Como funciona realmente a citação por IA
Antes de poderes ser citado, tens de entender as duas formas completamente distintas pelas quais um motor de resposta te pode encontrar.
Ser citado por um motor de resposta de IA significa ser a fonte que o modelo cita, nomeia ou liga ao compor uma resposta. Mas não há um só caminho para isso — há dois, e comportam-se de forma tão distinta que otimizar para um ignorando o outro é a razão mais comum pela qual bom conteúdo nunca é citado.
O primeiro caminho é o conhecimento paramétrico — o que o modelo absorveu dos seus dados de treino e agora recorda de memória. O segundo é o conhecimento recuperado — o que ele extrai ao vivo da web no momento de responder via Geração Aumentada por Recuperação (RAG). A divisão importa enormemente: segundo a síntese de dezembro de 2025 da The Digital Bloom, aproximadamente 60% das consultas do ChatGPT são respondidas puramente a partir da memória paramétrica sem ativar qualquer pesquisa web, e uma estimativa de um profissional situa a pesquisa web ao vivo em apenas ~31% dos prompts.[9] Para a maioria das respostas, o que te torna mencionado é a tua pegada nos dados de treino — com que frequência e consistência a tua marca aparece pela web aberta — não qualquer movimento de SEO ao vivo.
Quando um motor de facto recupera, um pipeline multifásico decide o que chega ao modelo:
- Codificação da consulta: a pergunta do utilizador torna-se um embedding vetorial (p. ex., text-embedding-3-large da OpenAI com 3.072 dimensões).
- Recuperação híbrida: a pesquisa semântica densa (embeddings) funde-se com o matching de keywords esparso (BM25) — uma combinação que traz aproximadamente uma melhoria de 48% sobre qualquer um dos métodos isoladamente.[9]
- Reranking: modelos cross-encoder repontuam as passagens candidatas para a consulta concreta (melhorando a qualidade do ranking ~28% em NDCG@10).
- Geração: apenas os 5–10 chunks recuperados principais são injetados no prompt como contexto. Tudo o resto é invisível para o modelo nessa resposta.
Esse número final é todo o jogo. Se a tua resposta está espalhada por um ensaio longo e fluido, nenhum chunk é autossuficiente, e perdes o lugar para um concorrente cuja passagem se sustenta sozinha. Como disse a Discovered Labs, os motores de IA selecionam por relevância semântica, clareza de entidade e validação de terceiros — não por equity de links como fazia o SEO clássico.
Duas pegadas, duas estratégias
Motores de resposta que este guia cobre
O mito do top-10: os números honestos
Já viste '76% das citações de IA vêm do top 10'. Também já viste 38%. Ambos são reais. Eis porquê.
A estatística mais citada neste espaço é alguma versão de «a maioria das citações de IA vem de páginas que já posicionam no top 10 do Google». É verdadeira, parcialmente verdadeira e enganosa ao mesmo tempo — dependendo inteiramente de que estudo lês e de como contaram. Eis o intervalo honesto:
Que quota das citações de motores de IA vem do top-10 orgânico?
Cinco medições credíveis que divergem — porque mediram coisas distintas[2][3][4]
Estes números NÃO são contraditórios. Os 76% da Ahrefs contam páginas citadas que posicionam top-10 em todo o seu conjunto de citações; os 52,5% da Originality.ai são a quota top-10 só das citações que se sobrepõem ao top-100; a leitura dos 38% veio depois de uma amostra de keywords distinta quando o fan-out puxou páginas mais profundas. A conclusão honesta é um intervalo e uma direção — não um número mágico.
Lidas em conjunto, três coisas são claramente verdadeiras:
- Posicionar-se bem é um forte vento a favor. A análise da Ahrefs de 1,9M de citações em 1M de AI Overviews encontrou que 76,1% das páginas citadas posicionam no top 10, com um rank citado mediano de 3 e o URL citado principal numa posição mediana de 2.[2] Se conseguires posicionar, posiciona.
