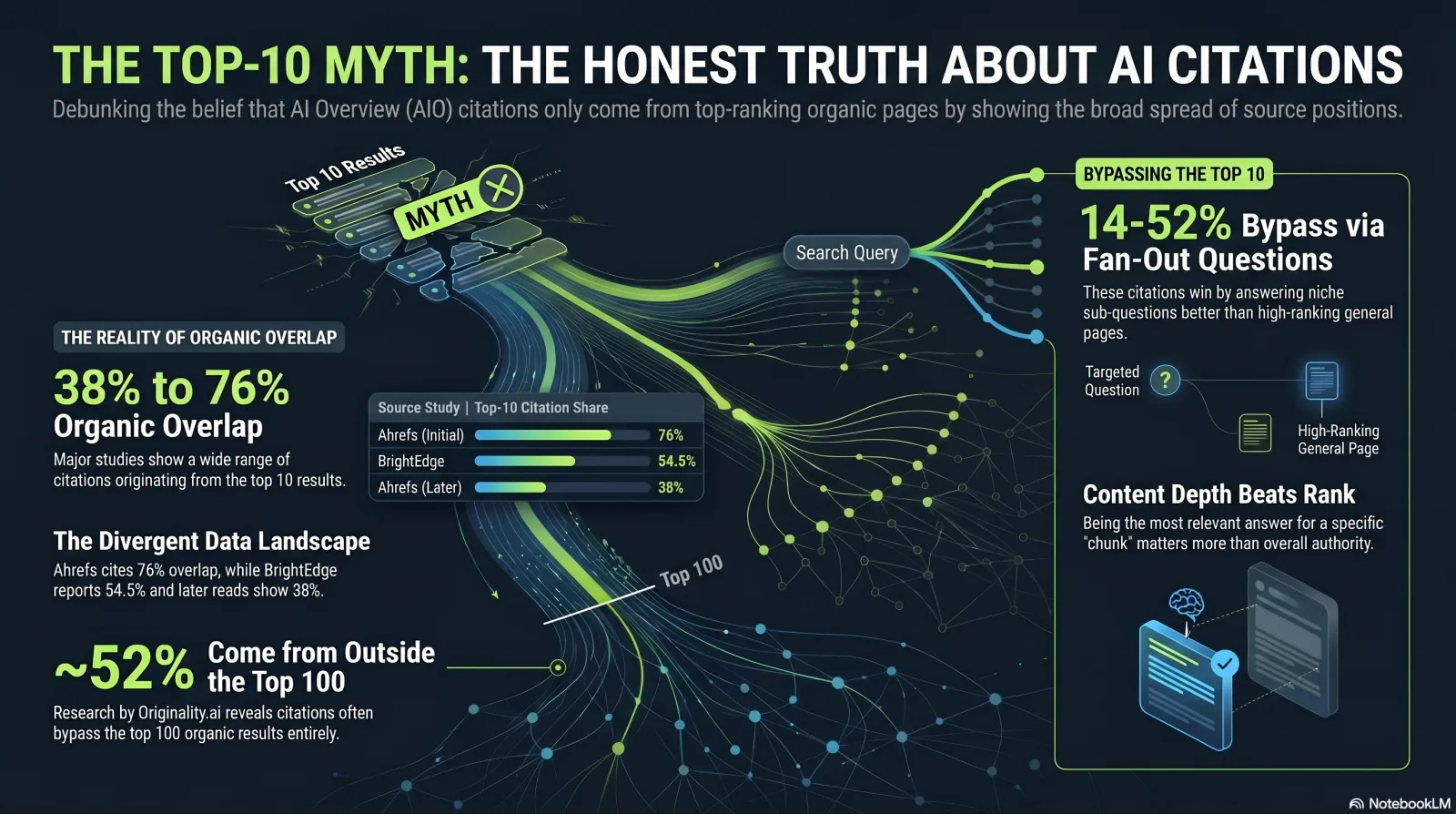
You've seen '76% of AI citations come from the top 10.' You've also seen 38%. Both are real. Here's why.