- Mas não é garantia. Até o resultado #1 ser citado é, nas palavras da Ahrefs, «uma moeda ao ar na melhor das hipóteses». A Originality.ai situa a probabilidade de citação de um resultado top-1 em torno dos 58%.[3]
- E uma grande minoria de citações evita o top-10 por completo. A Originality.ai encontrou que ~52% de todas as citações de AI Overviews vêm de páginas fora do top-100; a Ahrefs encontrou 14,4% de páginas que não posicionam de todo no top-100.[2][3] Essa lacuna é a abertura para todos os que não conseguem superar os incumbentes no ranking.
A tendência de convergência também importa. O estudo longitudinal de 16 meses da BrightEdge encontrou que a sobreposição de AI Overviews com o orgânico subiu de 32,3% no lançamento (maio de 2024) para 54,5% no fim de 2025, com os verticais YMYL a sobrepor-se mais — Saúde nos 75,3%, Educação nos 72,6%.[4] Em categorias de confiança e alto risco, o ranking clássico e a citação de IA estão a convergir. Em tudo o resto, a porta das traseiras é mais larga.
A porta das traseiras é estrutural, não acidental

ChatGPT vs Perplexity vs Google AIO
Os três grandes motores recuperam e citam de forma distinta. Onde investes depende de qual deles os teus compradores usam.
«Otimizar para IA» é demasiado grosseiro para agir. Cada motor tem um pipeline de recuperação distinto e um conjunto distinto de fontes em que se apoia. Eis como diferem os três maiores, e o que cada diferença significa para o teu próximo movimento.
| Motor | Como recupera | O que é citado | O teu movimento |
|---|---|---|---|
| ChatGPT (Search) | Primeiro paramétrico — só ~31% dos prompts ativam uma pesquisa web ao vivo; o resto responde a partir da memória dos dados de treino. Usa o índice do Bing quando pesquisa. | A Wikipedia domina as top fontes (47,9%), depois Reddit e Forbes. Marcas mencionadas frequentemente pela web aberta no momento do treino. | Constrói menções de marca amplas e consistentes pela web (para viveres nos dados de treino) E estrutura as páginas para a recuperação ao vivo. |
| Perplexity | RAG em tempo real em cada consulta. Pipeline de seis fases: intenção → recuperação híbrida (BM25 + densa) → reranker de 3 níveis → montagem do prompt com citações pré-incorporadas → síntese. Cita sempre. Indexa mais de 200 mil milhões de URLs. | Reddit (46,7%), YouTube, Gartner. Fontes autoritativas, URLs frescos, dados originais de primeira mão. Faz emergir blogs de nicho com facilidade. | Maior alavancagem para sites pequenos. Passagens autónomas com estatísticas + dados originais ganham citações mesmo sem ranking no top-10. |
| Visões Gerais de IA do Google | Ancorado no índice do Google via o modelo de deep learning FastSearch / RankEmbed — treinado com dados de cliques + avaliadores de qualidade, prioriza o matching semântico e a velocidade sobre os sinais clássicos de links. | Reddit (21%), YouTube, Quora, LinkedIn — o mais diversificado dos três. Sobreposição parcial com o ranking orgânico clássico. | Posiciona-te bem (forte vento a favor) E responde às subperguntas do fan-out. Entre 14 e 52% das citações vêm de fora do top-10, consoante o estudo. |
O Perplexity é o motor de maior alavancagem para um site pequeno. Executa RAG em tempo real em cada consulta, cita sempre, faz emergir 4–8 fontes por resposta e puxa com facilidade blogs de nicho e tópicos do Reddit ao lado da Wikipedia. Se quiseres ver o teu trabalho de citações dar frutos o mais rápido possível, aponta primeiro ao Perplexity — o seu design de produto é estruturalmente amigável a fontes mais pequenas e bem estruturadas.