The single most-quoted statistic in this space is some version of "most AI citations come from pages that already rank in Google's top 10." It is true, partly true, and misleading all at once — depending entirely on whose study you read and how they counted. Here is the honest spread:
What share of AI-engine citations comes from top-10 organic?
Five credible measurements that disagree — because they measured different things[2][3][4]
These numbers are NOT contradictory. Ahrefs' 76% counts cited pages that rank top-10 across its whole citation set; Originality.ai's 52.5% is the top-10 share of only the citations that overlap the top-100; the 38% read came later from a different keyword sample as query fan-out pulled deeper pages. The honest takeaway is a range and a direction — not one magic number.
Read together, three things are clearly true:
- Ranking well is a strong tailwind. Ahrefs' analysis of 1.9M citations across 1M AI Overviews found 76.1% of cited pages rank in the top 10, with a median cited rank of 3 and the primary cited URL sitting at a median position of 2.[2] If you can rank, rank.
- But it is not a guarantee. Even the #1 result being cited is, in Ahrefs' words, "a coin flip at best." Originality.ai pegs a top-1 result's citation probability around 58%.[3]
- And a large minority of citations bypass the top-10 entirely. Originality.ai found ~52% of all AI Overview citations come from pages outside the top-100; Ahrefs found 14.4% from pages that don't rank top-100 at all.[2][3] That gap is the opening for everyone who can't out-rank the incumbents.
The convergence trend matters too. BrightEdge's 16-month longitudinal study found AI-Overview-to-organic overlap rose from 32.3% at launch (May 2024) to 54.5% by the end of 2025, with YMYL verticals overlapping most — Healthcare at 75.3%, Education at 72.6%.[4] In trustworthy, high-stakes categories, classical rank and AI citation are converging. In everything else, the back door is wider.
The back door is structural, not accidental
ChatGPT vs Perplexity vs Google AIO
The three big engines retrieve and cite differently. Where you invest depends on which one your buyers use.
"Optimise for AI" is too coarse to act on. Each engine has a distinct retrieval pipeline and a distinct set of sources it leans on. Here's how the three biggest differ, and what each difference means for your next move.
| Engine | How it retrieves | What gets cited | Your move |
|---|---|---|---|
| ChatGPT (Search) | Parametric first — only ~31% of prompts trigger a live web search; otherwise answers from training-data memory. Uses Bing's index when it does search. | Wikipedia dominates top sources (47.9%), then Reddit and Forbes. Brands frequently mentioned across the open web at training time. | Build broad, consistent brand mentions across the web (so you live in the training data) AND structure pages for live retrieval. |
| Perplexity | Real-time RAG on every query. Six-stage pipeline: intent → hybrid retrieval (BM25 + dense) → 3-tier reranker → prompt assembly with pre-embedded citations → synthesis. Always cites. Indexes 200B+ URLs. | Reddit (46.7%), YouTube, Gartner. Authoritative sources, fresh URLs, original first-party data. Surfaces niche blogs readily. | Highest small-site leverage. Self-contained, stat-bearing passages + original data win citations even without top-10 rank. |
| Google AI Overviews | Grounded in Google's index via the FastSearch / RankEmbed deep-learning model — trained on click + quality-rater data, prioritises semantic matching and speed over classic link signals. | Reddit (21%), YouTube, Quora, LinkedIn — most diversified of the three. Partial overlap with classic organic rank. | Rank well (strong tailwind) AND answer fan-out sub-questions. 14–52% of citations come from outside the top-10, depending on study. |
Perplexity is the highest-leverage engine for a small site. It runs real-time RAG on every single query, always cites, surfaces 4-8 sources per answer, and readily pulls niche blogs and Reddit threads alongside Wikipedia. If you want to see your citation work pay off fastest, target Perplexity first — its product design is structurally friendly to smaller, well-structured sources.
Where each engine pulls its top citations from
Profound's 680M-citation study — the source mix is wildly different per platform[7]
ChatGPT leans on Wikipedia (47.9% of its top-source share); Perplexity leans on Reddit (46.7%); Google AI Overviews is the most diversified, spreading across Reddit, YouTube, Quora and LinkedIn. One implication: a Reddit thread or a strong Wikipedia entity about you can be worth more than another page on your own domain.
Don't over-index on any single platform's source mix
The 7 Citation-Friendly Writing Patterns
This is the part you fully control. Seven structural moves, each with a measured or mechanistic reason it earns citations.
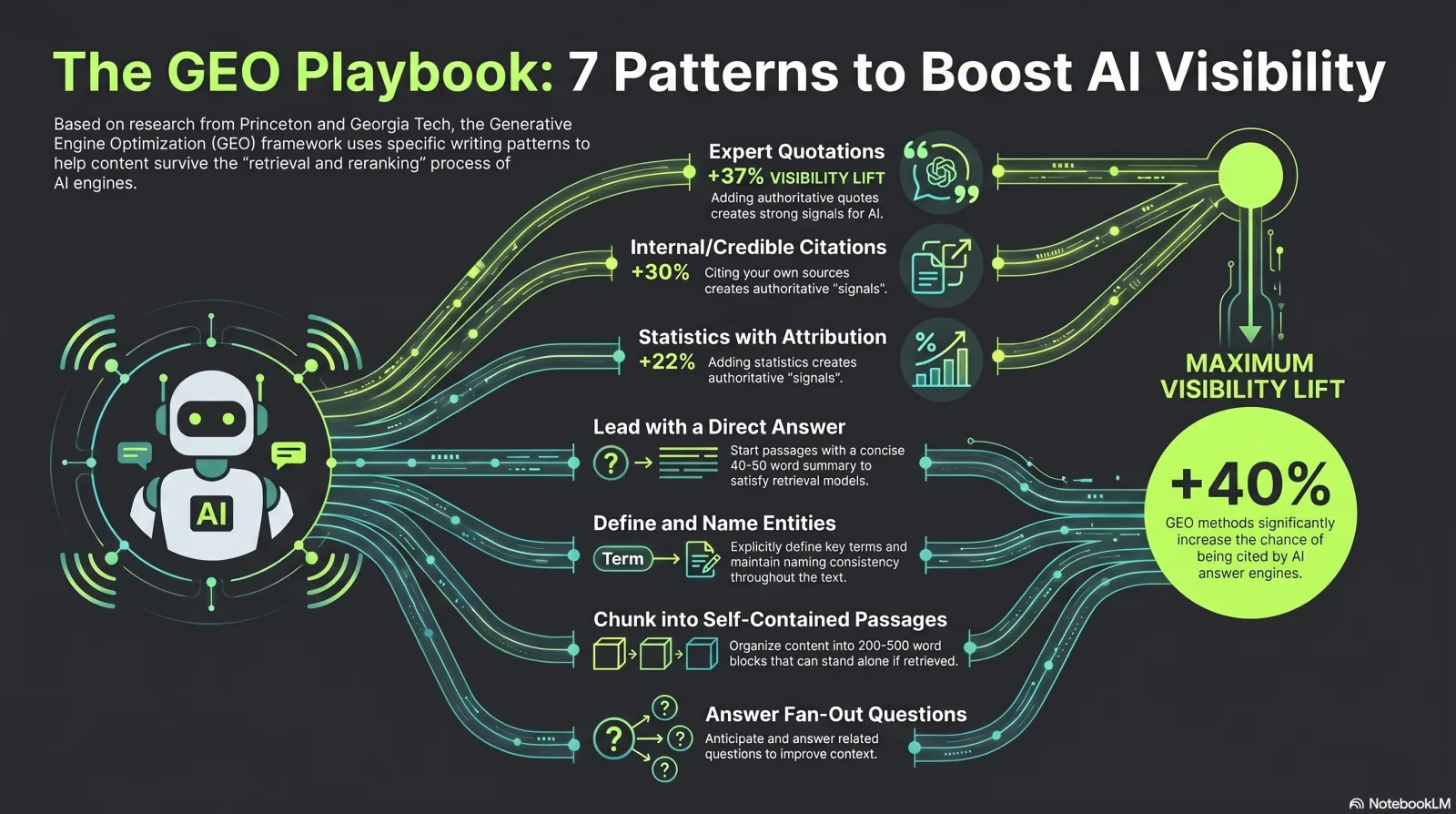
The foundational academic source here is the GEO study (Aggarwal et al., Princeton / Georgia Tech / IIT Delhi / Allen Institute, KDD 2024). Across a benchmark of diverse queries, GEO methods boosted source visibility in generative responses by up to 40%, and the three top-performing tactics were remarkably boring: add statistics, add quotations, and cite your own sources.[1] Here are the seven patterns that follow from that work and its industry replications, sorted by difficulty.