De onde cada motor puxa as suas principais citações
O estudo de 680M de citações da Profound — a mistura de fontes é radicalmente distinta por plataforma[7]
O ChatGPT apoia-se na Wikipedia (47,9% da sua quota de top fonte); o Perplexity apoia-se no Reddit (46,7%); as Visões Gerais de IA do Google são as mais diversificadas, espalhando-se por Reddit, YouTube, Quora e LinkedIn. Uma implicação: um tópico do Reddit ou uma entidade forte da Wikipedia sobre ti pode valer mais do que outra página no teu próprio domínio.
Não te sobre-indexes na mistura de fontes de uma só plataforma
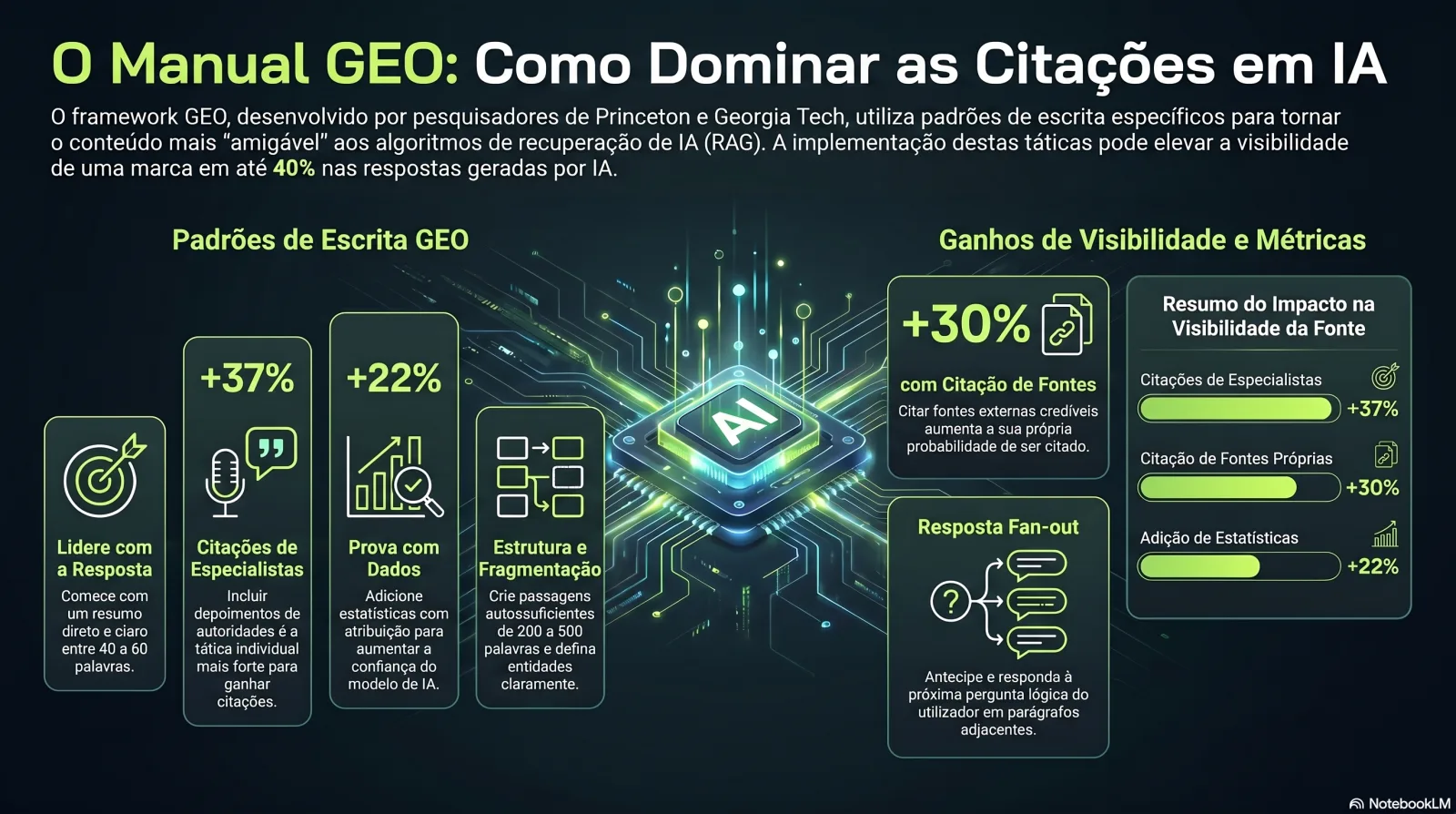
Os 7 padrões de escrita amigáveis às citações
Esta é a parte que controlas por completo. Sete movimentos estruturais, cada um com uma razão medida ou mecanística pela qual ganha citações.