| Pattern | Why it earns citations | Difficulty |
|---|---|---|
| Lead with the answer (inverted pyramid, 40–60 words) | RAG injects only the top 5–10 retrieved chunks. A self-contained direct answer maps cleanly onto the query embedding and gets lifted verbatim. | Easy |
| Attach a stat to every claim, with attribution | GEO 'Statistics Addition' lifted visibility ~22%. 'According to [source, date], X is Y%' gives the model a quotable, defensible atom. | Easy |
| Add expert quotations | GEO 'Quotation Addition' was the single strongest tactic — ~37% lift. Direct quotes from named authorities read as citable evidence. | Medium |
| Cite your own credible sources | Counterintuitive but measured: GEO 'Cite Sources' raised the citing page's OWN visibility ~30%. Referencing primary data makes you look like a hub. | Easy |
| Define entities explicitly, name them consistently | 'X is a …' definitional sentences + consistent naming across the web strengthen the entity's neural representation, improving recall and retrieval matching. | Medium |
| Chunk for retrieval — self-contained 200–500-word passages | NVIDIA benchmarks: page-level chunking hit 0.648 accuracy with lowest variance. Each section must answer one query in isolation — define, answer, support, all in one passage. | Medium |
| Answer the NEXT logical question in adjacent passages | Engines generate fan-out sub-queries and pull the chunk that best answers each. Complementary coverage wins citations even when you don't rank top-10 (BrightEdge's Jim Yu). | Hard |
GEO tactics by measured visibility lift
From the KDD 2024 GEO paper + The Digital Bloom's industry replication[1][9]
The counterintuitive winner: citing your own credible sources raises your citation odds. The model reads a well-referenced page as a trustworthy hub. Quotation Addition (~37%) was the single strongest individual tactic in the GEO benchmark.
The three moves to make this week
1. Rewrite your top five article leads as direct answers. Forty to sixty words, using the exact question phrasing as the H2 directly above. Strip every "in this article we'll explore…" opener. This single block is what ChatGPT, Perplexity and Google AIO lift most often, frequently verbatim. Lead with the answer; explain afterwards.
2. Attach an attributed statistic to every important claim. "According to [source, date], X is Y%." This does two things at once: it satisfies GEO's Statistics-Addition tactic, and it gives the model a self-contained, defensible atom it can quote without risk. Vague claims ("many experts believe") are the opposite — unquotable.
3. Break long sections into self-contained 200-500 word passages. NVIDIA's retrieval benchmarks found page-level chunking hit 0.648 accuracy with the lowest variance.[9] Each passage should define the entity, answer one question, and carry its supporting stat — because the model may see that passage in complete isolation from the rest of your page.
Original Data: The Strongest Lever
If you are the origin of a number, you are the natural citation for that number. Nothing else compounds like this.