A fonte académica fundacional aqui é o estudo GEO (Aggarwal et al., Princeton / Georgia Tech / IIT Delhi / Allen Institute, KDD 2024). Num benchmark de consultas diversas, os métodos GEO impulsionaram a visibilidade da fonte nas respostas generativas até 40%, e as três táticas de melhor desempenho eram notavelmente aborrecidas: adicionar estatísticas, adicionar citações e citar as próprias fontes.[1] Eis os sete padrões que decorrem desse trabalho e das suas réplicas na indústria, ordenados por dificuldade.
| Padrão | Porque ganha citações | Dificuldade |
|---|---|---|
| Lidera com a resposta (pirâmide invertida, 40–60 palavras) | O RAG injeta apenas os 5–10 chunks recuperados principais. Uma resposta direta e autónoma mapeia limpamente o embedding da consulta e é levantada quase literalmente. | Fácil |
| Anexa uma estatística a cada afirmação, com atribuição | A 'Adição de Estatísticas' do GEO aumentou a visibilidade ~22%. 'Segundo [fonte, data], X é Y%' dá ao modelo um átomo citável e defensável. | Fácil |
| Adiciona citações de especialistas | A 'Adição de Citações' do GEO foi a tática individual mais forte — ~37% de ganho. Citações diretas de autoridades nomeadas leem-se como evidência citável. | Médio |
| Cita as tuas próprias fontes credíveis | Contraintuitivo mas medido: 'Citar Fontes' do GEO elevou a visibilidade PRÓPRIA da página citante ~30%. Referenciar dados primários faz-te parecer um hub. | Fácil |
| Define entidades explicitamente, nomeia-as de forma consistente | Frases definitórias 'X é um…' + nomenclatura consistente pela web fortalecem a representação neuronal da entidade, melhorando o recall e o matching de recuperação. | Médio |
| Fragmenta para a recuperação — passagens autónomas de 200–500 palavras | Benchmarks da NVIDIA: a fragmentação ao nível da página atingiu 0,648 de precisão com a menor variância. Cada secção deve responder a uma consulta isoladamente — definir, responder, sustentar, tudo numa passagem. | Médio |
| Responde à PRÓXIMA pergunta lógica em passagens adjacentes | Os motores geram subconsultas de fan-out e extraem o chunk que melhor responde a cada uma. A cobertura complementar ganha citações mesmo quando não estás no top-10 (Jim Yu, da BrightEdge). | Difícil |
Táticas GEO por ganho de visibilidade medido
Do paper GEO de KDD 2024 + a réplica industrial da The Digital Bloom[1][9]
O vencedor contraintuitivo: citar as tuas próprias fontes credíveis aumenta as tuas probabilidades de citação. O modelo lê uma página bem referenciada como um hub de confiança. A Adição de Citações (~37%) foi a tática individual mais forte no benchmark GEO.
Os três movimentos para fazer esta semana
1. Reescreve as introduções dos teus cinco melhores artigos como respostas diretas. De quarenta a sessenta palavras, usando a frase exata da pergunta como o H2 diretamente acima. Elimina cada abertura do tipo «neste artigo vamos explorar…». Este bloco único é o que o ChatGPT, o Perplexity e o Google AIO levantam com mais frequência, muitas vezes quase à letra. Lidera com a resposta; explica depois.
2. Anexa uma estatística atribuída a cada afirmação importante. «Segundo [fonte, data], X é Y%.» Isto faz duas coisas ao mesmo tempo: satisfaz a tática de Adição de Estatísticas do GEO, e dá ao modelo um átomo autónomo e defensável que pode citar sem risco. As afirmações vagas («muitos especialistas acreditam») são o oposto — incitáveis.
3. Divide as secções longas em passagens autónomas de 200–500 palavras. Os benchmarks de recuperação da NVIDIA encontraram que a fragmentação ao nível da página atingiu 0,648 de precisão com a menor variância.[9] Cada passagem deve definir a entidade, responder a uma pergunta e levar a sua estatística de apoio — porque o modelo pode ver essa passagem em completo isolamento do resto da tua página.
Dados originais: a alavanca mais forte
Se és a origem de um número, és a citação natural para esse número. Nada mais compõe como isto.
A tática individual mais bem respaldada em toda a literatura é publicar dados originais e proprietários. O mecanismo é simples: quando executas um inquérito, publicas um benchmark ou lanças um estudo, tornas-te a origem de uma estatística. Cada modelo que queira usar esse número tem exatamente um lugar a quem atribuí-lo — a ti. Uma estatística proprietária é o «átomo citável» que os motores de resposta levantam à letra, e ao contrário de um parágrafo bem escrito, nenhum concorrente o pode simplesmente reescrever melhor.
Aqui é também onde os dados são mais contundentes sobre o que não funciona. O estudo de 17.551 citações da SolCrys sobre a categoria de guias de compra AEO encontrou que as páginas «.com» próprias dos fornecedores representavam apenas 0,85% de todas as citações combinadas — enquanto Wikipedia, TechRadar e Reddit dominavam.[10] Até a SolCrys, a própria editora do estudo, foi citada a apenas 4,82% de taxa de menção de categoria.
O que prevê realmente uma citação de IA (e o que não)
A presença de marca supera os backlinks; a tua própria página de vendas mal regista[9][10]
O volume de pesquisa da marca correlaciona-se com as citações LLM a 0,334 — mais alto do que qualquer métrica de links (The Digital Bloom). Entretanto, as páginas autopromocionais próprias do fornecedor são 0,85% das citações (SolCrys). A conclusão: uma menção editorial de terceiros ou um tópico do Reddit sobre ti é muito mais citável do que a tua própria página de «somos os melhores».
A jogada de dados originais para uma equipa pequena
Menções de marca e presença off-site
A correlação mais forte nos dados não está de todo no teu site. Está em todo o lado menos aí.
Como ~60% das respostas do ChatGPT vêm da memória paramétrica, a alavanca de citações mais forte é muitas vezes invisível na tua própria analítica: com que frequência, e com que consistência, a tua marca aparece pela web aberta. A síntese da The Digital Bloom encontrou que o volume de pesquisa da marca é o preditor #1 de citações LLM com uma correlação de 0,334 — mais alto do que qualquer métrica de backlinks — e que os sites presentes em 4+ plataformas têm 2,8× mais probabilidades de aparecer em respostas do ChatGPT.[9]
A evidência ao nível da plataforma é igualmente direta. A Wikipedia compõe aproximadamente 22% dos dados de treino dos grandes LLM, razão pela qual uma entidade com uma página de Wikipedia é estruturalmente muito mais provável de ser recordada do que uma idêntica sem ela. Uma análise de junho de 2025 de mais de 150.000 citações encontrou o Reddit citado em 40,1% dos casos no ChatGPT, Perplexity, Gemini e Claude.[9] Estes são os lugares que os modelos realmente leem.