The best-supported single tactic in the entire literature is publishing original, proprietary data. The mechanism is simple: when you run a survey, publish a benchmark, or release a study, you become the origin of a statistic. Every model that wants to use that number has exactly one place to attribute it — you. A proprietary stat is the "quotable atom" answer engines lift verbatim, and unlike a well-written paragraph, no competitor can simply rewrite it better.
This is also where the data is bluntest about what does not work. SolCrys's 17,551-citation study of the AEO buyer-guide category found that vendors' own ".com" pages accounted for just 0.85% of all citations combined — while Wikipedia, TechRadar and Reddit dominated.[10] Even SolCrys, the study's own publisher, was cited at only a 4.82% category mention rate.
What actually predicts an AI citation (and what doesn't)
Brand presence beats backlinks; your own sales page barely registers[9][10]
Brand search volume correlates with LLM citations at 0.334 — higher than any link metric (The Digital Bloom). Meanwhile vendor-owned self-promotional pages are 0.85% of citations (SolCrys). The takeaway: a third-party editorial mention or a Reddit thread about you is far more citable than your own "we're the best" page.
The original-data play for a small team
Brand Mentions & Off-Site Presence
The strongest correlation in the data isn't on your website at all. It's everywhere else.
Because ~60% of ChatGPT answers come from parametric memory, the strongest citation lever is often invisible on your own analytics: how often, and how consistently, your brand appears across the open web. The Digital Bloom's synthesis found brand search volume is the #1 predictor of LLM citations at a 0.334 correlation — higher than any backlink metric — and that sites present on 4+ platforms are 2.8× more likely to appear in ChatGPT responses.[9]
The platform-level evidence is just as direct. Wikipedia makes up roughly 22% of major LLM training data, which is why an entity with a Wikipedia page is structurally far more likely to be recalled than an identical one without. A June 2025 analysis of 150,000+ citations found Reddit cited in 40.1% of cases across ChatGPT, Perplexity, Gemini and Claude.[9] These are the places the models actually read.
For a small site, the actionable version is narrow and doable:
- Be consistent. Same brand name, same one-line description, same category everywhere — your site, LinkedIn, Crunchbase, G2, your Reddit profile. Inconsistent entity data weakens the neural representation that drives recall.
- Earn genuine third-party mentions. A single TechRadar-style editorial review or a real Reddit thread about you is more citable than a dozen pages on your own domain.
- Show up where your vertical's engine cites. For B2B that's usually LinkedIn + Reddit; for consumer/lifestyle it's YouTube + Reddit. Real, helpful participation — not promotional drops.
- Pursue a Wikipedia presence honestly if (and only if) you meet notability guidelines. It disproportionately shapes parametric recall.
Schema & llms.txt: What's Real in 2026
Two of the most over-sold 'AI citation hacks.' Here's what the primary sources actually say.
Structured data still matters — but as a trust-and-parse signal, not a guaranteed citation trigger. Gemini-powered AI Mode treats schema as a way to understand and trust your content, not as a display lever. Use JSON-LD, and only apply schema that genuinely matches the page. The catch in 2026 is that several schema types have been quietly retired, so building a strategy on them is wasted effort.
| Schema type | 2026 status | What you need to know |
|---|---|---|
| Article / BlogPosting | Use | Structural backbone. Google's 2025-12-10 docs state NO required properties — keep it simple and accurate. Use JSON-LD. |
| Organization | Use | Reinforces entity identity and sameAs links — feeds the entity clarity that improves recall. |
| Product / LocalBusiness | Use | Match schema to the page only. Gemini-powered AI Mode treats schema as a trust signal, not a display trigger. |
| FAQPage | Caution | FAQ rich results retired in Google Search as of May 7, 2026 (gov/health sites only). Still helps a parser read Q&A structure — just don't expect a rich result. |
| HowTo | Deprecated | Rich results removed for most sites in the 2025 cleanup. |
| ClaimReview / SpecialAnnouncement / VehicleListing + 4 more | Deprecated | Among the 7 structured-data types Google deprecated across Jun/Nov 2025. Don't build a strategy on these. |
The headline change: per Google's own FAQPage documentation, FAQ rich results stopped appearing in Google Search as of May 7, 2026, surviving only for government- and health-focused authoritative sites.[6] HowTo rich results were removed for most sites in the 2025 cleanup, and Google deprecated seven structured-data types across June and November 2025.[12] FAQPage and HowTo markup can still help a parser understand your Q&A structure — just don't expect a rich result or treat them as a citation guarantee. (For the JSON-LD you should still ship, see our schema markup for small businesses guide.)