Para um site pequeno, a versão acionável é estreita e exequível:
- Sê consistente. Mesmo nome de marca, mesma descrição de uma linha, mesma categoria em todo o lado — o teu site, LinkedIn, Crunchbase, G2, o teu perfil de Reddit. Dados de entidade inconsistentes enfraquecem a representação neuronal que impulsiona o recall.
- Ganha menções genuínas de terceiros. Uma só recensão editorial ao estilo TechRadar ou um tópico real do Reddit sobre ti é mais citável do que uma dúzia de páginas no teu próprio domínio.
- Aparece onde o motor do teu vertical cita. Para B2B costuma ser LinkedIn + Reddit; para consumo/lifestyle é YouTube + Reddit. Participação real e útil — não drops promocionais.
- Procura uma presença honesta na Wikipedia se (e só se) cumprires as diretrizes de notabilidade. Molda desproporcionalmente o recall paramétrico.
Schema e llms.txt: o que é real em 2026
Dois dos 'hacks de citações de IA' mais sobrevendidos. Eis o que as fontes primárias realmente dizem.
Os dados estruturados ainda importam — mas como sinal de confiança e parsing, não como gatilho garantido de citações. O AI Mode potenciado pelo Gemini trata o schema como uma forma de entender e confiar no teu conteúdo, não como uma alavanca de exibição. Usa JSON-LD, e aplica apenas schema que genuinamente corresponda à página. A armadilha em 2026 é que vários tipos de schema foram retirados em silêncio, por isso construir uma estratégia sobre eles é esforço desperdiçado.
| Tipo de schema | Estado 2026 | O que precisas de saber |
|---|---|---|
| Article / BlogPosting | Usar | Espinha dorsal estrutural. A doc do Google de 10-12-2025 indica que NÃO há propriedades obrigatórias — mantém simples e preciso. Usa JSON-LD. |
| Organization | Usar | Reforça a identidade da entidade e os links sameAs — alimenta a clareza de entidade que melhora o recall. |
| Product / LocalBusiness | Usar | Adapta o schema apenas à página. O AI Mode potenciado pelo Gemini trata o schema como sinal de confiança, não como gatilho de exibição. |
| FAQPage | Cuidado | Os rich results de FAQ foram retirados da Google Search a 7 de maio de 2026 (só sites gov/saúde). Ainda ajuda um parser a ler a estrutura de Q&A — mas não esperes um rich result. |
| HowTo | Obsoleto | Rich results removidos para a maioria dos sites na limpeza de 2025. |
| ClaimReview / SpecialAnnouncement / VehicleListing + 4 mais | Obsoleto | Entre os 7 tipos de dados estruturados que o Google tornou obsoletos em jun/nov 2025. Não construas uma estratégia sobre estes. |
A mudança de destaque: segundo a própria documentação de FAQPage do Google, os rich results de FAQ deixaram de aparecer na Google Search a 7 de maio de 2026, sobrevivendo só para sites autoritativos governamentais e de saúde.[6] Os rich results de HowTo foram removidos para a maioria dos sites na limpeza de 2025, e o Google tornou obsoletos sete tipos de dados estruturados entre junho e novembro de 2025.[12] A marcação FAQPage e HowTo ainda pode ajudar um parser a entender a tua estrutura de Q&A — mas não esperes um rich result nem o trates como garantia de citação. (Para o JSON-LD que deves mesmo enviar, vê o nosso guia de schema markup para pequenas empresas.)
Gary Illyes (Google), Search Central Live, julho de 2025: o Google NÃO suporta llms.txt e não tem planos para o fazer.
John Mueller comparou publicamente o llms.txt à obsoleta meta tag keywords — ignorada há mais de uma década.
Dezembro de 2025: um ficheiro llms.txt apareceu brevemente na própria doc de programadores do Google; questionado no Bluesky se era um apoio, Mueller respondeu 'para ser direto, não'. A equipa de Search removeu-o.
Nenhum motor de resposta importante confirmou usar llms.txt para ranking ou citações. É um padrão proposto que alguns sites com muita documentação publicam.