Gary Illyes (Google), Search Central Live, July 2025: Google does NOT support llms.txt and has no plans to.
John Mueller publicly compared llms.txt to the deprecated meta keywords tag — ignored for over a decade.
Dec 2025: an llms.txt file briefly appeared in Google's own developer docs; asked on Bluesky if it was an endorsement, Mueller replied 'to be direct, no.' The Search team removed it.
No major answer engine has confirmed using llms.txt for ranking or citation. It's a proposed standard a few doc-heavy sites publish.
Honest verdict: low-cost, low-evidence. 'Probably doesn't hurt,' but it is NOT a citation lever. Don't spend real time on it.
Don't waste a sprint on llms.txt
The Realistic Citation Checklist
Everything above, sequenced into what one person with no budget can actually ship.
The research is comprehensive; your time is not. Here is the order single-person sites are actually shipping in 2026, front-loaded with the highest-leverage, lowest-effort moves.
| Phase | Time | What you're doing |
|---|---|---|
| 1. Structure | Week 1 | Rewrite your top 5 leads as 40-60 word direct answers under exact-question H2s. Attach an attributed stat to every key claim. Break long sections into self-contained 200-500 word passages. |
| 2. Schema | Week 1 | Ship Article + Organization + Author JSON-LD sitewide. Keep it accurate and matched to each page. Skip llms.txt. Don't build on FAQPage/HowTo rich results. |
| 3. Fan-out coverage | Weeks 2-4 | For each priority topic, add adjacent passages that answer the next logical questions. This is how you earn the 14-52% of citations that bypass the top-10. |
| 4. Original data | Month 2 | Publish one piece of first-party research — a 200-respondent poll, a 50-example teardown, a defensible benchmark — with a one-paragraph methodology. Become the origin of a number. |
| 5. Brand presence | Months 2-3 | Make entity data consistent everywhere. Earn genuine third-party mentions. Participate for real on the 2 platforms your vertical's engines cite most (usually Reddit + LinkedIn or YouTube). |
| 6. Cadence | Ongoing | Publish steadily. Fresh, consistently-structured content keeps you in the rotating source mix (40-60% of cited sources change month-to-month). Silence costs citations. |
Where News Factory fits
Whoever keeps your editorial flywheel turning — you, a freelancer, or an AI-assisted system like News Factory — the strategy holds. Citations don't go to the loudest sales page. They go to the source that answered the exact question, with an attributable number, in a passage a retrieval system could lift on its own. Build that, consistently, in the places the models actually read.
→ Do this now: Pick three pages. Rewrite each lead as a 40-60 word direct answer under an exact-question H2, attach one attributed statistic to the central claim of each, and add Article + Author schema. That's tonight's work — and it puts you ahead of almost every small site that is still optimising only for blue links.
Related reading
- AEO vs SEO in 2026: Why Answer Engines Are the New Search — the strategic frame this guide sits inside.
- AI Overviews & SGE: How Small Sites Can Still Win Clicks in 2026 — the Google-AIO damage report and the comparison-query carveout.
- Schema Markup for Small Businesses — the JSON-LD blocks to ship in 30 minutes.
- Topical Authority: Why Publishing More (Good) Content Wins SEO — the cadence and fan-out coverage problem in depth.
References & Sources
On the top-10 numbers: studies differ by methodology (whole-citation set vs. only citations overlapping the top-100; different date windows; AI Overviews change fast). The honest reading is a range (38-76%) and a direction, not a single settled figure.