Veredito honesto: baixo custo, pouca evidência. 'Provavelmente não faz mal', mas NÃO é uma alavanca de citações. Não lhe dediques tempo real.
Não desperdices um sprint no llms.txt
A checklist realista de citações
Tudo o anterior, sequenciado no que uma pessoa sem orçamento consegue mesmo enviar.
A pesquisa é exaustiva; o teu tempo não. Eis a ordem em que os sites de uma só pessoa estão mesmo a enviar em 2026, carregada à frente com os movimentos de maior alavancagem e menor esforço.
| Fase | Tempo | O que estás a fazer |
|---|---|---|
| 1. Estrutura | Semana 1 | Reescreve as tuas 5 melhores introduções como respostas diretas de 40–60 palavras sob H2 com a pergunta exata. Anexa uma estatística atribuída a cada afirmação-chave. Divide as secções longas em passagens autónomas de 200–500 palavras. |
| 2. Schema | Semana 1 | Envia JSON-LD de Article + Organization + Author em todo o site. Mantém-no preciso e adaptado a cada página. Salta o llms.txt. Não construas sobre os rich results de FAQPage/HowTo. |
| 3. Cobertura de fan-out | Semanas 2–4 | Para cada tema prioritário, adiciona passagens adjacentes que respondam às próximas perguntas lógicas. É assim que ganhas os 14–52% das citações que evitam o top-10. |
| 4. Dados originais | Mês 2 | Publica uma peça de pesquisa de primeira mão — um inquérito de 200 respostas, uma análise de 50 exemplos, um benchmark defensável — com um parágrafo de metodologia. Torna-te a origem de um número. |
| 5. Presença de marca | Meses 2–3 | Torna os dados de entidade consistentes em todo o lado. Ganha menções genuínas de terceiros. Participa a sério nas 2 plataformas que os motores do teu vertical mais citam (normalmente Reddit + LinkedIn ou YouTube). |
| 6. Cadência | Contínuo | Publica de forma constante. Conteúdo fresco e consistentemente estruturado mantém-te na mistura rotativa de fontes (40–60% das fontes citadas muda mês a mês). O silêncio custa citações. |
Onde a News Factory encaixa
Quem quer que mantenha o teu volante editorial a girar — tu, um freelancer ou um sistema assistido por IA como a News Factory — a estratégia mantém-se. As citações não vão para a página de vendas mais barulhenta. Vão para a fonte que respondeu à pergunta exata, com um número atribuível, numa passagem que um sistema de recuperação poderia levantar por si só. Constrói isso, de forma consistente, nos lugares que os modelos realmente leem.
→ Faz isto agora: Escolhe três páginas. Reescreve cada introdução como uma resposta direta de 40–60 palavras sob um H2 com a pergunta exata, anexa uma estatística atribuída à afirmação central de cada uma, e adiciona schema de Article + Author. É o trabalho desta noite — e põe-te à frente de quase todos os sites pequenos que ainda otimizam só para links azuis.
Leitura relacionada
- AEO vs SEO em 2026: Por Que os Motores de Resposta São a Nova Pesquisa — o enquadramento estratégico dentro do qual este guia encaixa.
- Visões Gerais de IA & SGE: Como Pequenos Sites Ainda Podem Ganhar Cliques em 2026 — o relatório de danos do Google AIO e o carve-out de consultas comparativas.
- Schema Markup para Pequenas Empresas — os blocos JSON-LD para enviar em 30 minutos.
- Autoridade Temática: Por Que Publicar Mais (Bom) Conteúdo Ganha em SEO — o problema de cadência e cobertura de fan-out em profundidade.
Referências e Fontes
Sobre os números do top-10: os estudos diferem por metodologia (conjunto completo de citações vs. só citações que se sobrepõem ao top-100; janelas de datas distintas; os AI Overviews mudam depressa). A leitura honesta é um intervalo (38–76%) e uma direção, não um número único e assente.